SiLVR: A Simple Language-based Video Reasoning Framework
作者: Ce Zhang, Yan-Bo Lin, Ziyang Wang, Mohit Bansal, Gedas Bertasius
分类: cs.CV
发布日期: 2025-05-30 (更新: 2026-01-18)
备注: Accepted by TMLR (01/2026)
💡 一句话要点
提出SiLVR框架,利用语言模型增强视频理解推理能力,无需额外训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频理解 语言模型 多模态学习 视频推理 长视频处理
📋 核心要点
- 多模态大型语言模型在视频理解推理方面存在不足,尤其是在处理复杂任务时。
- SiLVR框架通过将视频转换为语言表示,并利用大型语言模型的推理能力来解决视频理解问题。
- SiLVR在多个视频理解数据集上取得了领先的结果,证明了其有效性,且无需额外训练。
📝 摘要(中文)
本文提出了一种简单的基于语言的视频推理框架SiLVR,旨在提升多模态大型语言模型(MLLM)在复杂视频语言任务中的推理能力。SiLVR将复杂的视频理解分解为两个阶段:首先,利用多感官输入(如短视频片段字幕和音频/语音字幕)将原始视频转换为基于语言的表示;然后,将这些语言描述输入到强大的推理LLM中,以解决复杂的视频语言理解任务。为了处理长上下文的多感官输入,本文采用了一种自适应上下文缩减方案,该方案动态地确定采样token的时间粒度。该框架在Video-MME (long)、Video-MMMU (comprehension)、Video-MMLU、CGBench和EgoLife等数据集上取得了最佳结果。实验表明,即使没有经过专门的视频训练,强大的推理LLM也能有效地聚合来自视频、语音和音频的多感官输入信息,以完成复杂的时序、因果、长上下文和知识获取推理任务。
🔬 方法详解
问题定义:现有的多模态大型语言模型(MLLM)在处理复杂的视频语言任务时,推理能力显著不足。尤其是在需要长时间上下文理解、时序推理、因果关系判断以及知识获取的场景下,性能表现不佳。现有的方法难以有效地整合视频中的多模态信息(视觉、听觉、语音),并进行深入的推理。
核心思路:SiLVR的核心思路是将视频理解问题转化为语言推理问题。通过将原始视频信息转换为语言描述,例如视频片段的字幕、音频的转录等,利用大型语言模型(LLM)强大的语言推理能力来解决视频理解任务。这种方法避免了直接在视频数据上进行复杂推理,而是将问题简化为LLM擅长的语言领域。
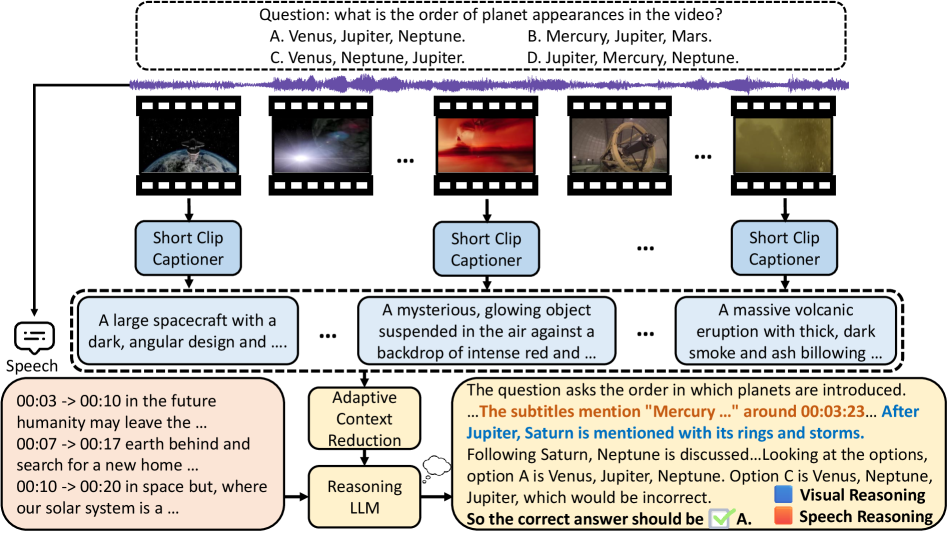
技术框架:SiLVR框架主要包含两个阶段:1) 视频到语言的转换:利用多感官输入(视频片段字幕、音频/语音字幕)将原始视频转换为语言描述。可以使用现成的模型或工具来提取这些信息。2) 语言推理:将第一阶段生成的语言描述输入到大型语言模型(LLM)中,利用LLM的推理能力来解决特定的视频语言理解任务。为了处理长上下文输入,采用了自适应上下文缩减方案,动态调整采样的时间粒度。
关键创新:SiLVR的关键创新在于其简单性和有效性。它没有引入复杂的视频处理模块或训练过程,而是充分利用了现有的大型语言模型的推理能力。自适应上下文缩减方案是另一个创新点,它能够有效地处理长视频带来的长上下文问题,提高推理效率。
关键设计:自适应上下文缩减方案是SiLVR的关键设计之一。该方案根据视频内容的复杂度和推理任务的需求,动态地调整采样的时间粒度。例如,对于变化缓慢的场景,可以采用较粗的时间粒度进行采样,而对于变化剧烈的场景,则需要采用更细的时间粒度进行采样。具体的实现方式可能包括基于注意力机制的采样策略,或者基于信息熵的采样策略。此外,如何选择合适的LLM以及如何设计合适的prompt也是重要的技术细节。
🖼️ 关键图片
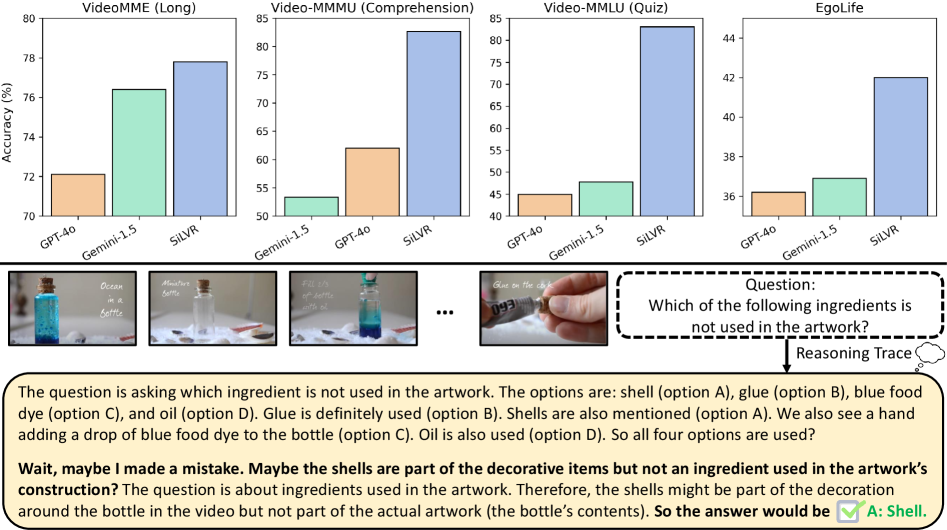
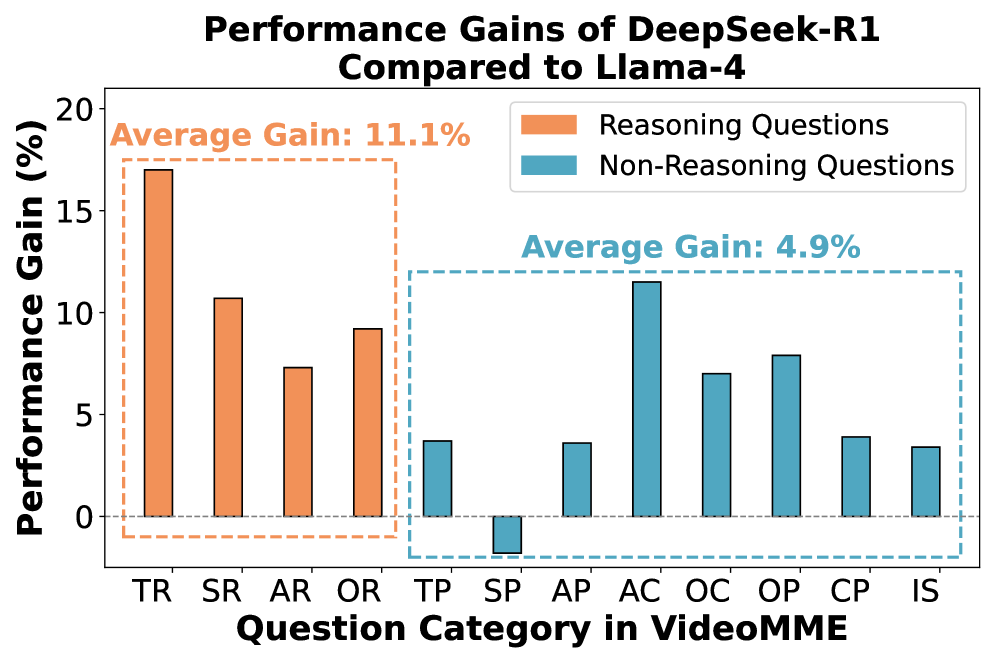
📊 实验亮点
SiLVR在多个视频理解数据集上取得了最佳结果,包括Video-MME (long)、Video-MMMU (comprehension)、Video-MMLU、CGBench和EgoLife。例如,在Video-MME (long)数据集上,SiLVR的性能超过了之前的最佳方法。值得注意的是,SiLVR在没有经过专门视频训练的情况下,依然能够取得如此优异的成绩,这充分证明了大型语言模型在视频理解方面的潜力。
🎯 应用场景
SiLVR框架具有广泛的应用前景,例如视频内容理解、智能监控、自动驾驶、视频搜索和推荐等。它可以帮助机器更好地理解视频内容,从而实现更智能化的视频分析和处理。例如,在智能监控中,SiLVR可以用于识别异常事件;在自动驾驶中,可以用于理解交通场景;在视频搜索和推荐中,可以用于提高搜索和推荐的准确性。
📄 摘要(原文)
Recent advances in test-time optimization have led to remarkable reasoning capabilities in Large Language Models (LLMs), enabling them to solve highly complex problems in math and coding. However, the reasoning capabilities of multimodal LLMs (MLLMs) still significantly lag, especially for complex video-language tasks. To address this issue, we present SILVR, a Simple Language-based Video Reasoning framework that decomposes complex video understanding into two stages. In the first stage, SILVR transforms raw video into language-based representations using multisensory inputs, such as short clip captions and audio/speech subtitles. In the second stage, language descriptions are fed into a powerful reasoning LLM to solve complex video-language understanding tasks. To handle long-context multisensory inputs, we use an Adaptive Context Reduction scheme, which dynamically determines the temporal granularity with which to sample the tokens. Our simple, modular, and training-free video reasoning framework achieves the best-reported results on Video-MME (long), Video-MMMU (comprehension), Video-MMLU, CGBench, and EgoLife. Furthermore, our empirical study focused on video reasoning capabilities shows that, despite not being explicitly trained on video, strong reasoning LLMs can effectively aggregate multisensory input information from video, speech, and audio for complex temporal, causal, long-context, and knowledge acquisition reasoning tasks in video. More details can be found at https://sites.google.com/cs.unc.edu/silvr.