VideoCAD: A Dataset and Model for Learning Long-Horizon 3D CAD UI Interactions from Video
作者: Brandon Man, Ghadi Nehme, Md Ferdous Alam, Faez Ahmed
分类: cs.CV, cs.AI
发布日期: 2025-05-30 (更新: 2025-11-08)
💡 一句话要点
提出VideoCAD数据集和VideoCADFormer模型,用于学习长时程3D CAD UI交互。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: CAD交互 UI交互 视频理解 长时程建模 数据集 视觉问答 行为克隆 3D建模
📋 核心要点
- 现有UI交互数据集主要集中于移动或Web应用,无法满足专业工程领域CAD软件的复杂性和长时程需求。
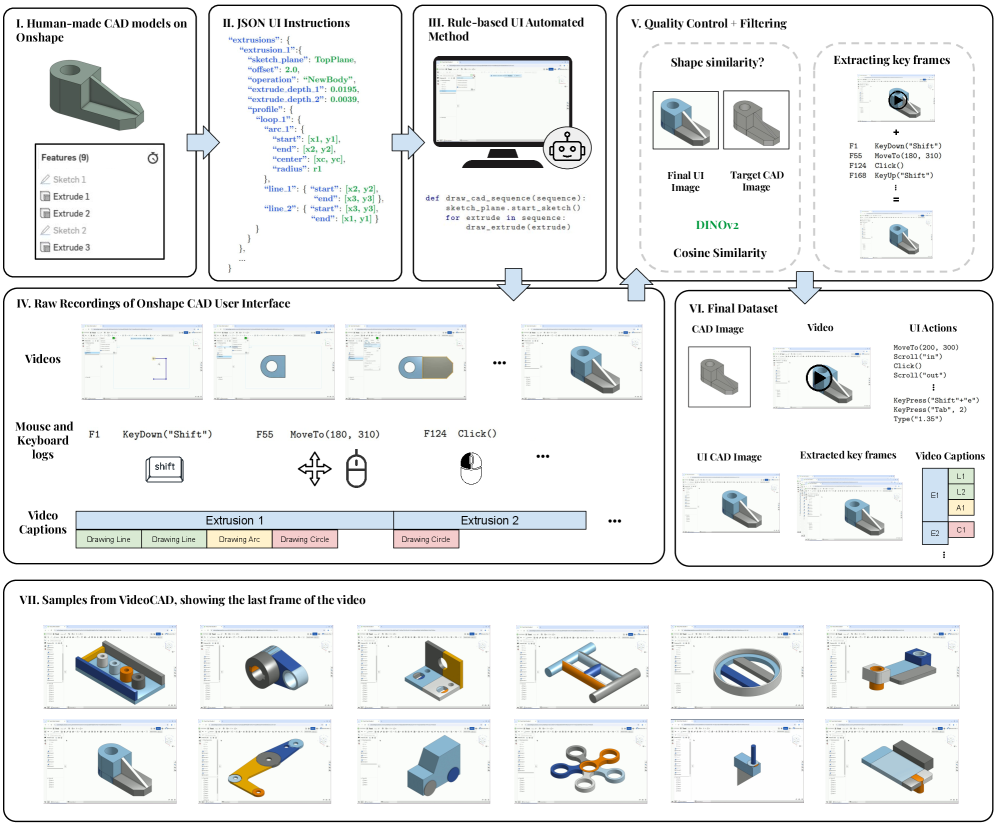
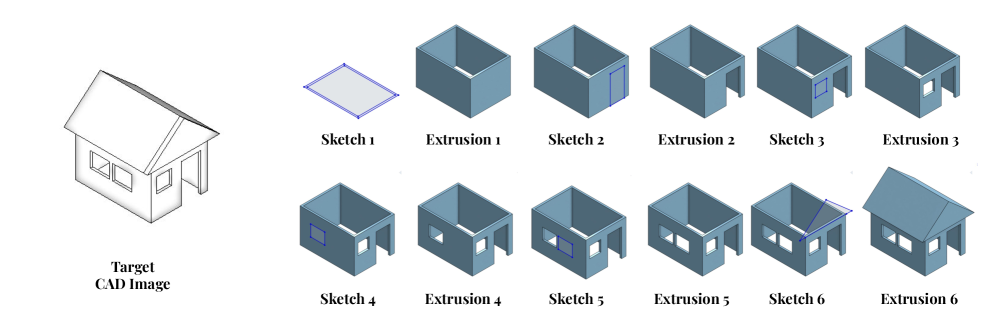
- 论文提出VideoCAD数据集和VideoCADFormer模型,通过自动化框架生成大规模CAD操作视频,并学习UI交互。
- 实验表明,VideoCADFormer在学习CAD交互方面优于现有行为克隆基线,并揭示了视频UI理解的关键挑战。
📝 摘要(中文)
计算机辅助设计(CAD)是一个耗时且复杂的过程,需要用户与复杂的3D界面进行精确的、长时程的交互。虽然人工智能驱动的用户界面(UI)代理取得了进展,但现有数据集和方法主要集中在移动或Web应用程序中的短期、低复杂性任务,无法满足专业工程工具的需求。本文提出了VideoCAD,首次尝试对精确工程任务的UI交互进行建模。VideoCAD是一个大规模合成数据集,包含超过4.1万个CAD操作的带注释视频记录,这些记录是使用自动化框架从人工CAD设计中收集高保真UI动作数据生成的。与现有数据集相比,VideoCAD在实际工程UI任务的复杂性方面提高了数量级,时间跨度比其他数据集长达20倍。展示了VideoCAD的两个重要下游应用:(1)从专业3D CAD工具中学习UI交互以用于精确任务;(2)一个视觉问答(VQA)基准,旨在评估多模态大型语言模型(LLM)在空间推理和视频理解方面的能力。为了学习UI交互,提出了VideoCADFormer,这是一个用于直接从视频中学习CAD交互的先进模型,其性能优于现有的行为克隆基线。VideoCADFormer和源自VideoCAD的VQA基准都揭示了当前基于视频的UI理解的关键挑战,包括精确的动作定位、多模态和空间推理以及长时程依赖关系。
🔬 方法详解
问题定义:论文旨在解决现有UI交互数据集无法满足专业CAD软件复杂性和长时程交互需求的问题。现有方法在处理精确动作定位、多模态空间推理和长时程依赖关系方面存在不足,限制了AI在CAD领域的应用。
核心思路:论文的核心思路是构建一个大规模、高保真的CAD操作视频数据集VideoCAD,并设计一个专门的模型VideoCADFormer来学习这些视频中的UI交互。通过合成数据的方式,可以有效地解决真实CAD数据难以获取和标注的问题。
技术框架:整体框架包含两个主要部分:VideoCAD数据集的生成和VideoCADFormer模型的训练。VideoCAD数据集通过自动化脚本从人工CAD设计中生成带注释的视频记录。VideoCADFormer模型则利用这些视频数据学习CAD软件的UI交互。VQA基准测试用于评估模型的空间推理和视频理解能力。
关键创新:最重要的技术创新点在于VideoCAD数据集的构建和VideoCADFormer模型的提出。VideoCAD是首个针对CAD UI交互的大规模数据集,其复杂性和时间跨度远超现有数据集。VideoCADFormer模型专门设计用于从视频中学习CAD交互,并取得了优于现有基线的性能。
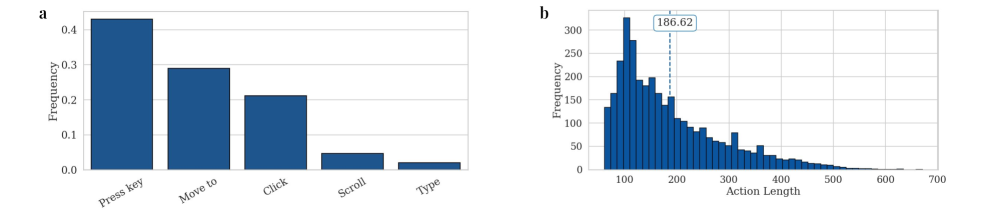
关键设计:VideoCAD数据集包含超过4.1万个带注释的视频记录,涵盖各种CAD操作。VideoCADFormer模型的具体网络结构和损失函数细节未知,但其目标是从视频中学习精确的动作定位、多模态空间推理和长时程依赖关系。
🖼️ 关键图片
📊 实验亮点
VideoCADFormer模型在学习CAD交互方面优于现有的行为克隆基线,证明了该方法的可行性。VideoCAD数据集的规模和复杂性远超现有数据集,为CAD领域的UI交互研究提供了新的基准。VQA基准测试揭示了当前视频UI理解在精确动作定位、多模态空间推理和长时程依赖关系方面的挑战。
🎯 应用场景
该研究成果可应用于自动化CAD设计、智能CAD助手、CAD软件教学等领域。通过学习人类的CAD操作,AI可以辅助工程师完成重复性工作,提高设计效率,降低学习门槛。未来,该技术有望实现完全自动化的CAD设计,推动工程领域的智能化发展。
📄 摘要(原文)
Computer-Aided Design (CAD) is a time-consuming and complex process, requiring precise, long-horizon user interactions with intricate 3D interfaces. While recent advances in AI-driven user interface (UI) agents show promise, most existing datasets and methods focus on short, low-complexity tasks in mobile or web applications, failing to capture the demands of professional engineering tools. In this work, we introduce VideoCAD, the first attempt to model UI interactions for precision engineering tasks. Specifically, VideoCAD is a large-scale synthetic dataset consisting of over 41K annotated video recordings of CAD operations, generated using an automated framework for collecting high-fidelity UI action data from human-made CAD designs. Compared to existing datasets, VideoCAD offers an order-of-magnitude increase in complexity for real-world engineering UI tasks, with time horizons up to 20x longer than those in other datasets. We show two important downstream applications of VideoCAD: (1) learning UI interactions from professional 3D CAD tools for precision tasks and (2) a visual question-answering (VQA) benchmark designed to evaluate multimodal large language models (LLMs) on spatial reasoning and video understanding. To learn the UI interactions, we propose VideoCADFormer, a state-of-the-art model for learning CAD interactions directly from video, which outperforms existing behavior cloning baselines. Both VideoCADFormer and the VQA benchmark derived from VideoCAD reveal key challenges in the current state of video-based UI understanding, including the need for precise action grounding, multi-modal and spatial reasoning, and long-horizon dependencies.