Tackling View-Dependent Semantics in 3D Language Gaussian Splatting
作者: Jiazhong Cen, Xudong Zhou, Jiemin Fang, Changsong Wen, Lingxi Xie, Xiaopeng Zhang, Wei Shen, Qi Tian
分类: cs.CV
发布日期: 2025-05-30
备注: ICML 2025 camera ready. Project Page: https://jumpat.github.io/laga-page/
🔗 代码/项目: GITHUB
💡 一句话要点
LaGa:通过建模视角依赖语义解决3D语言高斯溅射中的语义理解难题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D场景理解 视角依赖语义 高斯溅射 多视角学习 语义分割
📋 核心要点
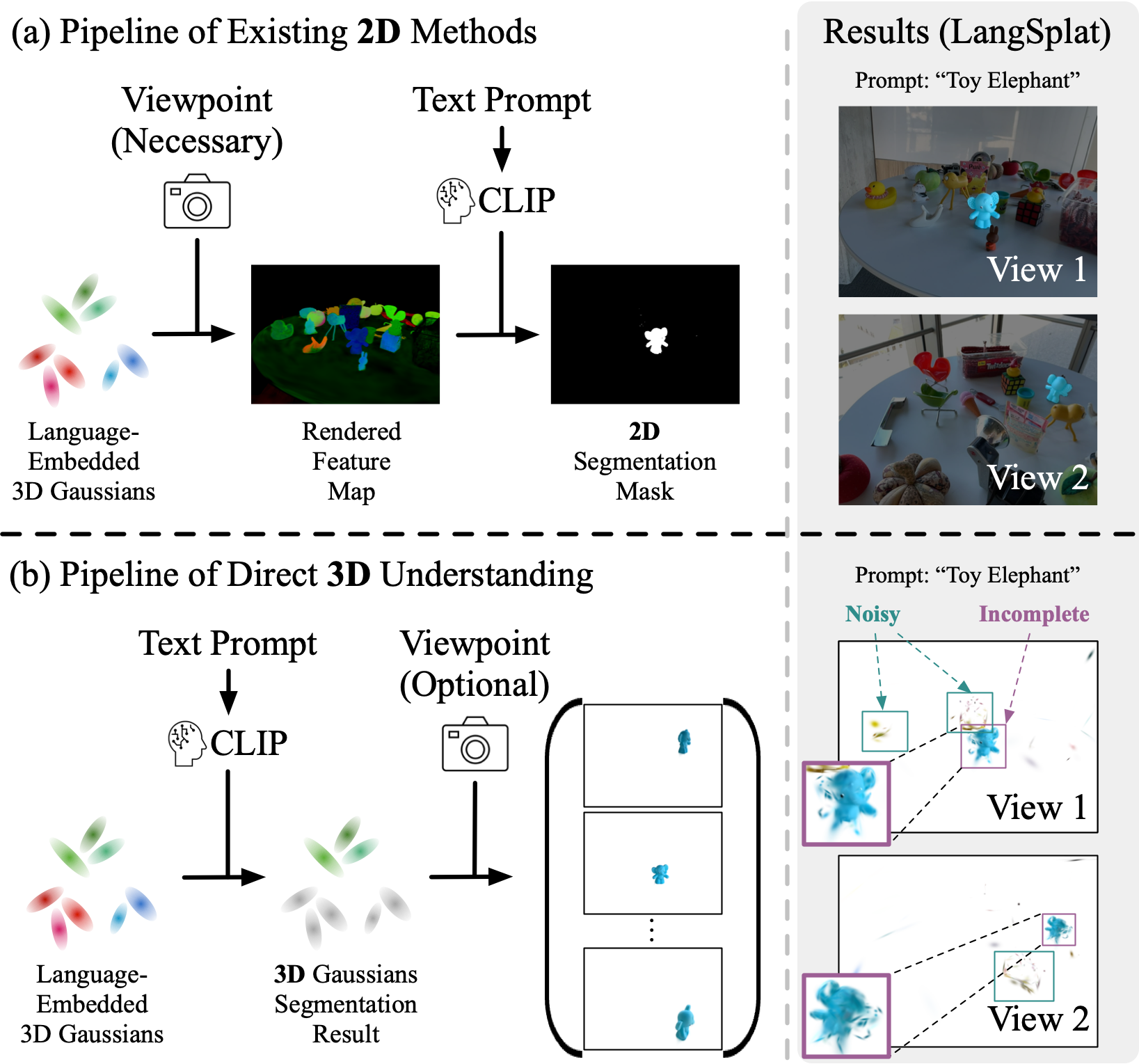
- 现有3D语言高斯溅射方法忽略了3D物体语义的视角依赖性,导致理解偏差。
- LaGa通过将3D场景分解为对象,并聚合多视角语义信息,建立跨视角语义连接。
- 实验表明,LaGa在3D场景理解方面显著优于现有技术,尤其是在视角依赖语义方面。
📝 摘要(中文)
本文提出了一种名为LaGa(Language Gaussians)的新方法,旨在解决3D语言高斯溅射中存在的视角依赖语义问题。现有方法通常简单地将2D语义特征投影到3D高斯上,忽略了2D和3D理解之间的根本差距,即3D对象从不同视角可能呈现出不同的语义。LaGa通过将3D场景分解为对象来建立跨视角语义连接,并通过聚类语义描述符并基于多视角语义重新加权来构建视角聚合的语义表示。大量实验表明,LaGa能够有效地捕捉视角依赖语义中的关键信息,从而实现对3D场景更全面的理解。在LERF-OVS数据集上,LaGa在相同设置下比之前的SOTA方法取得了显著的+18.7% mIoU的提升。
🔬 方法详解
问题定义:现有基于3D高斯溅射的语言驱动场景理解方法,直接将2D图像的语义信息投影到3D高斯模型中,忽略了3D物体在不同视角下可能具有不同的语义信息。这种视角依赖性导致模型无法准确理解3D场景的真实语义,限制了其在复杂场景中的应用。
核心思路:LaGa的核心思路是显式地建模3D物体的视角依赖语义。通过将3D场景分解为独立的物体,并为每个物体学习一个视角聚合的语义表示,从而使模型能够理解物体在不同视角下的语义变化。这种方法能够更全面地捕捉3D场景的语义信息,提高场景理解的准确性。
技术框架:LaGa的整体框架包括以下几个主要步骤:1) 3D场景分解:将3D场景分解为多个独立的物体。2) 语义描述符提取:从不同视角的图像中提取每个物体的语义描述符。3) 语义描述符聚类:将来自不同视角的语义描述符聚类,形成视角相关的语义簇。4) 语义重加权:根据多视角语义信息,对每个语义簇进行重加权,得到视角聚合的语义表示。5) 场景理解:利用视角聚合的语义表示进行3D场景理解。
关键创新:LaGa的关键创新在于其显式地建模了3D物体的视角依赖语义。与现有方法不同,LaGa不是简单地将2D语义信息投影到3D空间,而是通过学习视角聚合的语义表示来捕捉物体在不同视角下的语义变化。这种方法能够更准确地理解3D场景的语义信息,提高了场景理解的性能。
关键设计:LaGa的关键设计包括:1) 物体分解策略:采用基于几何和语义信息的物体分解方法,确保分解后的物体具有语义一致性。2) 语义描述符选择:选择具有代表性的语义描述符,例如CLIP特征,以捕捉物体的语义信息。3) 聚类算法:采用K-means等聚类算法,将来自不同视角的语义描述符聚类。4) 重加权策略:根据视角之间的相似度,对语义簇进行重加权,得到视角聚合的语义表示。损失函数的设计旨在鼓励模型学习到具有区分性的视角聚合语义表示。
🖼️ 关键图片


📊 实验亮点
LaGa在LERF-OVS数据集上取得了显著的性能提升,mIoU指标比之前的SOTA方法提高了18.7%。这一结果表明,LaGa能够有效地捕捉视角依赖语义,从而实现对3D场景更全面的理解。此外,实验还表明,LaGa在处理复杂场景和遮挡场景时具有更强的鲁棒性。
🎯 应用场景
LaGa在3D场景理解方面具有广泛的应用前景,例如:机器人导航、自动驾驶、虚拟现实、增强现实等。它可以帮助机器人更好地理解周围环境,从而实现更智能的导航和交互。在自动驾驶领域,LaGa可以提高车辆对复杂场景的理解能力,从而提高驾驶安全性。在虚拟现实和增强现实领域,LaGa可以提供更逼真的3D场景体验。
📄 摘要(原文)
Recent advancements in 3D Gaussian Splatting (3D-GS) enable high-quality 3D scene reconstruction from RGB images. Many studies extend this paradigm for language-driven open-vocabulary scene understanding. However, most of them simply project 2D semantic features onto 3D Gaussians and overlook a fundamental gap between 2D and 3D understanding: a 3D object may exhibit various semantics from different viewpoints--a phenomenon we term view-dependent semantics. To address this challenge, we propose LaGa (Language Gaussians), which establishes cross-view semantic connections by decomposing the 3D scene into objects. Then, it constructs view-aggregated semantic representations by clustering semantic descriptors and reweighting them based on multi-view semantics. Extensive experiments demonstrate that LaGa effectively captures key information from view-dependent semantics, enabling a more comprehensive understanding of 3D scenes. Notably, under the same settings, LaGa achieves a significant improvement of +18.7% mIoU over the previous SOTA on the LERF-OVS dataset. Our code is available at: https://github.com/SJTU-DeepVisionLab/LaGa.