Learning from Videos for 3D World: Enhancing MLLMs with 3D Vision Geometry Priors
作者: Duo Zheng, Shijia Huang, Yanyang Li, Liwei Wang
分类: cs.CV, cs.AI
发布日期: 2025-05-30 (更新: 2025-10-22)
备注: Accepted by NeurIPS 2025
💡 一句话要点
提出VG LLM,利用视频中的3D几何先验增强MLLM的3D场景理解能力
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 3D场景理解 视频理解 几何先验 空间推理
📋 核心要点
- 现有方法依赖于点云或BEV地图等全面的3D数据输入,限制了MLLM在3D场景理解中的应用。
- VG LLM通过3D视觉几何编码器从视频中提取3D先验信息,并将其融入MLLM,实现直接从视频理解3D场景。
- 实验表明,VG LLM在3D场景理解和空间推理任务上取得了显著提升,4B模型性能甚至超越Gemini-1.5-Pro。
📝 摘要(中文)
本文提出了一种新颖且高效的方法,即视频-3D几何大语言模型(VG LLM),旨在提升多模态大语言模型(MLLM)直接从视频数据中理解和推理3D空间的能力,而无需额外的3D输入。该方法利用3D视觉几何编码器从视频序列中提取3D先验信息,然后将这些信息与视觉tokens集成并输入到MLLM中。大量实验表明,该方法在各种与3D场景理解和空间推理相关的任务中取得了显著的改进,所有这些都直接从视频源中学习得到。值得注意的是,该4B模型不依赖于显式的3D数据输入,其性能与现有的最先进方法相比具有竞争力,甚至在VSI-Bench评估中超过了Gemini-1.5-Pro。
🔬 方法详解
问题定义:现有方法在利用多模态大语言模型理解3D场景时,通常需要额外的3D数据输入,例如点云或重建的鸟瞰图(BEV)地图。这些方法增加了数据获取和处理的复杂性,限制了MLLM在仅有视频数据情况下的3D场景理解能力。因此,如何让MLLM直接从视频中学习并理解3D场景成为一个关键问题。
核心思路:本文的核心思路是从视频序列中提取3D几何先验信息,并将其融入到MLLM中,从而增强MLLM的3D空间理解和推理能力。通过这种方式,模型可以利用视频中的运动信息和视角变化来推断3D结构,而无需显式的3D数据输入。
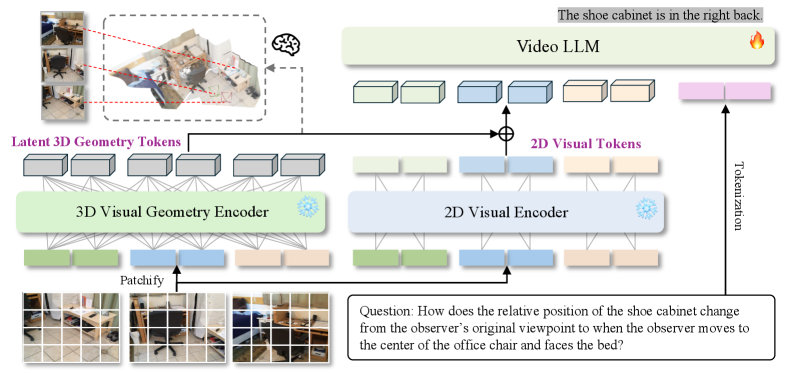
技术框架:VG LLM的整体框架包括以下几个主要模块:1) 视频输入模块:接收视频序列作为输入。2) 3D视觉几何编码器:从视频序列中提取3D几何先验信息,例如深度、视差等。3) 特征融合模块:将提取的3D几何先验信息与视觉tokens进行融合。4) MLLM:接收融合后的特征作为输入,进行3D场景理解和空间推理。
关键创新:该方法最重要的创新点在于利用3D视觉几何编码器从视频中提取3D先验信息,并将其融入到MLLM中。与现有方法相比,该方法无需额外的3D数据输入,可以直接从视频中学习3D场景的结构和关系。这种方法更加高效和灵活,可以应用于各种场景,例如自动驾驶、机器人导航等。
关键设计:关于3D视觉几何编码器的具体设计细节,论文中可能涉及以下方面:1) 网络结构:例如使用Transformer或CNN等。2) 损失函数:例如使用深度预测损失、视差预测损失等。3) 训练策略:例如使用自监督学习或弱监督学习等。这些设计细节旨在提高3D几何先验信息的提取精度和鲁棒性。具体参数设置和网络结构细节需要参考论文原文。
🖼️ 关键图片


📊 实验亮点
VG LLM在多个3D场景理解和空间推理任务上取得了显著的改进。特别是在VSI-Bench评估中,不依赖显式3D数据输入的4B模型,其性能与现有的最先进方法相比具有竞争力,甚至超过了Gemini-1.5-Pro。这些结果表明,该方法能够有效地从视频中学习3D几何信息,并将其应用于各种3D场景理解任务。
🎯 应用场景
该研究成果具有广泛的应用前景,例如自动驾驶、机器人导航、虚拟现实和增强现实等领域。在自动驾驶中,该方法可以帮助车辆更好地理解周围环境的3D结构,从而提高驾驶安全性。在机器人导航中,该方法可以帮助机器人更好地规划路径,避免障碍物。在VR/AR中,该方法可以帮助用户更真实地体验虚拟环境。
📄 摘要(原文)
Previous research has investigated the application of Multimodal Large Language Models (MLLMs) in understanding 3D scenes by interpreting them as videos. These approaches generally depend on comprehensive 3D data inputs, such as point clouds or reconstructed Bird's-Eye View (BEV) maps. In our research, we advance this field by enhancing the capability of MLLMs to understand and reason in 3D spaces directly from video data, without the need for additional 3D input. We propose a novel and efficient method called the Video-3D Geometry Large Language Model (VG LLM). Our approach utilizes a 3D visual geometry encoder to extract 3D prior information from video sequences. This information is then integrated with visual tokens and input into the MLLM. Extensive experiments have shown that our method has achieved substantial improvements in various tasks related to 3D scene understanding and spatial reasoning, all directly learned from video sources. Impressively, our 4B model, which does not rely on explicit 3D data inputs, achieves competitive results compared to existing state-of-the-art methods, and even surpasses the Gemini-1.5-Pro in the VSI-Bench evaluations.