PCIE_Pose Solution for EgoExo4D Pose and Proficiency Estimation Challenge
作者: Feng Chen, Kanokphan Lertniphonphan, Qiancheng Yan, Xiaohui Fan, Jun Xie, Tao Zhang, Zhepeng Wang
分类: cs.CV
发布日期: 2025-05-30
💡 一句话要点
提出HP-ViT+模型,解决EgoExo4D挑战赛中手部和身体姿态估计及熟练度评估问题
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 手部姿态估计 身体姿态估计 熟练度估计 Vision Transformer 多模态融合
📋 核心要点
- 现有手部姿态估计方法难以处理第一人称视角视频中细微运动和频繁遮挡带来的挑战。
- 提出HP-ViT+模型,结合视觉Transformer和CNN,通过加权融合优化手部姿态预测,提升鲁棒性。
- 在EgoExo4D挑战赛中,手部姿态估计达到8.31 PA-MPJPE,身体姿态估计达到11.25 MPJPE,熟练度估计top-1准确率达0.53。
📝 摘要(中文)
本报告介绍了我们的团队(PCIE_EgoPose)在CVPR2025 EgoExo4D姿态和熟练度估计挑战赛中的解决方案。针对从RGB第一人称视角视频中估计21个3D手部关节这一复杂任务,该任务受到细微运动和频繁遮挡的影响,我们开发了手部姿态视觉Transformer (HP-ViT+)。该架构结合了视觉Transformer和CNN骨干网络,使用加权融合来优化手部姿态预测。对于EgoExo4D身体姿态挑战赛,我们采用了一种多模态时空特征集成策略,以应对动态环境中身体姿态估计的复杂性。我们的方法取得了显著的性能:在手部姿态挑战赛中达到8.31 PA-MPJPE,在身体姿态挑战赛中达到11.25 MPJPE,在两个比赛中均获得冠军。我们将姿态估计解决方案扩展到熟练度估计任务,应用了基于Transformer架构等核心技术。这种扩展使我们在演示者熟练度估计比赛中获得了0.53的top-1准确率,达到了SOTA水平。
🔬 方法详解
问题定义:论文旨在解决EgoExo4D挑战赛中的手部姿态估计、身体姿态估计和熟练度估计三个问题。现有方法在处理第一人称视角视频时,由于手部运动细微、遮挡频繁以及视角变化剧烈等因素,导致姿态估计精度较低。对于熟练度估计,现有方法难以有效提取视频中的关键特征,从而影响评估准确性。
核心思路:针对手部姿态估计,核心思路是结合Vision Transformer (ViT) 的全局建模能力和CNN的局部特征提取能力,通过加权融合两种网络的输出,从而更准确地预测手部姿态。对于身体姿态估计,采用多模态时空特征集成策略,利用不同模态的信息互补,提升姿态估计的鲁棒性。对于熟练度估计,则利用Transformer架构提取视频中的关键特征,从而更准确地评估演示者的熟练程度。
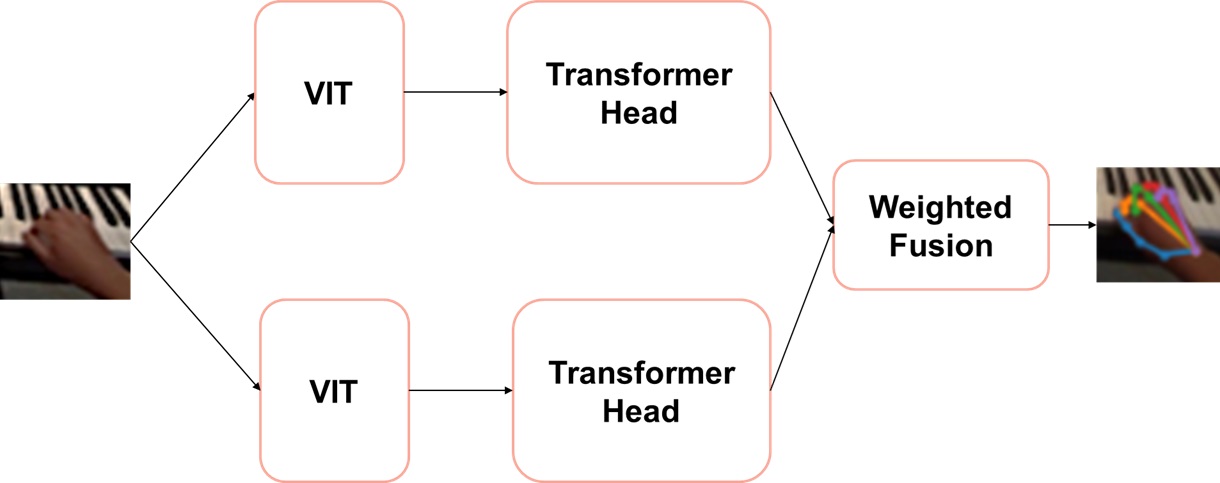
技术框架:手部姿态估计采用HP-ViT+架构,包含CNN骨干网络和Vision Transformer两部分。CNN负责提取局部特征,ViT负责捕捉全局依赖关系。通过加权融合模块将两者的输出进行融合,得到最终的手部姿态预测结果。身体姿态估计采用多模态时空特征集成框架,将RGB视频、深度信息等多种模态的信息进行融合,并利用时序模型捕捉人体运动的时序信息。熟练度估计则采用Transformer架构,将视频帧作为输入,通过自注意力机制提取关键特征,并进行熟练度分类。
关键创新:HP-ViT+模型是手部姿态估计的关键创新点,它有效地结合了CNN和ViT的优势,提升了手部姿态估计的精度和鲁棒性。多模态时空特征集成策略则提升了身体姿态估计在复杂环境下的性能。将Transformer应用于熟练度估计,能够有效提取视频中的关键信息,从而更准确地评估演示者的熟练程度。
关键设计:HP-ViT+模型中,加权融合模块的设计至关重要,它决定了CNN和ViT输出的权重分配。损失函数的设计也需要考虑手部姿态估计的特殊性,例如可以使用MPJPE (Mean Per Joint Position Error) 作为评价指标。在多模态时空特征集成中,如何有效地融合不同模态的信息是一个关键问题,可以采用注意力机制等方法。Transformer的层数、注意力头数等参数也需要根据具体任务进行调整。
🖼️ 关键图片

📊 实验亮点
该团队在EgoExo4D挑战赛中取得了显著成果:在手部姿态估计挑战赛中,使用HP-ViT+模型达到了8.31 PA-MPJPE,获得冠军;在身体姿态估计挑战赛中,达到了11.25 MPJPE,同样获得冠军;在演示者熟练度估计比赛中,获得了0.53的top-1准确率,达到了SOTA水平,充分验证了所提出方法的有效性。
🎯 应用场景
该研究成果可应用于人机交互、虚拟现实、医疗康复、运动分析等领域。例如,在虚拟现实中,可以利用手部姿态估计技术实现自然的手势交互;在医疗康复中,可以利用身体姿态估计技术评估患者的康复进度;在运动分析中,可以利用姿态估计技术分析运动员的动作,从而提高训练效果。
📄 摘要(原文)
This report introduces our team's (PCIE_EgoPose) solutions for the EgoExo4D Pose and Proficiency Estimation Challenges at CVPR2025. Focused on the intricate task of estimating 21 3D hand joints from RGB egocentric videos, which are complicated by subtle movements and frequent occlusions, we developed the Hand Pose Vision Transformer (HP-ViT+). This architecture synergizes a Vision Transformer and a CNN backbone, using weighted fusion to refine the hand pose predictions. For the EgoExo4D Body Pose Challenge, we adopted a multimodal spatio-temporal feature integration strategy to address the complexities of body pose estimation across dynamic contexts. Our methods achieved remarkable performance: 8.31 PA-MPJPE in the Hand Pose Challenge and 11.25 MPJPE in the Body Pose Challenge, securing championship titles in both competitions. We extended our pose estimation solutions to the Proficiency Estimation task, applying core technologies such as transformer-based architectures. This extension enabled us to achieve a top-1 accuracy of 0.53, a SOTA result, in the Demonstrator Proficiency Estimation competition.