Towards a Generalizable Bimanual Foundation Policy via Flow-based Video Prediction
作者: Chenyou Fan, Fangzheng Yan, Chenjia Bai, Jiepeng Wang, Chi Zhang, Zhen Wang, Xuelong Li
分类: cs.CV, cs.RO
发布日期: 2025-05-30
💡 一句话要点
提出基于光流视频预测的双臂机器人通用策略,提升泛化性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 双臂机器人 操作策略 视频预测 光流 文本到视频
📋 核心要点
- 现有双臂操作策略学习方法依赖单臂数据或预训练VLA模型,但因数据稀缺和单双臂差异导致泛化性差。
- 提出两阶段微调策略,利用光流作为中间表示,解耦文本理解和动作生成,降低对机器人数据的需求。
- 通过仿真和真实机器人实验验证,表明该方法能有效提升双臂操作策略的泛化能力。
📝 摘要(中文)
由于动作空间巨大以及需要协调的双臂运动,学习一种通用的双臂操作策略对于具身智能体来说极具挑战。现有方法依赖于视觉-语言-动作(VLA)模型来获取双臂策略。然而,从单臂数据集或预训练的VLA模型迁移知识通常无法有效地泛化,这主要是由于双臂数据的稀缺以及单臂和双臂操作之间的根本差异。本文提出了一种新的双臂基础策略,通过微调领先的文本到视频模型来预测机器人轨迹,并训练一个轻量级的扩散策略来生成动作。鉴于文本到视频模型中缺乏具身知识,我们引入了一个两阶段范式,该范式微调了从预训练的文本到视频模型派生的独立的文本到光流和光流到视频模型。具体来说,光流作为中间变量,提供了图像之间细微运动的简洁表示。文本到光流模型预测光流以具体化语言指令的意图,而光流到视频模型利用该光流进行细粒度的视频预测。我们的方法减轻了单阶段文本到视频预测中语言的歧义,并通过避免直接使用低级动作来显著降低机器人数据需求。在实验中,我们为真实的双臂机器人收集了高质量的操作数据,仿真和真实世界实验的结果证明了我们方法的有效性。
🔬 方法详解
问题定义:论文旨在解决双臂机器人操作策略泛化性差的问题。现有方法依赖单臂数据或预训练的VLA模型,但由于双臂数据稀缺以及单双臂操作的根本差异,导致策略难以泛化到新的任务和环境。直接使用低级动作也增加了数据需求。
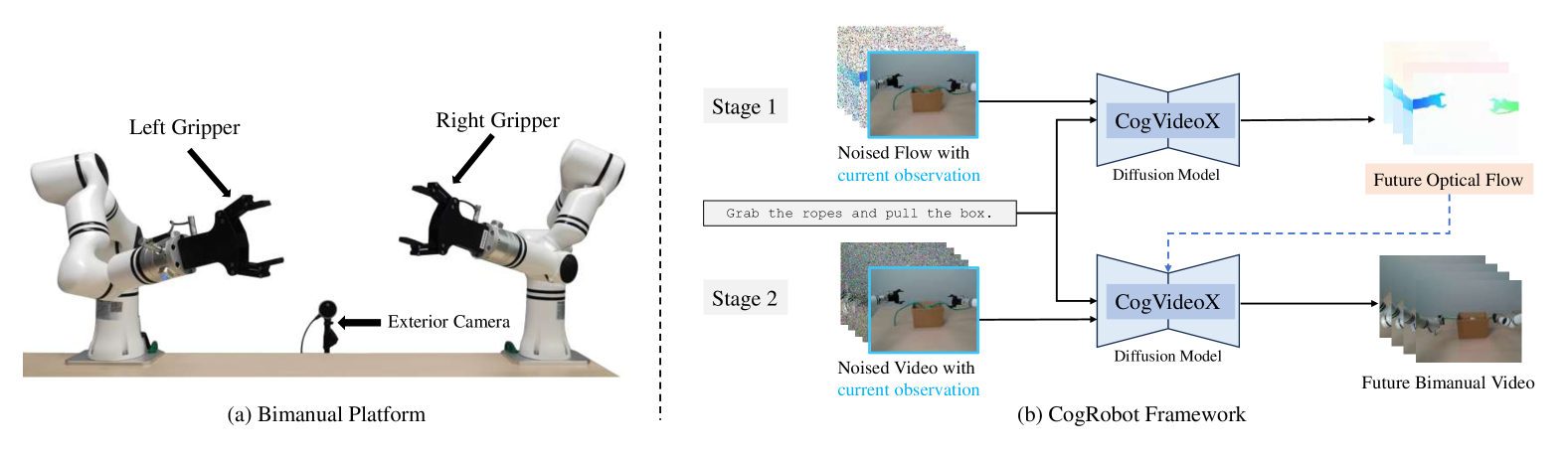
核心思路:论文的核心思路是将文本到视频的生成过程分解为两个阶段:文本到光流的生成和光流到视频的生成。光流作为中间表示,能够简洁地表达图像之间的细微运动,从而解耦了文本理解和动作生成,降低了对机器人数据的需求。
技术框架:整体框架包含两个主要阶段:1) 文本到光流的生成:使用预训练的文本到视频模型,并对其进行微调,使其能够根据文本指令预测光流。2) 光流到视频的生成:使用另一个微调后的模型,根据光流生成视频。然后,使用轻量级的扩散模型将生成的视频转换为机器人动作。
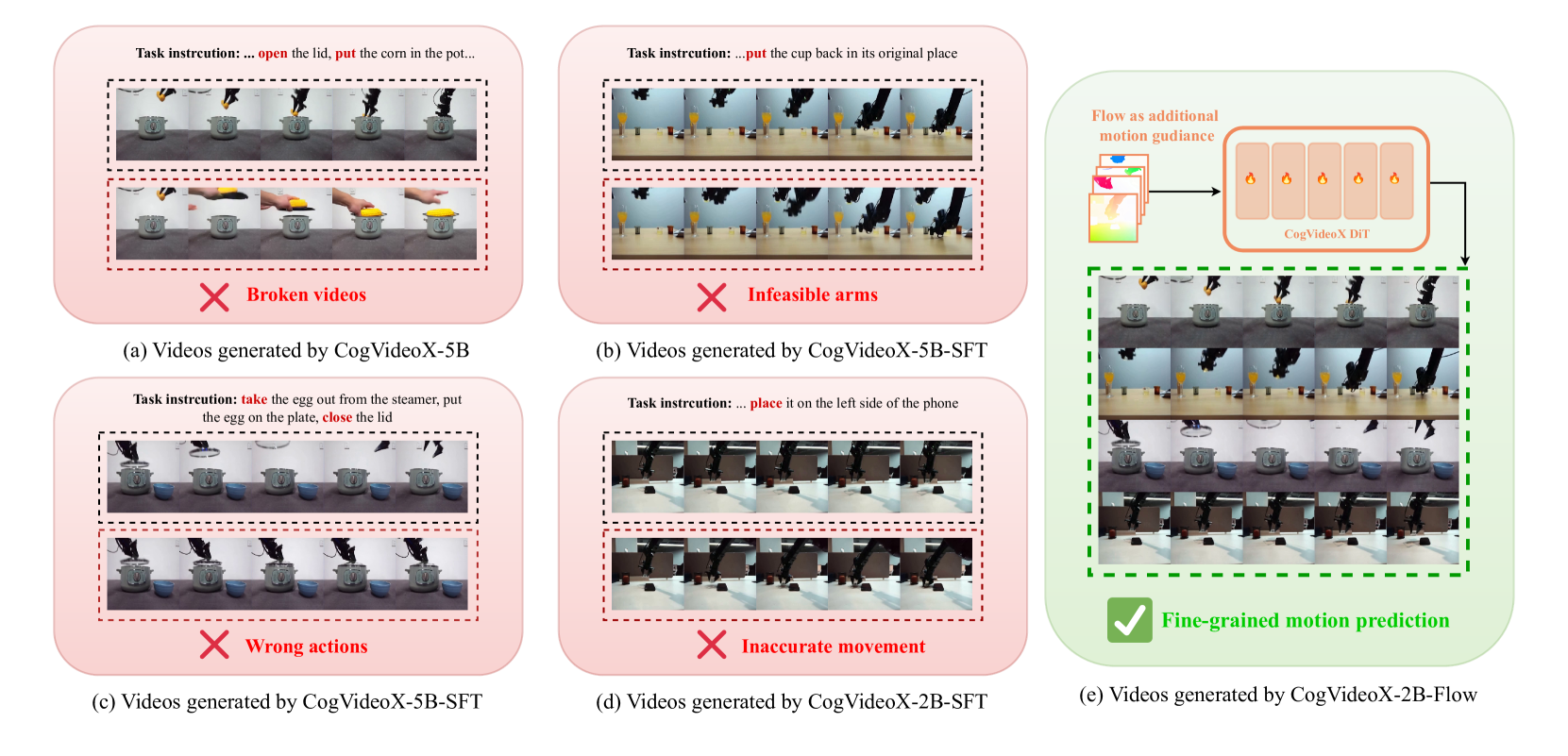
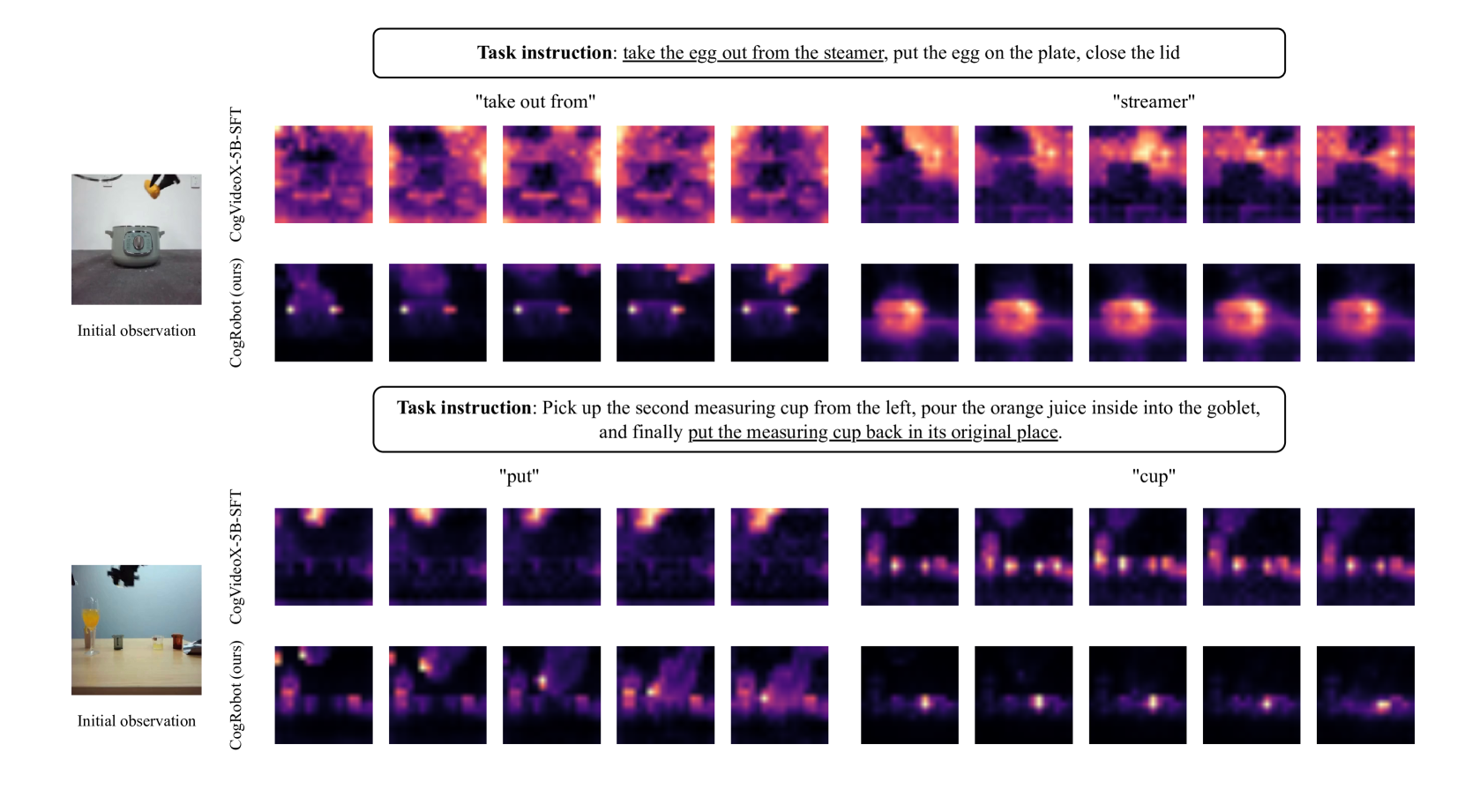
关键创新:最重要的创新点在于使用光流作为中间表示,将复杂的文本到视频生成过程分解为两个更简单的阶段。这使得模型能够更好地理解文本指令的意图,并生成更精确的动作。此外,该方法避免了直接使用低级动作,从而降低了对机器人数据的需求。
关键设计:论文使用了预训练的文本到视频模型作为基础,并对其进行了微调。具体来说,文本到光流模型和光流到视频模型都是从预训练模型派生而来。损失函数包括光流预测的损失和视频生成的损失。扩散模型用于将生成的视频转换为机器人动作,其结构和参数设置需要根据具体的机器人平台进行调整。具体参数和网络结构细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
论文通过仿真和真实机器人实验验证了该方法的有效性。实验结果表明,该方法能够显著提升双臂操作策略的泛化能力,并在不同的任务和环境中取得良好的性能。具体的性能数据和提升幅度在摘要中未提及,属于未知信息。
🎯 应用场景
该研究成果可应用于各种需要双臂协调操作的机器人任务,例如装配、抓取、操作工具等。通过提升双臂操作策略的泛化能力,可以降低机器人部署的成本和难度,使其能够更好地适应不同的环境和任务需求。未来,该方法有望应用于更复杂的机器人系统,例如人形机器人和协作机器人。
📄 摘要(原文)
Learning a generalizable bimanual manipulation policy is extremely challenging for embodied agents due to the large action space and the need for coordinated arm movements. Existing approaches rely on Vision-Language-Action (VLA) models to acquire bimanual policies. However, transferring knowledge from single-arm datasets or pre-trained VLA models often fails to generalize effectively, primarily due to the scarcity of bimanual data and the fundamental differences between single-arm and bimanual manipulation. In this paper, we propose a novel bimanual foundation policy by fine-tuning the leading text-to-video models to predict robot trajectories and training a lightweight diffusion policy for action generation. Given the lack of embodied knowledge in text-to-video models, we introduce a two-stage paradigm that fine-tunes independent text-to-flow and flow-to-video models derived from a pre-trained text-to-video model. Specifically, optical flow serves as an intermediate variable, providing a concise representation of subtle movements between images. The text-to-flow model predicts optical flow to concretize the intent of language instructions, and the flow-to-video model leverages this flow for fine-grained video prediction. Our method mitigates the ambiguity of language in single-stage text-to-video prediction and significantly reduces the robot-data requirement by avoiding direct use of low-level actions. In experiments, we collect high-quality manipulation data for real dual-arm robot, and the results of simulation and real-world experiments demonstrate the effectiveness of our method.