Vid-SME: Membership Inference Attacks against Large Video Understanding Models
作者: Qi Li, Runpeng Yu, Xinchao Wang
分类: cs.CV, cs.AI
发布日期: 2025-05-29
💡 一句话要点
提出Vid-SME,针对视频理解大模型进行高效的成员推理攻击。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 成员推理攻击 视频理解大模型 数据隐私 Sharma-Mittal熵 时间序列分析
📋 核心要点
- 现有成员推理攻击方法在视频领域表现不佳,无法有效捕捉视频帧的时间变化和模型行为差异。
- Vid-SME利用模型输出置信度,结合自适应参数化计算Sharma-Mittal熵,区分自然和反转视频帧。
- 实验表明,Vid-SME在多种视频理解大模型上表现出强大的成员推理攻击效果。
📝 摘要(中文)
多模态大型语言模型(MLLM)在处理复杂的多模态任务中表现出卓越的能力,并越来越多地应用于视频理解。然而,它们的快速发展引发了严重的数据隐私问题,特别是考虑到其训练数据集中可能包含敏感的视频内容,如个人录像和监控录像。确定训练期间不当使用的视频仍然是一个关键且未解决的挑战。尽管在MLLM中针对文本和图像数据的成员推理攻击(MIA)取得了相当大的进展,但现有方法未能有效地推广到视频领域。这些方法的可扩展性较差,因为采样了更多的帧,并且通常在低假阳性率下实现了可忽略不计的真阳性率(TPR@Low FPR),这主要是因为它们未能捕捉视频帧固有的时间变化,并且未能考虑到模型行为随着帧数的变化而产生的差异。为了应对这些挑战,我们引入了Vid-SME,这是第一个为视频理解LLM(VULLM)中使用的视频数据量身定制的成员推理方法。Vid-SME利用模型输出的置信度,并集成自适应参数化来计算视频输入的Sharma-Mittal熵(SME)。通过利用自然视频帧和时间反转视频帧之间的SME差异,Vid-SME推导出鲁棒的成员分数,以确定给定的视频是否是模型训练集的一部分。在各种自训练和开源VULLM上的实验证明了Vid-SME的强大有效性。
🔬 方法详解
问题定义:论文旨在解决视频理解大模型(VULLM)中存在的成员推理攻击问题。现有针对文本和图像的成员推理攻击方法无法有效应用于视频数据,主要原因是视频数据具有时间序列特性,且模型行为会随着输入帧数变化而变化,导致现有方法在视频数据上表现不佳,真阳性率低。
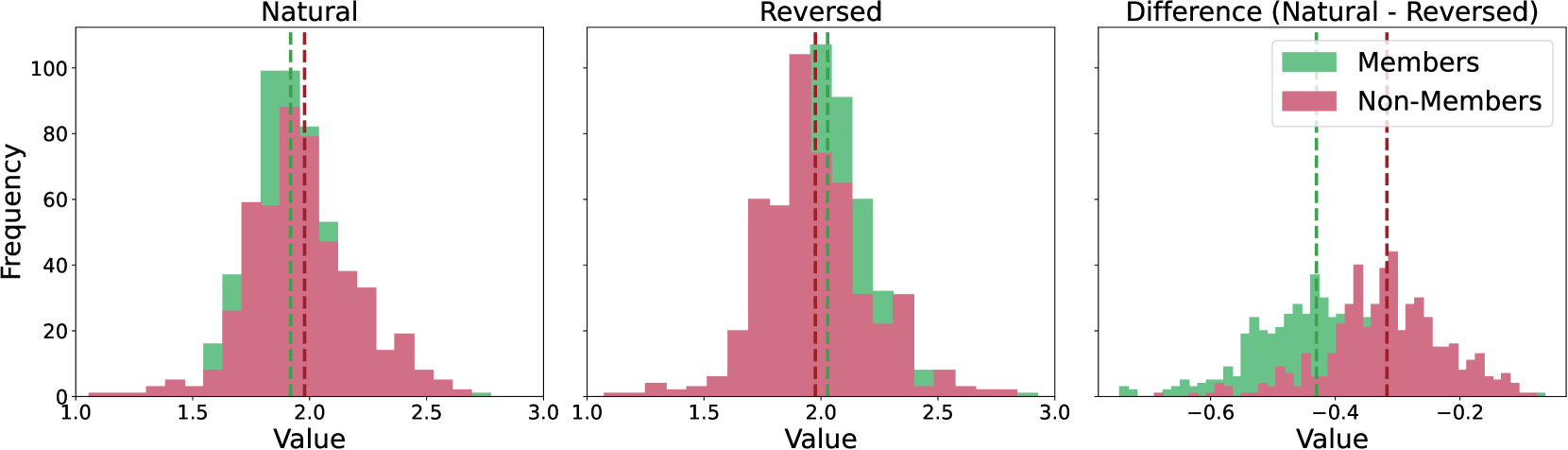
核心思路:论文的核心思路是利用视频帧的时间一致性与时间反转帧的不一致性之间的差异来判断视频是否属于训练集。通过计算模型对自然视频和时间反转视频的输出置信度的Sharma-Mittal熵(SME),并比较二者差异,可以得到一个鲁棒的成员分数,用于判断视频是否为训练集成员。这种方法能够有效捕捉视频的时间信息,并适应不同帧数下的模型行为。
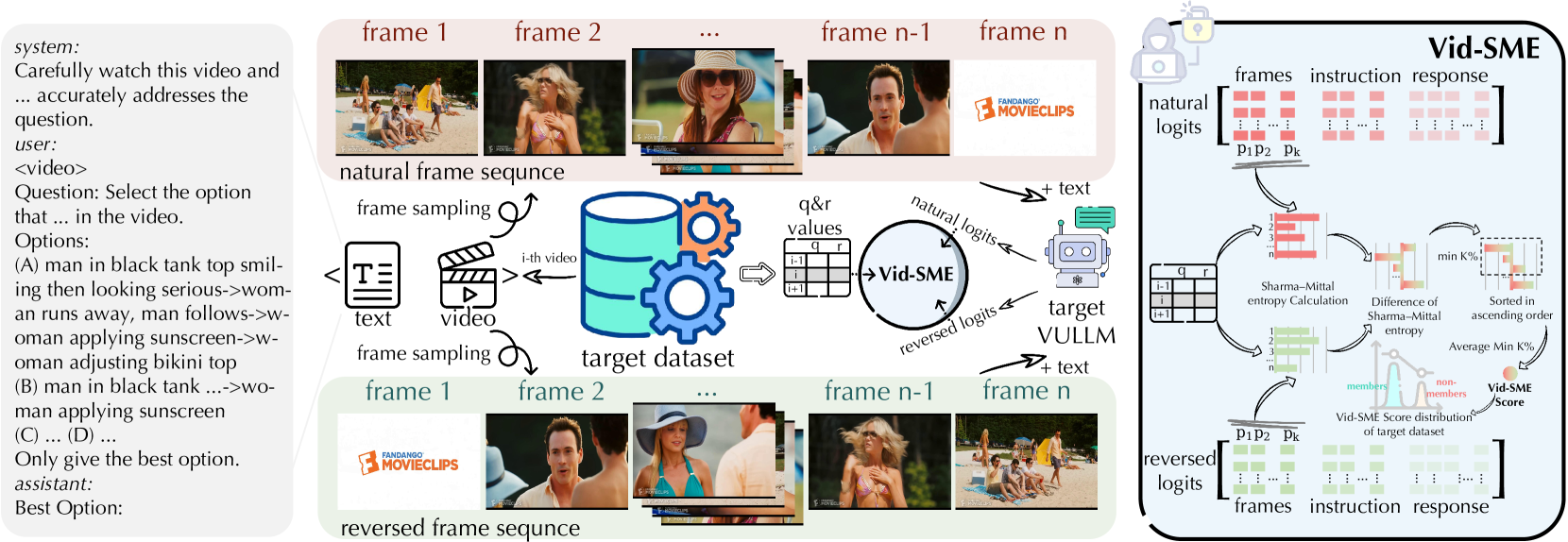
技术框架:Vid-SME的整体框架主要包括以下几个步骤:1) 输入视频数据;2) 使用VULLM模型进行推理,得到模型输出的置信度;3) 对原始视频进行时间反转,再次使用VULLM模型进行推理,得到反转视频的置信度;4) 使用自适应参数化方法计算原始视频和反转视频的Sharma-Mittal熵(SME);5) 计算原始视频和反转视频的SME差异,得到成员分数;6) 使用成员分数判断视频是否属于训练集。
关键创新:Vid-SME的关键创新在于:1) 它是第一个专门为视频理解大模型设计的成员推理攻击方法;2) 它利用了自然视频和时间反转视频之间的SME差异,能够有效捕捉视频的时间信息;3) 它采用了自适应参数化方法,能够适应不同帧数下的模型行为。与现有方法相比,Vid-SME能够显著提高成员推理攻击的成功率。
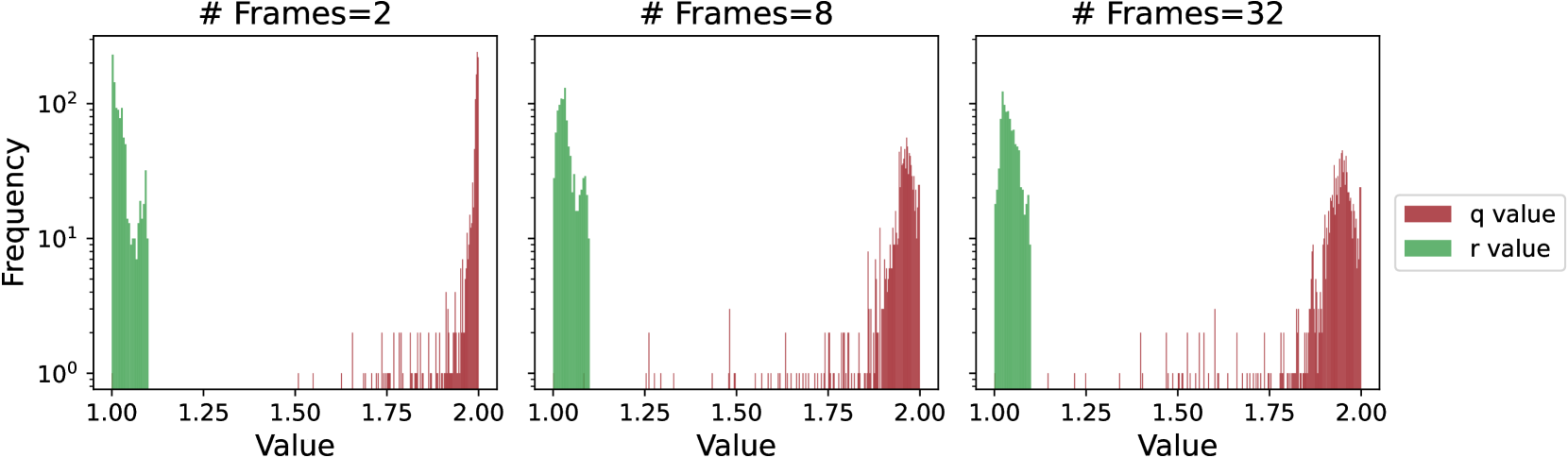
关键设计:Vid-SME的关键设计包括:1) Sharma-Mittal熵(SME)的计算公式,用于衡量模型输出置信度的不确定性;2) 自适应参数化方法,用于根据视频帧数动态调整SME计算的参数;3) 成员分数的计算方法,用于衡量视频属于训练集的可能性。具体参数设置和损失函数细节在论文中进行了详细描述。
🖼️ 关键图片
📊 实验亮点
论文在多个自训练和开源的视频理解大模型上进行了实验,证明了Vid-SME的有效性。实验结果表明,Vid-SME在低假阳性率下能够实现显著的真阳性率,远高于现有的成员推理攻击方法。具体的性能数据和对比基线在论文中进行了详细展示,证明了Vid-SME在视频数据上的优越性。
🎯 应用场景
Vid-SME的研究成果可应用于评估和提升视频理解大模型的数据隐私保护能力。通过使用Vid-SME进行成员推理攻击,可以发现模型训练数据中存在的隐私泄露风险,并指导模型开发者采取相应的防御措施,例如差分隐私训练、数据脱敏等,从而保护用户隐私,防止敏感视频数据被滥用。该研究对于构建安全可靠的视频理解系统具有重要意义。
📄 摘要(原文)
Multimodal large language models (MLLMs) demonstrate remarkable capabilities in handling complex multimodal tasks and are increasingly adopted in video understanding applications. However, their rapid advancement raises serious data privacy concerns, particularly given the potential inclusion of sensitive video content, such as personal recordings and surveillance footage, in their training datasets. Determining improperly used videos during training remains a critical and unresolved challenge. Despite considerable progress on membership inference attacks (MIAs) for text and image data in MLLMs, existing methods fail to generalize effectively to the video domain. These methods suffer from poor scalability as more frames are sampled and generally achieve negligible true positive rates at low false positive rates (TPR@Low FPR), mainly due to their failure to capture the inherent temporal variations of video frames and to account for model behavior differences as the number of frames varies. To address these challenges, we introduce Vid-SME, the first membership inference method tailored for video data used in video understanding LLMs (VULLMs). Vid-SME leverages the confidence of model output and integrates adaptive parameterization to compute Sharma-Mittal entropy (SME) for video inputs. By leveraging the SME difference between natural and temporally-reversed video frames, Vid-SME derives robust membership scores to determine whether a given video is part of the model's training set. Experiments on various self-trained and open-sourced VULLMs demonstrate the strong effectiveness of Vid-SME.