Impromptu VLA: Open Weights and Open Data for Driving Vision-Language-Action Models
作者: Haohan Chi, Huan-ang Gao, Ziming Liu, Jianing Liu, Chenyu Liu, Jinwei Li, Kaisen Yang, Yangcheng Yu, Zeda Wang, Wenyi Li, Leichen Wang, Xingtao Hu, Hao Sun, Hang Zhao, Hao Zhao
分类: cs.CV
发布日期: 2025-05-29
备注: Project page: https://github.com/ahydchh/Impromptu-VLA
🔗 代码/项目: GITHUB
💡 一句话要点
Impromptu VLA:开放数据与权重,赋能自动驾驶视觉-语言-动作模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 视觉-语言-动作模型 数据集 非结构化场景 问答系统 轨迹预测 基准测试
📋 核心要点
- 现有VLA模型在自动驾驶非结构化场景中表现不足,缺乏针对性benchmark是主要瓶颈。
- Impromptu VLA通过构建包含8万+视频片段的数据集,并提供问答注释和动作轨迹,解决上述问题。
- 实验表明,使用该数据集训练的VLA模型在NeuroNCAP分数、碰撞率和轨迹预测精度上均有显著提升。
📝 摘要(中文)
用于自动驾驶的视觉-语言-动作(VLA)模型展现了潜力,但在非结构化的极端场景中表现不佳,这主要是由于缺乏有针对性的基准。为了解决这个问题,我们推出了Impromptu VLA。我们的核心贡献是Impromptu VLA数据集:超过80,000个精心策划的视频片段,这些片段是从8个开源大型数据集中提取的超过200万个源片段中提炼出来的。该数据集建立在我们新颖的四个具有挑战性的非结构化类别分类法之上,并具有丰富的、面向规划的问答注释和动作轨迹。至关重要的是,实验表明,使用我们的数据集训练的VLA在已建立的基准上取得了显著的性能提升——提高了闭环NeuroNCAP分数和碰撞率,并在开放环路nuScenes轨迹预测中达到了接近最先进的L2精度。此外,我们的问答套件可以作为一个有效的诊断工具,揭示了VLM在感知、预测和规划方面的明显改进。我们的代码、数据和模型可在https://github.com/ahydchh/Impromptu-VLA上获得。
🔬 方法详解
问题定义:现有自动驾驶VLA模型在处理非结构化和极端场景时面临挑战,主要原因是缺乏足够规模和多样性的、带有针对性标注的数据集。现有数据集难以覆盖这些corner case,导致模型泛化能力不足。
核心思路:论文的核心思路是构建一个大规模、高质量、包含丰富场景和标注的Impromptu VLA数据集,用于训练和评估VLA模型在复杂驾驶环境下的性能。通过提供更具挑战性的数据,提升模型在实际驾驶场景中的鲁棒性和安全性。
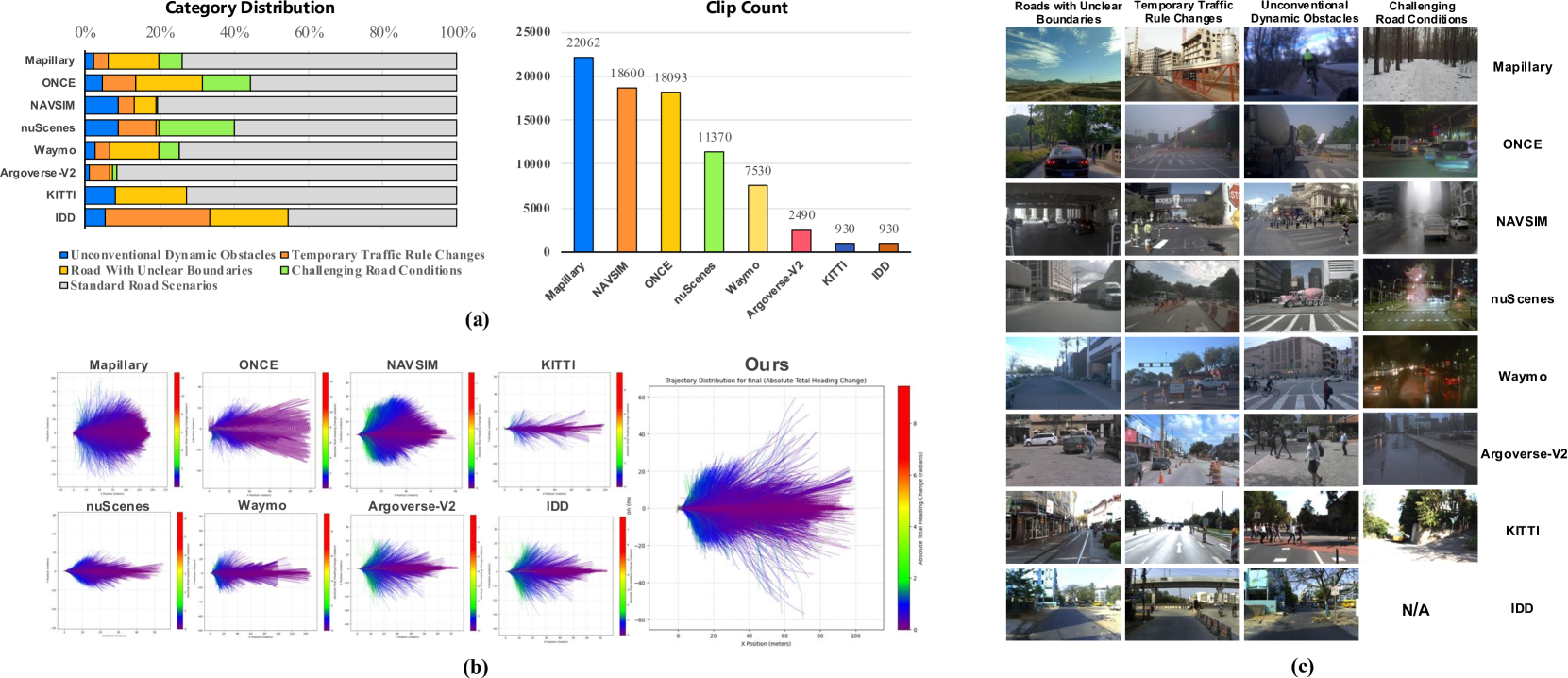
技术框架:Impromptu VLA数据集的构建流程包括:1) 从8个开源自动驾驶数据集中筛选出超过200万个视频片段;2) 基于论文提出的非结构化场景分类法(未知)对片段进行分类;3) 从中精选出8万多个片段进行标注,包括规划导向的问答注释和动作轨迹。数据集用于训练VLA模型,并通过NeuroNCAP、碰撞率和轨迹预测等指标进行评估。
关键创新:论文的关键创新在于Impromptu VLA数据集本身,它具有以下特点:1) 大规模:包含8万多个视频片段;2) 高质量:数据经过精心筛选和标注;3) 场景多样:覆盖了各种非结构化和极端驾驶场景;4) 标注丰富:提供规划导向的问答注释和动作轨迹。此外,论文还提出了一个用于诊断VLA模型性能的问答套件。
关键设计:论文的关键设计包括:1) 非结构化场景分类法的具体类别(未知);2) 问答注释的设计原则和具体问题类型(未知);3) 动作轨迹的表示方法和标注规范(未知);4) VLA模型的具体架构和训练策略(未知)。这些细节对于数据集的有效性和模型的性能至关重要,但论文摘要中未详细描述。
🖼️ 关键图片


📊 实验亮点
使用Impromptu VLA数据集训练的VLA模型在多个基准测试中取得了显著提升。在闭环NeuroNCAP测试中,模型分数和碰撞率均得到改善。在开放环路nuScenes轨迹预测任务中,模型达到了接近最先进的L2精度。问答套件也有效揭示了VLM在感知、预测和规划方面的改进。
🎯 应用场景
该研究成果可广泛应用于自动驾驶系统的开发和测试,尤其是在提升自动驾驶系统在复杂和非结构化环境下的安全性和可靠性方面。Impromptu VLA数据集可以作为VLA模型训练和评估的标准基准,促进相关算法的进步。此外,该数据集和问答套件也可用于自动驾驶系统的诊断和调试。
📄 摘要(原文)
Vision-Language-Action (VLA) models for autonomous driving show promise but falter in unstructured corner case scenarios, largely due to a scarcity of targeted benchmarks. To address this, we introduce Impromptu VLA. Our core contribution is the Impromptu VLA Dataset: over 80,000 meticulously curated video clips, distilled from over 2M source clips sourced from 8 open-source large-scale datasets. This dataset is built upon our novel taxonomy of four challenging unstructured categories and features rich, planning-oriented question-answering annotations and action trajectories. Crucially, experiments demonstrate that VLAs trained with our dataset achieve substantial performance gains on established benchmarks--improving closed-loop NeuroNCAP scores and collision rates, and reaching near state-of-the-art L2 accuracy in open-loop nuScenes trajectory prediction. Furthermore, our Q&A suite serves as an effective diagnostic, revealing clear VLM improvements in perception, prediction, and planning. Our code, data and models are available at https://github.com/ahydchh/Impromptu-VLA.