ThinkGeo: Evaluating Tool-Augmented Agents for Remote Sensing Tasks
作者: Akashah Shabbir, Muhammad Akhtar Munir, Akshay Dudhane, Muhammad Umer Sheikh, Muhammad Haris Khan, Paolo Fraccaro, Juan Bernabe Moreno, Fahad Shahbaz Khan, Salman Khan
分类: cs.CV
发布日期: 2025-05-29 (更新: 2025-10-09)
💡 一句话要点
ThinkGeo:评估工具增强型Agent在遥感任务中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 遥感 大型语言模型 工具增强Agent 基准测试 空间推理
📋 核心要点
- 现有LLM评估侧重通用场景,缺乏遥感领域工具使用能力的针对性评估。
- ThinkGeo通过结构化工具使用和多步骤规划,评估LLM在遥感任务中的Agent能力。
- 实验结果揭示了不同LLM在工具准确性和规划一致性方面的显著差异。
📝 摘要(中文)
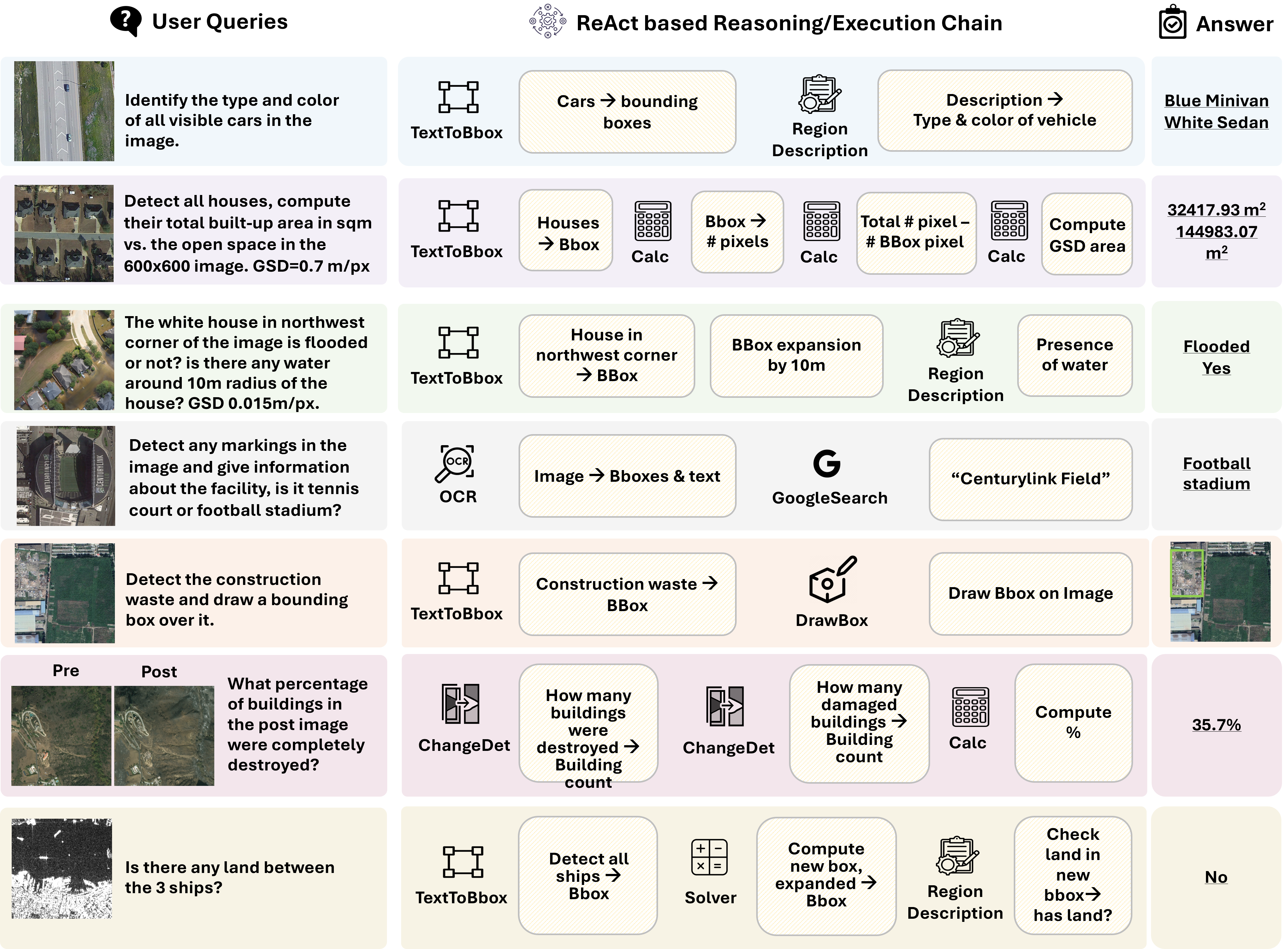
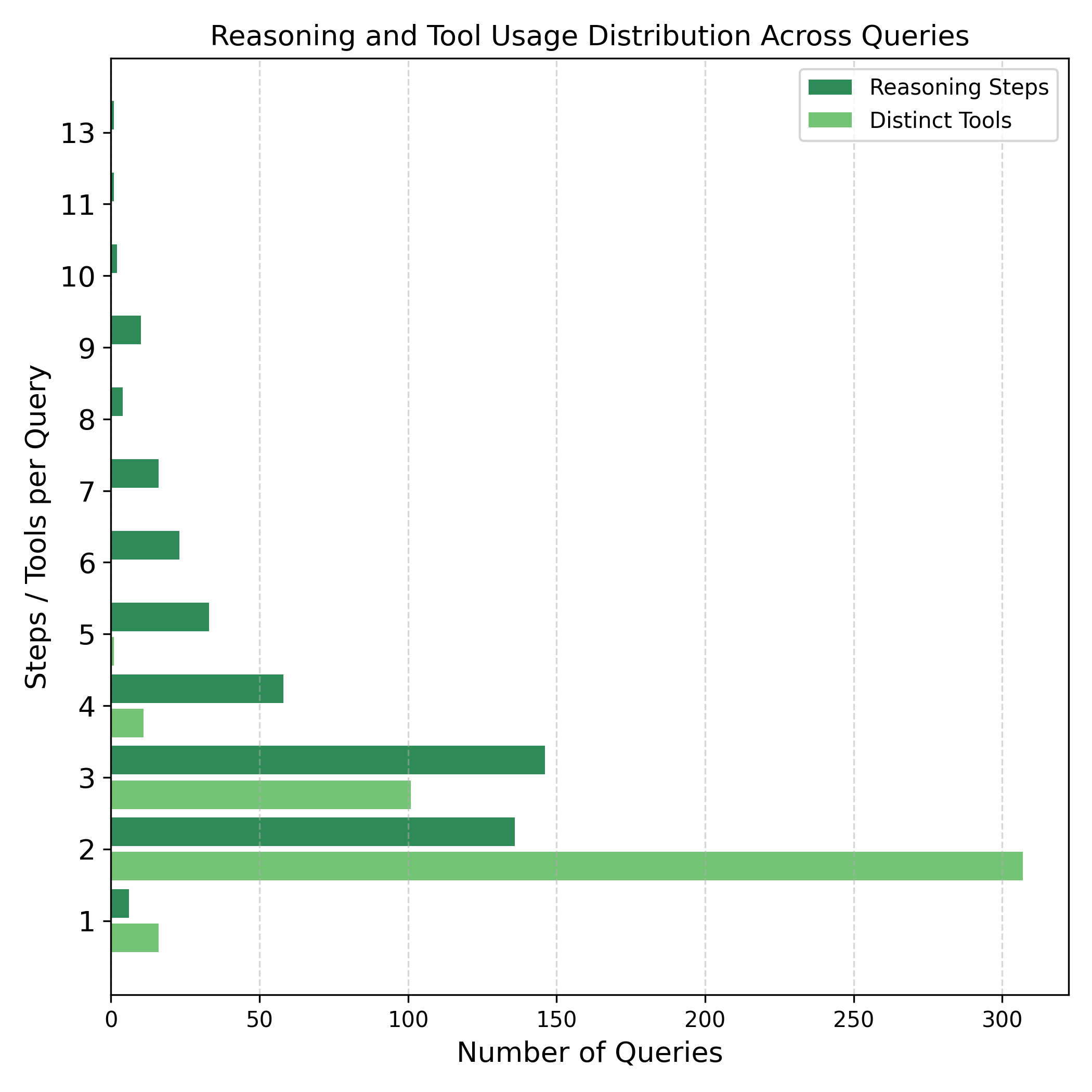
大型语言模型(LLMs)的最新进展使得工具增强型Agent能够通过逐步推理解决复杂的现实世界任务。然而,现有的评估通常侧重于通用或多模态场景,缺乏评估LLM在复杂遥感用例中工具使用能力的领域特定基准。本文提出了ThinkGeo,一个Agent基准,旨在通过结构化的工具使用和多步骤规划来评估LLM驱动的Agent在遥感任务中的性能。ThinkGeo受到工具交互范式的启发,包含人工策划的查询,涵盖了城市规划、灾害评估与变化分析、环境监测、交通分析、航空监测、休闲基础设施和工业场地分析等广泛的实际应用。查询基于卫星或航空图像,包括光学RGB和SAR数据,并要求Agent通过多样化的工具集进行推理。本文实现了ReAct风格的交互循环,并在486个结构化的Agent任务上评估了开源和闭源LLM(例如,GPT-4o,Qwen2.5),包含1,773个专家验证的推理步骤。该基准报告了逐步执行指标和最终答案的正确性。分析表明,不同模型在工具准确性和规划一致性方面存在显著差异。ThinkGeo为评估工具增强型LLM如何处理遥感中的空间推理提供了第一个广泛的测试平台。
🔬 方法详解
问题定义:论文旨在解决缺乏针对遥感领域,特别是评估工具增强型LLM在遥感任务中应用能力的基准测试的问题。现有方法主要集中在通用或多模态场景,无法充分评估LLM在处理遥感数据和执行复杂空间推理任务时的性能。
核心思路:论文的核心思路是构建一个专门针对遥感任务的Agent基准测试平台,即ThinkGeo。该平台通过提供结构化的工具使用和多步骤规划,来评估LLM驱动的Agent在各种遥感应用场景中的表现。通过模拟真实世界的遥感任务,ThinkGeo能够更全面地评估LLM的空间推理能力和工具使用效率。
技术框架:ThinkGeo的技术框架主要包括以下几个部分:1) 人工策划的遥感查询,涵盖城市规划、灾害评估等多个应用领域;2) 基于卫星或航空图像的光学RGB和SAR数据;3) 多样化的工具集,用于处理遥感数据和执行空间推理;4) ReAct风格的交互循环,允许Agent通过观察和行动进行迭代推理;5) 评估指标,包括逐步执行指标和最终答案的正确性。
关键创新:ThinkGeo的关键创新在于其作为第一个专门针对遥感任务的Agent基准测试平台。与现有的通用基准测试相比,ThinkGeo更关注LLM在处理遥感数据和执行复杂空间推理任务时的能力。此外,ThinkGeo还提供了多样化的工具集和人工策划的查询,使得评估更加全面和贴近实际应用。
关键设计:ThinkGeo的关键设计包括:1) 查询的设计,确保涵盖各种遥感应用场景和需要不同工具的复杂推理步骤;2) 工具集的设计,确保能够处理各种遥感数据和执行空间推理任务;3) 评估指标的设计,确保能够全面评估Agent的性能,包括逐步执行的准确性和最终答案的正确性;4) ReAct风格的交互循环,允许Agent通过观察和行动进行迭代推理,从而更好地解决复杂问题。
🖼️ 关键图片

📊 实验亮点
ThinkGeo基准测试在486个结构化Agent任务上评估了GPT-4o、Qwen2.5等多种LLM,包含1,773个专家验证的推理步骤。实验结果表明,不同模型在工具准确性和规划一致性方面存在显著差异,突显了ThinkGeo在评估LLM遥感应用能力方面的重要性。
🎯 应用场景
ThinkGeo的研究成果可应用于多种遥感领域,例如城市规划、灾害评估、环境监测、交通分析等。通过评估和优化LLM在遥感任务中的性能,可以提高遥感数据分析的效率和准确性,为决策者提供更可靠的依据,并促进遥感技术的更广泛应用。
📄 摘要(原文)
Recent progress in large language models (LLMs) has enabled tool-augmented agents capable of solving complex real-world tasks through step-by-step reasoning. However, existing evaluations often focus on general-purpose or multimodal scenarios, leaving a gap in domain-specific benchmarks that assess tool-use capabilities in complex remote sensing use cases. We present ThinkGeo, an agentic benchmark designed to evaluate LLM-driven agents on remote sensing tasks via structured tool use and multi-step planning. Inspired by tool-interaction paradigms, ThinkGeo includes human-curated queries spanning a wide range of real-world applications such as urban planning, disaster assessment and change analysis, environmental monitoring, transportation analysis, aviation monitoring, recreational infrastructure, and industrial site analysis. Queries are grounded in satellite or aerial imagery, including both optical RGB and SAR data, and require agents to reason through a diverse toolset. We implement a ReAct-style interaction loop and evaluate both open and closed-source LLMs (e.g., GPT-4o, Qwen2.5) on 486 structured agentic tasks with 1,773 expert-verified reasoning steps. The benchmark reports both step-wise execution metrics and final answer correctness. Our analysis reveals notable disparities in tool accuracy and planning consistency across models. ThinkGeo provides the first extensive testbed for evaluating how tool-enabled LLMs handle spatial reasoning in remote sensing.