Grounded Reinforcement Learning for Visual Reasoning
作者: Gabriel Sarch, Snigdha Saha, Naitik Khandelwal, Ayush Jain, Michael J. Tarr, Aviral Kumar, Katerina Fragkiadaki
分类: cs.CV
发布日期: 2025-05-29 (更新: 2025-10-20)
备注: Project website: https://visually-grounded-rl.github.io/
💡 一句话要点
提出ViGoRL:一种视觉强化学习模型,通过空间定位提升视觉推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉推理 强化学习 视觉定位 多模态学习 视觉搜索
📋 核心要点
- 现有方法在视觉推理中缺乏对视觉注意力的有效引导和空间信息的显式利用,限制了模型性能。
- ViGoRL通过强化学习训练模型,使其能够将推理步骤与特定视觉坐标对齐,模拟人类视觉决策过程。
- 实验表明,ViGoRL在多个视觉推理任务上超越了现有方法,尤其在精细定位和视觉搜索方面有显著提升。
📝 摘要(中文)
本文提出了一种名为ViGoRL(Visually Grounded Reinforcement Learning)的视觉-语言模型,该模型通过强化学习进行训练,能够将每个推理步骤显式地锚定到特定的视觉坐标。受到人类视觉决策的启发,ViGoRL学习生成空间定位的推理轨迹,引导视觉注意力到每个步骤中与任务相关的区域。当需要精细探索时,提出的多轮强化学习框架使模型能够动态地放大预测坐标,随着推理的展开提供视觉反馈。在包括SAT-2和BLINK(空间推理)、Vbench(视觉搜索)以及ScreenSpot和VisualWebArena(基于Web的定位)在内的各种视觉推理基准测试中,ViGoRL始终优于监督微调和缺乏显式定位机制的传统强化学习基线。结合多轮强化学习和放大视觉反馈显著提高了ViGoRL在定位小型GUI元素和视觉搜索方面的性能,在VBench上达到了86.4%。此外,研究发现定位增强了其他视觉行为,如区域探索、定位子目标设置和视觉验证。人类评估表明,该模型的视觉参考不仅在空间上准确,而且有助于理解模型的推理步骤。结果表明,视觉定位强化学习是赋予模型通用视觉推理能力的强大范例。
🔬 方法详解
问题定义:论文旨在解决视觉推理任务中,现有模型无法有效利用视觉信息进行推理的问题。现有方法,如监督微调和传统强化学习,缺乏显式的视觉定位机制,导致模型难以准确地关注到图像中的关键区域,从而影响推理的准确性和效率。特别是在需要精细定位的任务中,这一问题尤为突出。
核心思路:论文的核心思路是利用强化学习训练一个视觉-语言模型,使其能够显式地将推理步骤与图像中的特定视觉坐标关联起来。通过这种方式,模型可以学习到一种空间定位的推理策略,引导视觉注意力到与任务相关的区域。这种方法模仿了人类在进行视觉推理时的视觉决策过程,从而提高了模型的推理能力。
技术框架:ViGoRL的整体框架包含一个视觉-语言模型,该模型通过强化学习进行训练。在每个推理步骤中,模型首先接收视觉输入(图像)和语言输入(问题或指令),然后预测一个视觉坐标。模型根据预测坐标处的视觉信息更新其内部状态,并生成下一个推理步骤。为了支持精细探索,论文引入了一个多轮强化学习框架,允许模型动态地放大预测坐标,从而获得更详细的视觉反馈。
关键创新:论文的关键创新在于提出了视觉定位强化学习(Visually Grounded Reinforcement Learning)的概念,并将其应用于视觉推理任务。与传统的强化学习方法相比,ViGoRL显式地将推理步骤与视觉坐标关联起来,从而提高了模型对视觉信息的利用率。此外,多轮强化学习框架允许模型进行精细探索,进一步提高了模型的定位精度。
关键设计:ViGoRL的关键设计包括:1) 使用强化学习训练模型,奖励函数鼓励模型预测准确的视觉坐标;2) 引入多轮强化学习框架,允许模型动态地放大预测坐标;3) 设计合适的网络结构,以便模型能够有效地处理视觉和语言输入,并预测视觉坐标;4) 使用多种视觉推理基准测试来评估模型的性能,并与现有方法进行比较。
🖼️ 关键图片
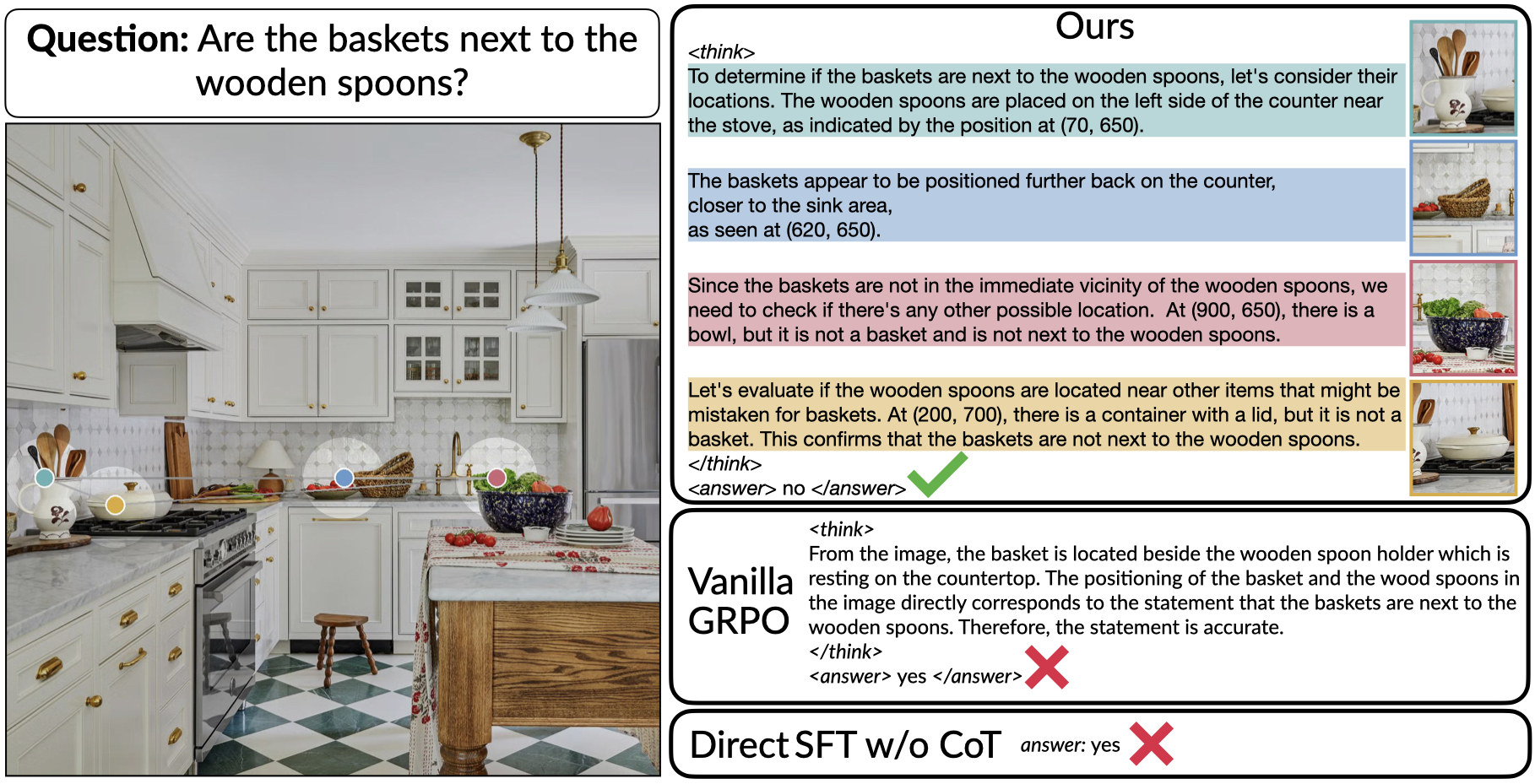

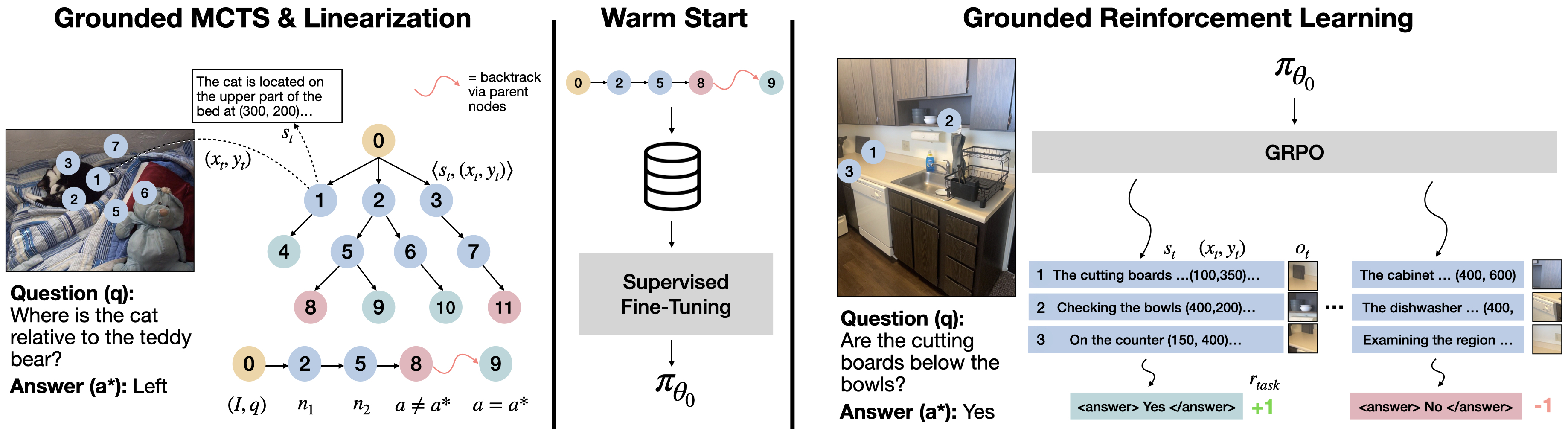
📊 实验亮点
ViGoRL在多个视觉推理基准测试中取得了显著的性能提升。例如,在V*Bench视觉搜索任务中,ViGoRL达到了86.4%的准确率,显著优于监督微调和传统强化学习基线。此外,实验还表明,视觉定位能够增强模型的其他视觉行为,如区域探索和子目标设置。人类评估也表明,ViGoRL的视觉参考在空间上准确且有助于理解模型的推理过程。
🎯 应用场景
ViGoRL具有广泛的应用前景,例如:智能助手可以利用该技术理解用户对屏幕内容的提问,并精确定位相关元素;在自动驾驶领域,模型可以辅助车辆识别交通标志和行人;在医疗影像分析中,可以帮助医生定位病灶区域。该研究为通用视觉推理模型的发展奠定了基础。
📄 摘要(原文)
While reinforcement learning (RL) over chains of thought has significantly advanced language models in tasks such as mathematics and coding, visual reasoning introduces added complexity by requiring models to direct visual attention, interpret perceptual inputs, and ground abstract reasoning in spatial evidence. We introduce ViGoRL (Visually Grounded Reinforcement Learning), a vision-language model trained with RL to explicitly anchor each reasoning step to specific visual coordinates. Inspired by human visual decision-making, ViGoRL learns to produce spatially grounded reasoning traces, guiding visual attention to task-relevant regions at each step. When fine-grained exploration is required, our novel multi-turn RL framework enables the model to dynamically zoom into predicted coordinates as reasoning unfolds. Across a diverse set of visual reasoning benchmarks--including SAT-2 and BLINK for spatial reasoning, Vbench for visual search, and ScreenSpot and VisualWebArena for web-based grounding--ViGoRL consistently outperforms both supervised fine-tuning and conventional RL baselines that lack explicit grounding mechanisms. Incorporating multi-turn RL with zoomed-in visual feedback significantly improves ViGoRL's performance on localizing small GUI elements and visual search, achieving 86.4% on VBench. Additionally, we find that grounding amplifies other visual behaviors such as region exploration, grounded subgoal setting, and visual verification. Finally, human evaluations show that the model's visual references are not only spatially accurate but also helpful for understanding model reasoning steps. Our results show that visually grounded RL is a strong paradigm for imbuing models with general-purpose visual reasoning.