Jigsaw-R1: A Study of Rule-based Visual Reinforcement Learning with Jigsaw Puzzles
作者: Zifu Wang, Junyi Zhu, Bo Tang, Zhiyu Li, Feiyu Xiong, Jiaqian Yu, Matthew B. Blaschko
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-05-29 (更新: 2025-10-11)
备注: TMLR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
Jigsaw-R1:通过拼图游戏研究基于规则的视觉强化学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉强化学习 多模态学习 拼图游戏 规则学习 大型语言模型
📋 核心要点
- 现有方法在多模态大型语言模型中应用基于规则的强化学习时,面临感知密集型任务的挑战,与纯文本领域存在偏差。
- 论文利用拼图游戏作为实验框架,通过调整难度和提供内在的ground truth,研究视觉强化学习中的决策过程。
- 实验表明,MLLM通过微调在拼图游戏中达到近乎完美的准确率,并能泛化到其他视觉任务,RL比SFT具有更强的泛化能力。
📝 摘要(中文)
本研究针对多模态大型语言模型(MLLM)中基于规则的强化学习(RL)应用,探讨了其在感知密集型任务中与纯文本领域不同的挑战和潜在偏差。论文以拼图游戏为结构化实验框架,揭示了几个关键发现:首先,MLLM在最简单的拼图游戏中表现接近随机猜测,但通过微调可以达到接近完美的准确率,并泛化到复杂的、未见过的配置。其次,在拼图游戏上训练可以诱导模型泛化到其他视觉任务,其有效性与特定任务配置相关。第三,MLLM可以在有或没有显式推理的情况下学习和泛化,但开源模型通常倾向于直接回答。第四,复杂的推理模式似乎是预先存在的,而不是涌现的,其频率随着训练和任务难度的增加而增加。最后,结果表明,RL比监督微调(SFT)表现出更有效的泛化,并且初始的SFT冷启动阶段可能会阻碍后续的RL优化。虽然这些观察结果基于拼图游戏,可能因其他视觉任务而异,但这项研究为理解基于规则的视觉RL及其在多模态学习中的潜力提供了一个有价值的视角。
🔬 方法详解
问题定义:论文旨在研究多模态大型语言模型(MLLM)在视觉强化学习(RL)任务中的表现,特别是基于规则的场景。现有方法在处理感知密集型任务时,面临着泛化能力不足、推理过程不透明等问题,并且缺乏一个结构化的实验框架来深入分析这些问题。拼图游戏提供了一个理想的测试平台,因为它具有可控的难度、明确的规则和内在的ground truth。
核心思路:论文的核心思路是利用拼图游戏作为桥梁,研究MLLM在视觉RL任务中的学习和泛化能力。通过在拼图游戏上训练MLLM,观察其在不同难度级别和配置下的表现,以及其推理过程和泛化能力。这种方法能够提供一个可控的环境,以便深入分析MLLM在视觉RL中的优势和局限性。
技术框架:整体框架包括以下几个主要阶段:1) 使用拼图游戏生成训练数据,包括不同难度级别和配置的拼图;2) 使用监督微调(SFT)或强化学习(RL)方法训练MLLM;3) 在不同的拼图配置和视觉任务上评估MLLM的性能,包括准确率、泛化能力和推理过程;4) 分析实验结果,揭示MLLM在视觉RL中的学习规律和潜在问题。
关键创新:论文的关键创新在于:1) 将拼图游戏作为研究视觉RL的结构化实验框架,提供了一个可控且具有挑战性的测试平台;2) 深入分析了MLLM在拼图游戏中的学习和泛化能力,揭示了其在视觉RL中的优势和局限性;3) 比较了SFT和RL在视觉RL中的性能,发现RL具有更强的泛化能力;4) 观察到复杂的推理模式可能是预先存在的,而不是涌现的。
关键设计:论文的关键设计包括:1) 拼图游戏的难度级别和配置,用于控制任务的复杂性;2) SFT和RL的训练策略,用于比较不同训练方法的性能;3) 评估指标,包括准确率、泛化能力和推理过程,用于全面评估MLLM的性能;4) 对比不同模型的表现,例如开源模型和闭源模型,以了解不同模型的特点。
🖼️ 关键图片
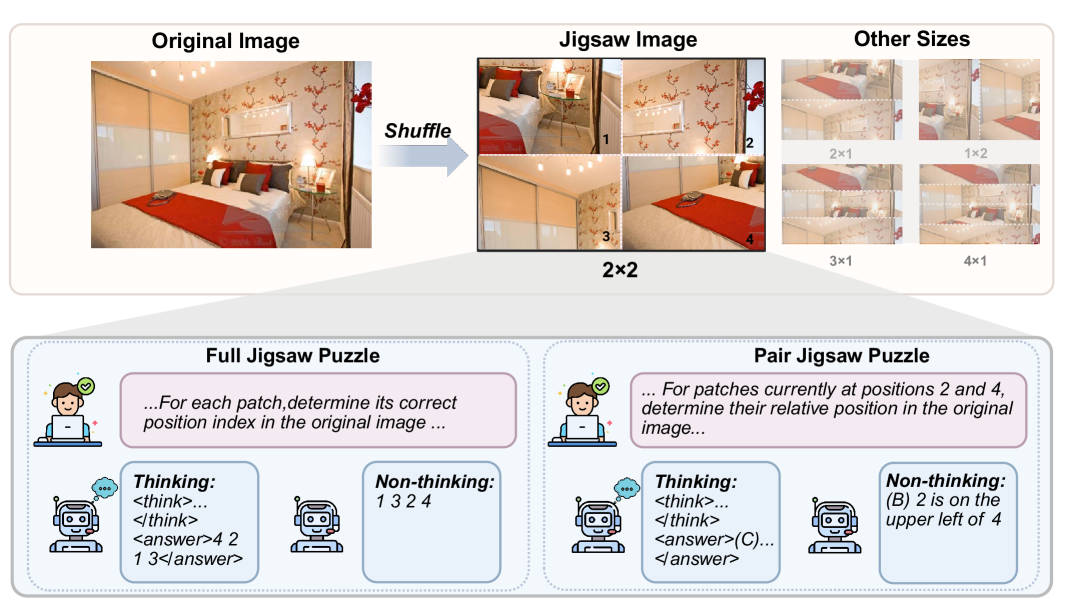
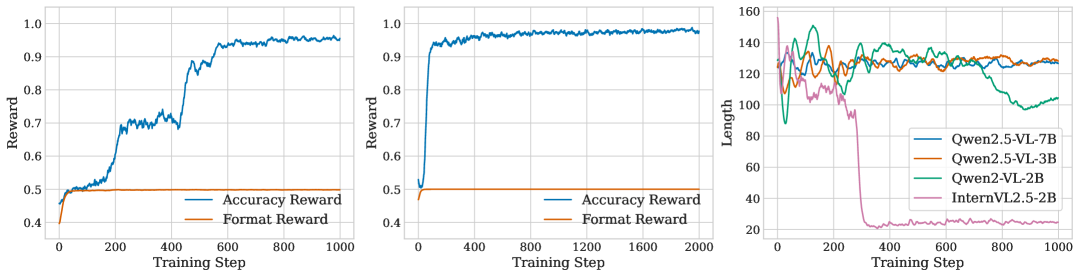
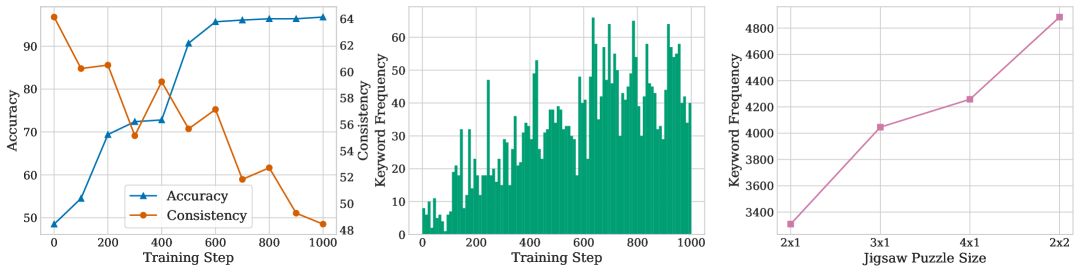
📊 实验亮点
实验结果表明,MLLM通过在拼图游戏上的微调,可以从接近随机猜测的水平提升到接近完美的准确率,并泛化到未见过的复杂配置。此外,RL训练比SFT训练展现出更强的泛化能力。研究还发现,复杂的推理模式可能并非训练中涌现,而是预先存在的,其频率随训练和任务难度增加。
🎯 应用场景
该研究成果可应用于机器人操作、自动驾驶、图像编辑等领域。通过提升模型在视觉环境中的推理和决策能力,可以实现更智能、更自主的系统。例如,机器人可以利用学习到的规则来完成复杂的装配任务,自动驾驶系统可以更好地理解交通场景并做出安全决策。此外,该研究也为多模态学习和通用人工智能的发展提供了有价值的参考。
📄 摘要(原文)
The application of rule-based reinforcement learning (RL) to multimodal large language models (MLLMs) introduces unique challenges and potential deviations from findings in text-only domains, particularly for perception-heavy tasks. This paper provides a comprehensive study of rule-based visual RL, using jigsaw puzzles as a structured experimental framework. Jigsaw puzzles offer inherent ground truth, adjustable difficulty, and demand complex decision-making, making them ideal for this study. Our research reveals several key findings: \textit{Firstly,} we find that MLLMs, initially performing near to random guessing on the simplest jigsaw puzzles, achieve near-perfect accuracy and generalize to complex, unseen configurations through fine-tuning. \textit{Secondly,} training on jigsaw puzzles can induce generalization to other visual tasks, with effectiveness tied to specific task configurations. \textit{Thirdly,} MLLMs can learn and generalize with or without explicit reasoning, though open-source models often favor direct answering. Consequently, even when trained for step-by-step reasoning, they can ignore the thinking process in deriving the final answer. \textit{Fourthly,} we observe that complex reasoning patterns appear to be pre-existing rather than emergent, with their frequency increasing alongside training and task difficulty. \textit{Finally,} our results demonstrate that RL exhibits more effective generalization than Supervised Fine-Tuning (SFT), and an initial SFT cold start phase can hinder subsequent RL optimization. Although these observations are based on jigsaw puzzles and may vary across other visual tasks, this research contributes a valuable piece of jigsaw to the larger puzzle of collective understanding rule-based visual RL and its potential in multimodal learning. The code is available at: https://github.com/zifuwanggg/Jigsaw-R1