Hallo4: High-Fidelity Dynamic Portrait Animation via Direct Preference Optimization
作者: Jiahao Cui, Yan Chen, Mingwang Xu, Hanlin Shang, Yuxuan Chen, Yun Zhan, Zilong Dong, Yao Yao, Jingdong Wang, Siyu Zhu
分类: cs.CV
发布日期: 2025-05-29 (更新: 2025-11-30)
🔗 代码/项目: GITHUB
💡 一句话要点
Hallo4:通过直接偏好优化实现高保真动态人像动画
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 人像动画 扩散模型 直接偏好优化 唇音同步 运动生成 深度学习 计算机视觉
📋 核心要点
- 现有方法难以生成具有精确唇音同步、自然面部表情和高保真身体运动动态的高动态照片级真实人像动画。
- 提出一种人类偏好对齐的扩散框架,通过直接偏好优化和时间运动调制,提升人像动画的真实感和运动连贯性。
- 实验表明,该方法在唇音同步、表情生动性和身体运动连贯性方面优于基线方法,并在人类偏好指标上取得显著提升。
📝 摘要(中文)
本文提出了一种基于人类偏好对齐的扩散框架,用于生成由音频和骨骼运动驱动的高动态、照片级真实人像动画。该框架通过两项关键创新解决现有挑战:一是针对以人为中心动画的直接偏好优化,利用精心策划的人类偏好数据集,使生成结果与人像运动视频对齐和表情自然度等感知指标对齐;二是提出的时间运动调制,通过时间通道重分布和比例特征扩展,将运动条件重塑为维度对齐的潜在特征,从而解决时空分辨率不匹配问题,保留基于扩散合成的高频运动细节保真度。该机制与现有的基于UNet和DiT的人像扩散方法互补。实验表明,与基线方法相比,在唇音同步、表情生动性和身体运动连贯性方面有明显改进,并且在人类偏好指标方面有显著提高。
🔬 方法详解
问题定义:论文旨在解决生成高质量动态人像动画的问题,尤其关注唇音同步的准确性、面部表情的自然性以及身体运动的连贯性。现有方法在处理这些方面时,往往难以达到照片级真实感和自然的运动效果,尤其是在高动态场景下,容易出现唇音不同步、表情僵硬、身体运动不协调等问题。
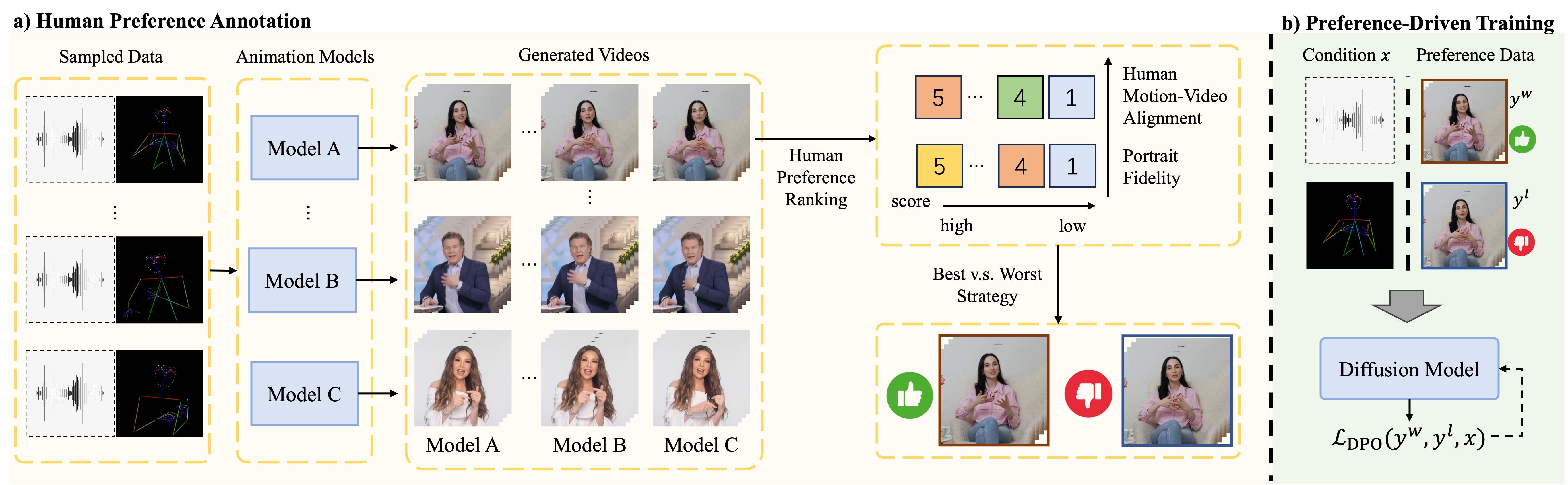
核心思路:论文的核心思路是通过人类偏好对齐来指导扩散模型的训练,使其生成的结果更符合人类的感知。具体来说,通过收集人类对不同人像动画的偏好数据,并利用直接偏好优化(Direct Preference Optimization, DPO)算法,将这些偏好信息融入到模型的训练过程中,从而提升生成结果的质量。同时,为了解决时空分辨率不匹配的问题,提出了时间运动调制方法,以保留高频运动细节。
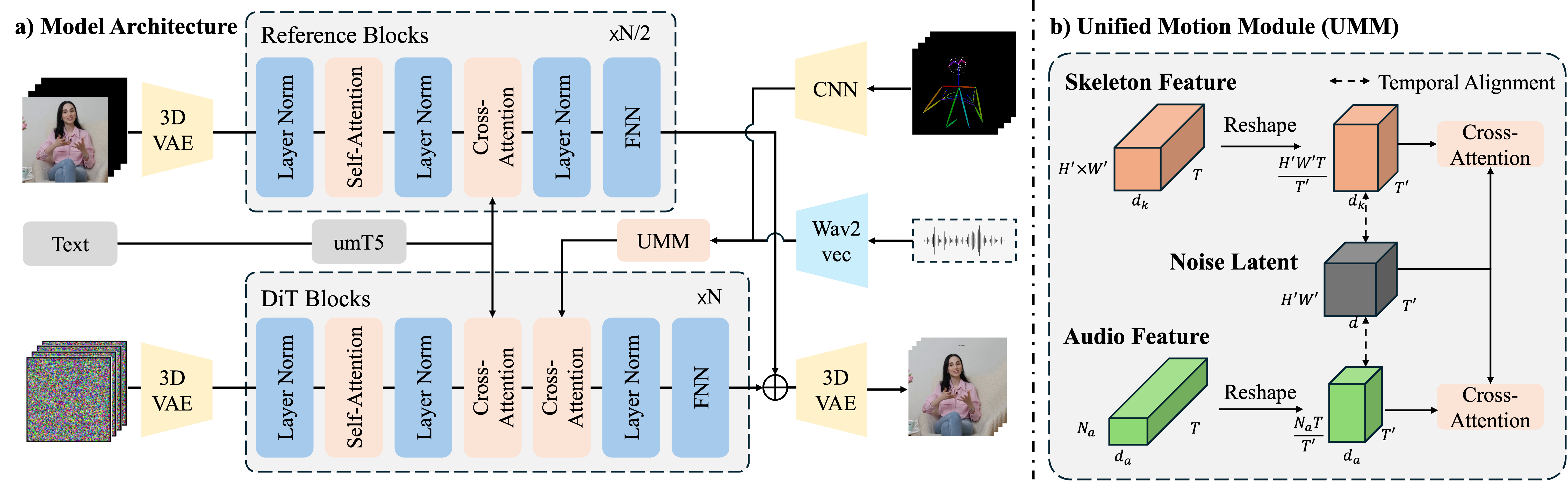
技术框架:整体框架基于扩散模型,包括以下主要模块:1) 运动条件编码器:将音频和骨骼运动信息编码成潜在特征;2) 时间运动调制模块:对运动条件进行处理,解决时空分辨率不匹配问题;3) 扩散模型:基于编码后的运动条件生成人像动画;4) 直接偏好优化模块:根据人类偏好数据,优化扩散模型的参数。整个流程首先将音频和骨骼运动作为输入,经过编码和调制后,输入到扩散模型中生成初始的人像动画,然后利用人类偏好数据对模型进行优化,最终得到高质量的动态人像动画。
关键创新:论文的关键创新在于以下两点:1) 针对以人为中心动画的直接偏好优化:通过收集人类偏好数据,并利用DPO算法,使生成结果更符合人类的感知,提升了人像动画的真实感和自然性。2) 时间运动调制:通过时间通道重分布和比例特征扩展,解决了时空分辨率不匹配问题,保留了高频运动细节,提升了运动的连贯性和真实性。
关键设计:在直接偏好优化方面,论文设计了一个精心策划的人类偏好数据集,用于训练DPO模型。在时间运动调制方面,论文提出了时间通道重分布和比例特征扩展的具体实现方式,以解决时空分辨率不匹配问题。具体的损失函数包括扩散模型的重建损失和DPO的偏好损失。网络结构方面,可以与现有的UNet和DiT-based的人像扩散方法结合使用。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在唇音同步、表情生动性和身体运动连贯性方面均优于基线方法。具体来说,在人类偏好指标方面,该方法取得了显著的提升,表明生成的人像动画更符合人类的感知。此外,消融实验验证了直接偏好优化和时间运动调制模块的有效性。
🎯 应用场景
该研究成果可广泛应用于虚拟现实、增强现实、游戏开发、电影制作等领域。例如,可以用于创建逼真的虚拟角色,提升游戏和电影的沉浸感;也可以用于开发个性化的虚拟助手,提供更自然、更人性化的交互体验。此外,该技术还可以应用于远程教育、远程医疗等领域,实现更生动、更真实的远程沟通。
📄 摘要(原文)
Generating highly dynamic and photorealistic portrait animations driven by audio and skeletal motion remains challenging due to the need for precise lip synchronization, natural facial expressions, and high-fidelity body motion dynamics. We propose a human-preference-aligned diffusion framework that addresses these challenges through two key innovations. First, we introduce direct preference optimization tailored for human-centric animation, leveraging a curated dataset of human preferences to align generated outputs with perceptual metrics for portrait motion-video alignment and naturalness of expression. Second, the proposed temporal motion modulation resolves spatiotemporal resolution mismatches by reshaping motion conditions into dimensionally aligned latent features through temporal channel redistribution and proportional feature expansion, preserving the fidelity of high-frequency motion details in diffusion-based synthesis. The proposed mechanism is complementary to existing UNet and DiT-based portrait diffusion approaches, and experiments demonstrate obvious improvements in lip-audio synchronization, expression vividness, body motion coherence over baseline methods, alongside notable gains in human preference metrics. Our model and source code can be found at: https://github.com/fudan-generative-vision/hallo4.