SemIRNet: A Semantic Irony Recognition Network for Multimodal Sarcasm Detection
作者: Jingxuan Zhou, Yuehao Wu, Yibo Zhang, Yeyubei Zhang, Yunchong Liu, Bolin Huang, Chunhong Yuan
分类: cs.CV, cs.CL, cs.LG
发布日期: 2025-05-28
备注: 5 pages, 3 figures
💡 一句话要点
提出SemIRNet,利用知识融合和跨模态相似度检测提升多模态讽刺识别精度
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态讽刺检测 知识融合 跨模态相似度 ConceptNet 对比学习
📋 核心要点
- 现有方法难以准确捕捉多模态讽刺检测中图像与文本之间的隐式关联。
- SemIRNet通过引入ConceptNet知识库和跨模态语义相似度检测模块来增强模型理解能力。
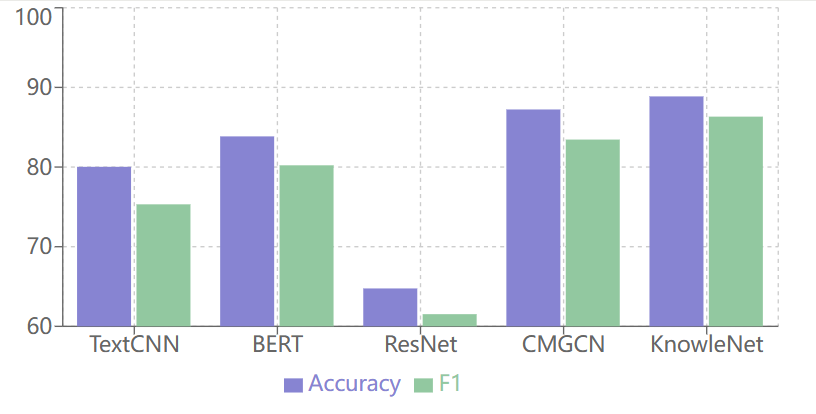
- 实验结果表明,SemIRNet在准确率和F1值上均优于现有方法,证明了其有效性。
📝 摘要(中文)
本文针对多模态讽刺检测任务中难以准确识别图像隐式关联的问题,提出了语义讽刺识别网络(SemIRNet)。该模型包含三个主要创新点:(1)首次引入ConceptNet知识库来获取概念知识,增强模型的常识推理能力;(2)设计了词级别和样本级别两种跨模态语义相似度检测模块,以不同粒度建模图文相关性;(3)引入对比学习损失函数来优化样本特征的空间分布,提高正负样本的可分性。在公开的多模态讽刺检测基准数据集上的实验表明,与现有最优方法相比,该模型的准确率和F1值分别提高了1.64%和2.88%,达到88.87%和86.33%。进一步的消融实验验证了知识融合和语义相似度检测在提高模型性能方面的重要作用。
🔬 方法详解
问题定义:多模态讽刺检测旨在识别包含讽刺意味的图文组合。现有方法在捕捉图像和文本之间微妙的语义关联方面存在不足,尤其是在处理隐式关联时,性能会受到限制。缺乏常识知识和有效的跨模态信息融合是主要痛点。
核心思路:SemIRNet的核心思路是利用外部知识库增强模型的常识推理能力,并通过跨模态语义相似度检测模块来显式地建模图像和文本之间的关联。通过引入ConceptNet,模型可以获取更丰富的概念信息,从而更好地理解讽刺背后的含义。跨模态相似度检测则有助于模型关注图像和文本中相互呼应的关键信息。
技术框架:SemIRNet的整体架构包含以下几个主要模块:1) 特征提取模块:分别提取图像和文本的特征表示;2) 知识融合模块:利用ConceptNet知识库获取概念知识,并将知识融入到文本特征中;3) 跨模态语义相似度检测模块:包含词级别和样本级别两个子模块,分别计算图像和文本在不同粒度上的语义相似度;4) 分类器:基于融合后的特征进行讽刺识别;5) 对比学习损失:优化特征空间,提高正负样本区分度。
关键创新:SemIRNet的关键创新在于以下几点:1) 首次将ConceptNet知识库引入多模态讽刺检测任务,增强了模型的常识推理能力;2) 设计了词级别和样本级别两种跨模态语义相似度检测模块,能够更全面地建模图文相关性;3) 引入对比学习损失函数,优化了特征空间,提高了正负样本的可分性。与现有方法相比,SemIRNet能够更好地捕捉图像和文本之间的隐式关联,从而提高讽刺识别的准确率。
关键设计:在知识融合模块中,论文可能采用了某种注意力机制来选择性地融合ConceptNet提供的知识。在跨模态语义相似度检测模块中,词级别相似度可能通过计算图像区域特征和文本词向量之间的余弦相似度来实现,而样本级别相似度可能通过计算图像和文本全局特征之间的相似度来实现。对比学习损失函数的具体形式未知,但其目的是拉近正样本之间的距离,推远负样本之间的距离。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SemIRNet在多模态讽刺检测基准数据集上取得了显著的性能提升。与现有最优方法相比,SemIRNet的准确率提高了1.64%,达到88.87%,F1值提高了2.88%,达到86.33%。消融实验进一步验证了知识融合和跨模态语义相似度检测模块的有效性,证明了SemIRNet的优越性。
🎯 应用场景
SemIRNet可应用于社交媒体内容审核、舆情分析、智能客服等领域。通过识别讽刺言论,可以更准确地理解用户意图,过滤不良信息,提升用户体验。该研究对于提升机器对人类语言的理解能力具有重要意义,并为构建更智能的人机交互系统奠定基础。
📄 摘要(原文)
Aiming at the problem of difficulty in accurately identifying graphical implicit correlations in multimodal irony detection tasks, this paper proposes a Semantic Irony Recognition Network (SemIRNet). The model contains three main innovations: (1) The ConceptNet knowledge base is introduced for the first time to acquire conceptual knowledge, which enhances the model's common-sense reasoning ability; (2) Two cross-modal semantic similarity detection modules at the word level and sample level are designed to model graphic-textual correlations at different granularities; and (3) A contrastive learning loss function is introduced to optimize the spatial distribution of the sample features, which improves the separability of positive and negative samples. Experiments on a publicly available multimodal irony detection benchmark dataset show that the accuracy and F1 value of this model are improved by 1.64% and 2.88% to 88.87% and 86.33%, respectively, compared with the existing optimal methods. Further ablation experiments verify the important role of knowledge fusion and semantic similarity detection in improving the model performance.