Do You See Me : A Multidimensional Benchmark for Evaluating Visual Perception in Multimodal LLMs
作者: Aditya Kanade, Tanuja Ganu
分类: cs.CV
发布日期: 2025-05-28 (更新: 2025-12-10)
🔗 代码/项目: GITHUB
💡 一句话要点
提出多维基准以评估多模态大语言模型的视觉感知能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉感知 基准评估 人类心理学 推理能力 视觉推理 任务复杂度
📋 核心要点
- 现有的多模态大语言模型在视觉感知方面存在显著不足,尤其是在处理复杂视觉信息时容易出现错误。
- 本文提出了一个名为“Do You See Me”的基准,旨在通过多样化的任务和图像来系统评估MLLM的视觉能力。
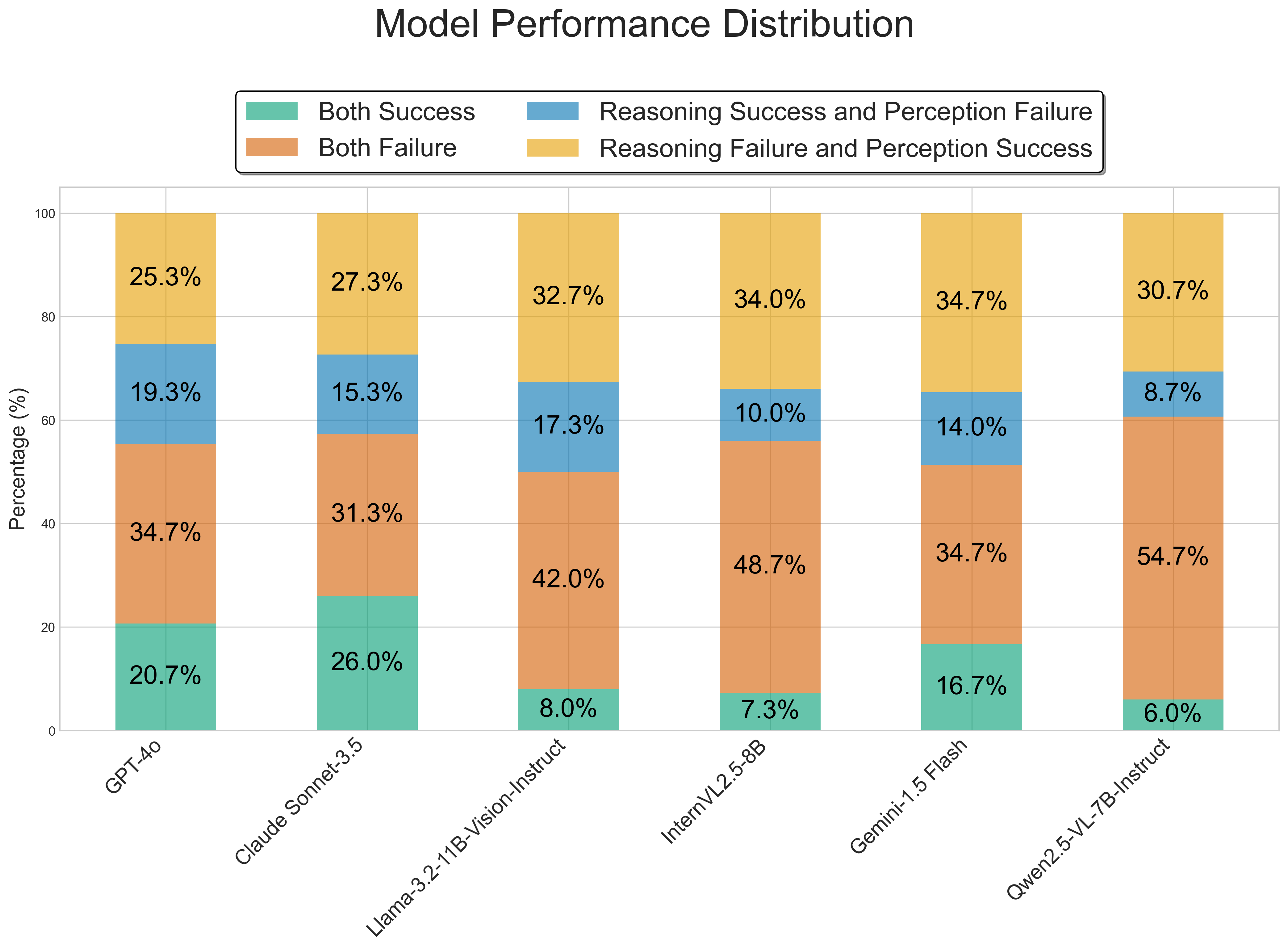
- 实验结果显示,尽管人类在视觉推理任务中表现优异,但顶尖的MLLMs在准确率上远低于人类,尤其在复杂任务中差距更为明显。
📝 摘要(中文)
多模态大语言模型(MLLMs)在推理方面展现出潜力,但其视觉感知能力仍是一个关键瓶颈。研究表明,尽管MLLMs能够给出正确答案,但在视觉元素的解读上存在显著错误。为系统性解决这一问题,本文提出了“Do You See Me”基准,包含1758张图像和2612个问题,涵盖七个受人类心理学启发的子任务,旨在严格评估MLLM的视觉技能。研究发现,尽管人类的准确率达到96.49%,但顶尖的MLLMs平均准确率不足50%,且随着任务复杂度的增加,性能差距迅速扩大。这一发现强调了对具有真正稳健视觉感知能力的MLLMs的迫切需求。
🔬 方法详解
问题定义:本文旨在解决多模态大语言模型在视觉感知方面的不足,尤其是在推理过程中对视觉元素的误解和错误解读。现有方法未能有效识别这些潜在的视觉感知错误,导致模型在回答推理问题时表现不佳。
核心思路:通过构建“Do You See Me”基准,提供一个包含多样化视觉任务和问题的系统性评估框架,以便更好地识别和分析MLLMs在视觉感知中的缺陷。该基准设计灵活,能够控制任务复杂度,从而深入探讨模型的视觉能力。
技术框架:该基准包含1758张图像和2612个问题,分为七个子任务,涵盖2D和3D视觉场景。每个子任务设计有不同的复杂度,以便全面评估模型的视觉推理能力。
关键创新:最重要的创新在于提出了一个可扩展的评估基准,系统地揭示了MLLMs在视觉感知方面的缺陷,尤其是对细节的处理能力不足。与现有方法相比,该基准提供了更为细致的评估标准。
关键设计:在基准设计中,任务的复杂度可控,允许研究者针对不同的视觉感知能力进行深入分析。数据集的构建考虑了人类心理学的启发,确保了任务的多样性和挑战性。
🖼️ 关键图片


📊 实验亮点
实验结果显示,尽管人类在视觉推理任务中的准确率高达96.49%,但顶尖的多模态大语言模型的平均准确率不足50%。在视觉形式恒常性子任务中,准确率从12%提升至45%,表明随着任务复杂度的增加,模型的性能差距显著扩大。
🎯 应用场景
该研究的潜在应用领域包括智能助手、自动驾驶、机器人视觉等多模态交互场景。通过提升多模态大语言模型的视觉感知能力,可以显著改善人机交互的自然性和准确性,推动相关技术的实际应用和发展。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) show reasoning promise, yet their visual perception is a critical bottleneck. Strikingly, MLLMs can produce correct answers even while misinterpreting crucial visual elements, masking these underlying failures. Our preliminary study on a joint perception-reasoning dataset revealed that for one leading MLLM, 29% of its correct answers to reasoning questions still exhibited visual perception errors. To systematically address this, we introduce "Do You See Me", a scalable benchmark with 1,758 images and 2,612 questions. It spans seven human-psychology inspired subtasks in 2D and 3D, featuring controllable complexity to rigorously evaluate MLLM visual skills. Our findings on 3 leading closed-source and 5 major open-source models reveal a stark deficit: humans achieve 96.49% accuracy, while top MLLMs average below 50%. This performance gap widens rapidly with increased task complexity (e.g., from 12% to 45% in the visual form constancy subtask). Further analysis into the root causes suggests that failures stem from challenges like misallocated visual attention and the instability of internal representations for fine-grained details, especially at or below encoder patch resolution. This underscores an urgent need for MLLMs with truly robust visual perception. The benchmark dataset, source code and evaluation scripts are available at https://github.com/microsoft/Do-You-See-Me.