3DLLM-Mem: Long-Term Spatial-Temporal Memory for Embodied 3D Large Language Model
作者: Wenbo Hu, Yining Hong, Yanjun Wang, Leison Gao, Zibu Wei, Xingcheng Yao, Nanyun Peng, Yonatan Bitton, Idan Szpektor, Kai-Wei Chang
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2025-05-28 (更新: 2025-12-17)
备注: demos at: https://3dllm-mem.github.io
💡 一句话要点
提出3DLLM-Mem,用于具身3D大语言模型中的长期时空记忆建模
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 大语言模型 长期记忆 时空推理 动态记忆管理 3D环境 情景记忆 3DMem-Bench
📋 核心要点
- 现有LLM在动态3D环境中缺乏有效的长期时空记忆建模,难以进行复杂任务的规划和行动。
- 3DLLM-Mem通过动态管理和融合情景记忆中的时空特征,使智能体能够关注任务相关信息,提高记忆效率。
- 实验表明,3DLLM-Mem在3DMem-Bench上取得了SOTA性能,在最具挑战性的任务中成功率提升了16.5%。
📝 摘要(中文)
本文提出了一种用于具身3D大语言模型(LLM)的长期时空记忆建模方法,旨在解决当前LLM在动态、多房间3D环境中进行有效规划和行动的难题。为此,首先构建了一个名为3DMem-Bench的综合基准测试,包含超过26,000条轨迹和2,892个具身任务、问答和描述生成,用于评估智能体在3D环境中基于长期记忆进行推理的能力。其次,提出了3DLLM-Mem,一种用于具身时空推理和行动的新型动态记忆管理和融合模型。该模型使用工作记忆token(代表当前观察)作为查询,选择性地关注并融合来自情景记忆(存储过去观察和交互)的最有用的空间和时间特征。实验结果表明,3DLLM-Mem在各种任务中实现了最先进的性能,在3DMem-Bench最具挑战性的真实场景具身任务中,成功率比最强的基线提高了16.5%。
🔬 方法详解
问题定义:现有的大语言模型在具身智能任务中,尤其是在复杂的、长时程的3D环境中,难以有效地进行规划和行动。这主要是因为它们缺乏对3D空间和时间信息的有效记忆和推理能力,无法像人类一样利用长期记忆来指导当前的行为。现有方法难以在长时程任务中保持记忆的连贯性和相关性,导致性能下降。
核心思路:论文的核心思路是引入一种动态的记忆管理和融合机制,使得LLM能够选择性地关注和利用过去经验中最相关的空间和时间信息。通过将当前观察作为查询,从情景记忆中检索相关信息,并将这些信息融合到当前的工作记忆中,从而增强LLM的推理和行动能力。
技术框架:3DLLM-Mem的整体框架包含以下几个主要模块:1) 情景记忆模块:用于存储过去的观察和交互信息,形成长期记忆。2) 工作记忆模块:用于存储当前的观察和状态信息。3) 记忆选择模块:使用工作记忆中的token作为查询,从情景记忆中选择最相关的空间和时间特征。4) 记忆融合模块:将选择的特征融合到工作记忆中,增强LLM的推理能力。整个流程是动态循环的,每一步的观察都会更新工作记忆,并用于从情景记忆中检索信息。
关键创新:该方法最重要的创新点在于动态的记忆管理和融合机制。与传统的静态记忆方法不同,3DLLM-Mem能够根据当前的任务需求,选择性地关注和利用过去经验中最相关的信息,从而提高记忆效率和推理能力。此外,该方法还引入了3DMem-Bench,这是一个专门用于评估具身智能体在3D环境中长期记忆推理能力的基准测试。
关键设计:在记忆选择模块中,使用了注意力机制来计算工作记忆和情景记忆之间的相关性。具体来说,工作记忆的token作为query,情景记忆的特征作为key和value,通过计算query和key之间的相似度来确定注意力权重,然后将value加权求和,得到选择的特征。在记忆融合模块中,使用了简单的加权平均方法将选择的特征融合到工作记忆中。损失函数方面,使用了标准的交叉熵损失函数来训练LLM的参数。
🖼️ 关键图片
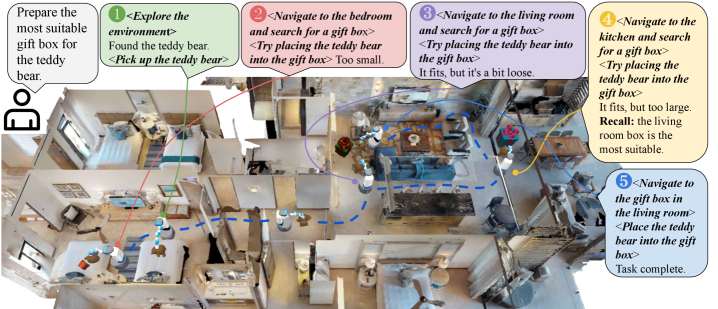
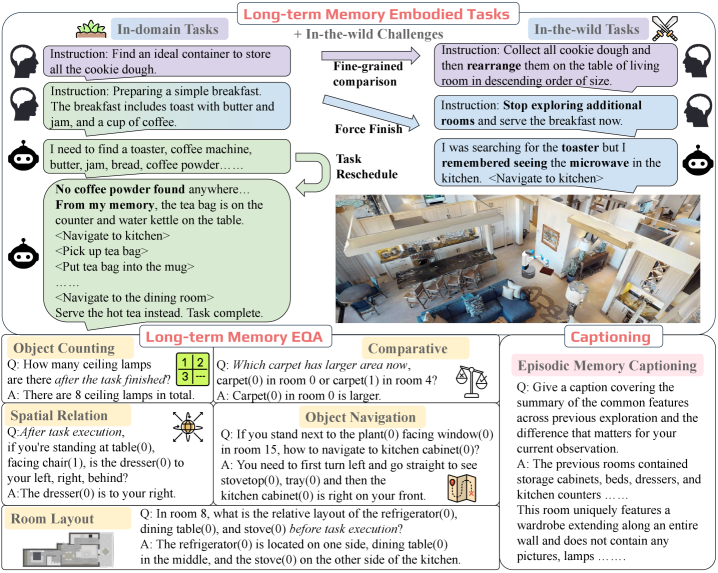
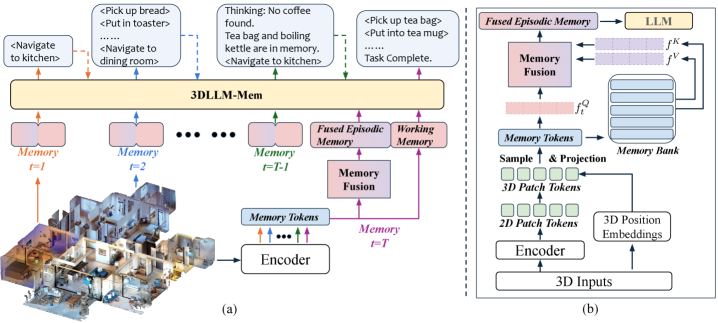
📊 实验亮点
3DLLM-Mem在3DMem-Bench基准测试上取得了显著的性能提升。在最具挑战性的真实场景具身任务中,3DLLM-Mem的成功率比最强的基线提高了16.5%。实验结果表明,该方法能够有效地利用长期记忆来指导智能体的行为,从而提高其在复杂环境中的适应能力和任务完成能力。此外,3DMem-Bench的发布也为该领域的研究提供了新的评估标准。
🎯 应用场景
该研究成果可应用于各种需要长期记忆和空间推理的具身智能任务,例如家庭服务机器人、智能助手、自动驾驶等。通过增强LLM的记忆能力,可以使这些智能体更好地理解和适应复杂环境,从而完成更复杂的任务。未来,该技术还可以扩展到虚拟现实、游戏等领域,提升用户体验。
📄 摘要(原文)
Humans excel at performing complex tasks by leveraging long-term memory across temporal and spatial experiences. In contrast, current Large Language Models (LLMs) struggle to effectively plan and act in dynamic, multi-room 3D environments. We posit that part of this limitation is due to the lack of proper 3D spatial-temporal memory modeling in LLMs. To address this, we first introduce 3DMem-Bench, a comprehensive benchmark comprising over 26,000 trajectories and 2,892 embodied tasks, question-answering and captioning, designed to evaluate an agent's ability to reason over long-term memory in 3D environments. Second, we propose 3DLLM-Mem, a novel dynamic memory management and fusion model for embodied spatial-temporal reasoning and actions in LLMs. Our model uses working memory tokens, which represents current observations, as queries to selectively attend to and fuse the most useful spatial and temporal features from episodic memory, which stores past observations and interactions. Our approach allows the agent to focus on task-relevant information while maintaining memory efficiency in complex, long-horizon environments. Experimental results demonstrate that 3DLLM-Mem achieves state-of-the-art performance across various tasks, outperforming the strongest baselines by 16.5% in success rate on 3DMem-Bench's most challenging in-the-wild embodied tasks.