On Geometry-Enhanced Parameter-Efficient Fine-Tuning for 3D Scene Segmentation
作者: Liyao Tang, Zhe Chen, Dacheng Tao
分类: cs.CV
发布日期: 2025-05-28 (更新: 2025-11-20)
备注: Neurips 2025; available at https://github.com/LiyaoTang/GEM
🔗 代码/项目: GITHUB
💡 一句话要点
提出几何增强的参数高效微调方法GEM,用于3D场景分割
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D场景分割 参数高效微调 点云Transformer 几何编码 局部位置编码 注意力机制 预训练模型
📋 核心要点
- 现有3D点云模型的参数高效微调方法忽略了点云的局部空间结构和全局几何上下文信息。
- 提出几何编码混合器(GEM),通过融合局部位置编码和轻量级潜在注意力机制来捕获几何信息。
- 实验结果表明,GEM仅更新少量参数即可达到甚至超过全参数微调的性能,并显著降低计算成本。
📝 摘要(中文)
大规模预训练点云模型的出现显著提升了3D场景理解能力,但将这些模型适配到特定下游任务通常需要完全微调,导致高昂的计算和存储成本。参数高效微调(PEFT)技术在自然语言处理和2D视觉任务中表现出色,但由于显著的几何和空间分布差异,直接应用于3D点云模型会表现不佳。现有的PEFT方法通常将点视为无序的token,忽略了3D建模中重要的局部空间结构和全局几何上下文。为了弥合这一差距,我们引入了几何编码混合器(GEM),这是一种专门为3D点云Transformer设计的几何感知PEFT模块。GEM显式地集成了细粒度的局部位置编码和一个轻量级的潜在注意力机制,以捕获全面的全局上下文,从而有效地解决了空间和几何分布不匹配的问题。大量实验表明,GEM在仅更新1.6%的模型参数的情况下,实现了与完全微调相当甚至超过完全微调的性能,低于其他PEFT方法。我们的方法显著减少了训练时间和内存需求,从而为大规模3D点云模型的高效、可扩展和几何感知的微调树立了新的基准。
🔬 方法详解
问题定义:现有的大规模预训练点云模型在应用于特定下游任务时,通常需要进行全参数微调,这带来了巨大的计算和存储开销。现有的参数高效微调(PEFT)方法,如在NLP和2D视觉中常用的方法,直接应用于3D点云模型时性能不佳,因为它们忽略了3D点云数据中重要的几何结构和空间分布信息。这些方法通常将点云视为无序的token序列,没有充分利用局部空间关系和全局几何上下文。
核心思路:论文的核心思路是设计一个几何感知的参数高效微调模块,即几何编码混合器(GEM),来显式地建模和利用3D点云的几何信息。GEM通过融合细粒度的局部位置编码和轻量级的潜在注意力机制,来捕获点云的局部空间结构和全局几何上下文。这样可以有效地解决由于几何和空间分布差异导致的性能下降问题。
技术框架:GEM作为一个独立的模块,可以插入到现有的3D点云Transformer模型中。整体流程如下:首先,输入点云数据经过原始模型的特征提取层。然后,将提取的特征输入到GEM模块中,GEM模块利用局部位置编码和潜在注意力机制来增强特征的几何信息。最后,将增强后的特征输入到模型的后续层进行下游任务的预测。
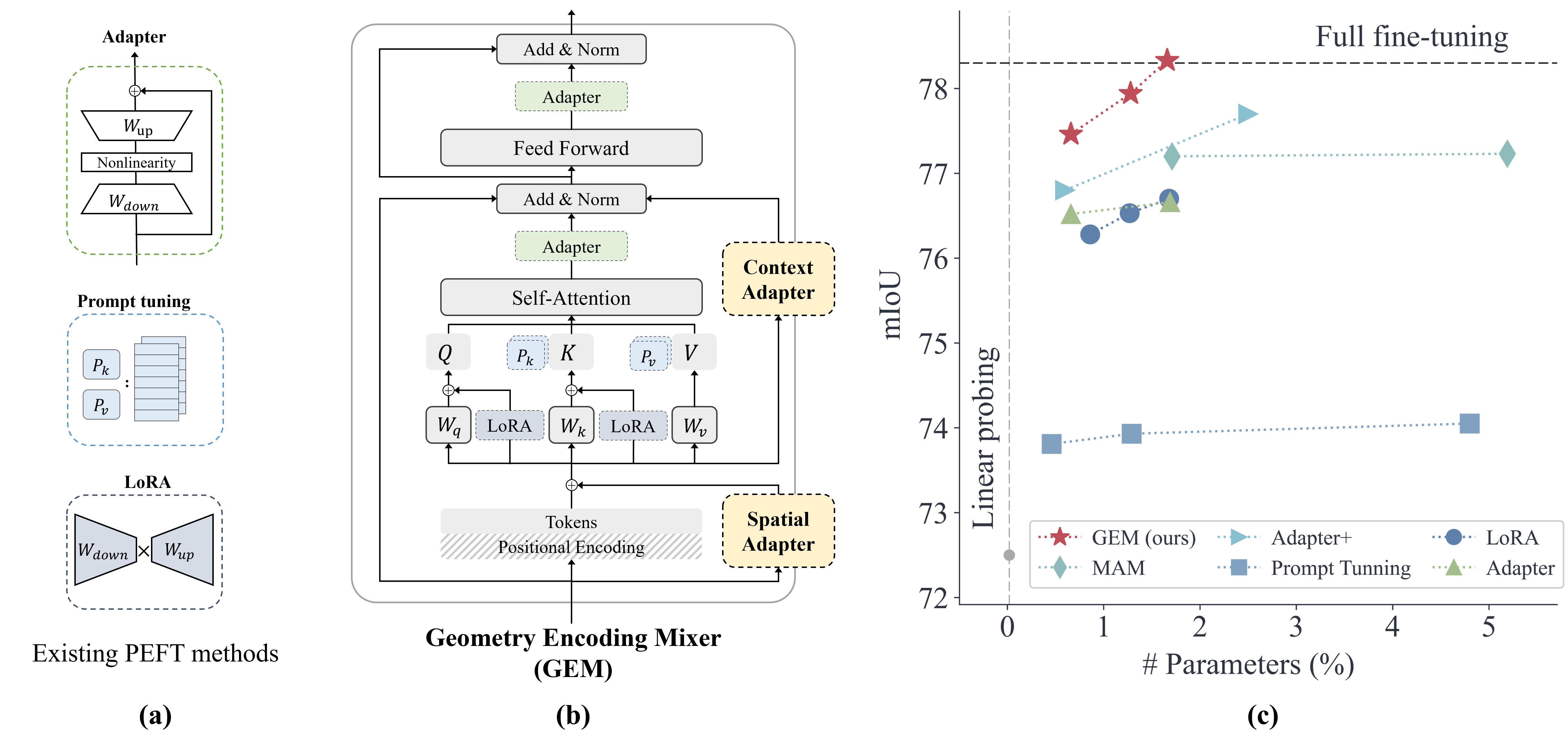
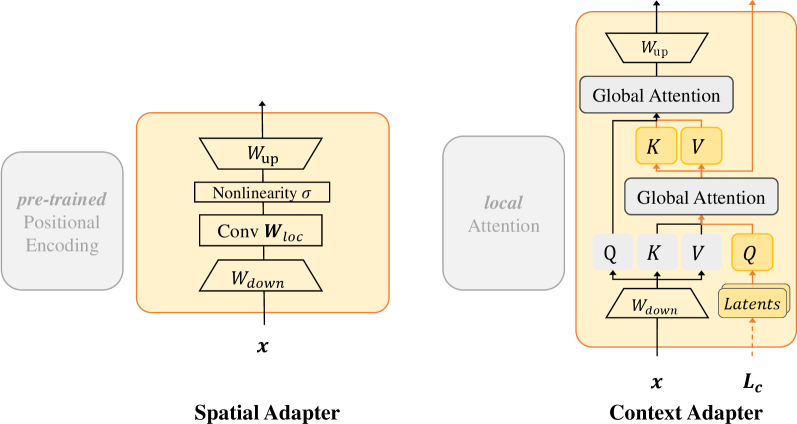
关键创新:论文的关键创新在于提出了几何编码混合器(GEM),这是一个专门为3D点云Transformer设计的几何感知PEFT模块。GEM与现有PEFT方法的主要区别在于,它显式地建模和利用了3D点云的几何信息,而现有方法通常忽略了这些信息。GEM通过融合局部位置编码和潜在注意力机制,有效地捕获了点云的局部空间结构和全局几何上下文。
关键设计:GEM的关键设计包括:1) 细粒度的局部位置编码,用于编码每个点的局部空间位置信息。2) 轻量级的潜在注意力机制,用于捕获点云的全局几何上下文。3) GEM模块的插入位置,通常选择在模型的中间层,以便在不影响模型原始特征提取能力的前提下,增强特征的几何信息。具体的参数设置和网络结构细节可以在论文的实验部分找到。
🖼️ 关键图片
📊 实验亮点
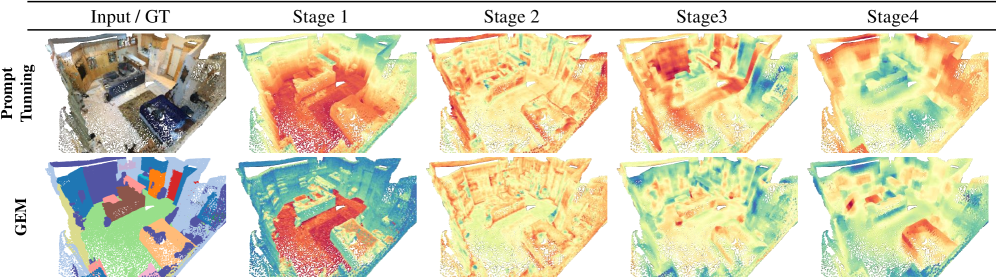
实验结果表明,GEM在ScanNetV2和S3DIS数据集上取得了显著的性能提升。在ScanNetV2数据集上,GEM在仅更新1.6%的模型参数的情况下,实现了与全参数微调相当甚至超过全参数微调的性能。与其他PEFT方法相比,GEM在参数效率和性能方面都表现出优势。例如,与Adapter方法相比,GEM在更新更少参数的情况下,取得了更高的分割精度。
🎯 应用场景
该研究成果可广泛应用于各种需要3D场景理解的领域,例如自动驾驶、机器人导航、增强现实、虚拟现实、城市规划和建筑设计等。通过高效地微调大规模预训练点云模型,可以降低模型部署和维护的成本,加速3D场景理解技术的普及和应用。未来,该方法可以进一步扩展到其他3D数据类型,例如网格数据和体素数据。
📄 摘要(原文)
The emergence of large-scale pre-trained point cloud models has significantly advanced 3D scene understanding, but adapting these models to specific downstream tasks typically demands full fine-tuning, incurring high computational and storage costs. Parameter-efficient fine-tuning (PEFT) techniques, successful in natural language processing and 2D vision tasks, would underperform when naively applied to 3D point cloud models due to significant geometric and spatial distribution shifts. Existing PEFT methods commonly treat points as orderless tokens, neglecting important local spatial structures and global geometric contexts in 3D modeling. To bridge this gap, we introduce the Geometric Encoding Mixer (GEM), a novel geometry-aware PEFT module specifically designed for 3D point cloud transformers. GEM explicitly integrates fine-grained local positional encodings with a lightweight latent attention mechanism to capture comprehensive global context, thereby effectively addressing the spatial and geometric distribution mismatch. Extensive experiments demonstrate that GEM achieves performance comparable to or sometimes even exceeding full fine-tuning, while only updating 1.6% of the model's parameters, fewer than other PEFT methods. With significantly reduced training time and memory requirements, our approach thus sets a new benchmark for efficient, scalable, and geometry-aware fine-tuning of large-scale 3D point cloud models. Code is available at https://github.com/LiyaoTang/GEM.