Zero-Shot 3D Visual Grounding from Vision-Language Models
作者: Rong Li, Shijie Li, Lingdong Kong, Xulei Yang, Junwei Liang
分类: cs.CV, cs.RO
发布日期: 2025-05-28
备注: 3D-LLM/VLA @ CVPR 2025; Project Page at https://seeground.github.io/
💡 一句话要点
提出SeeGround,利用2D视觉-语言模型实现零样本3D视觉定位
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D视觉定位 零样本学习 视觉-语言模型 跨模态学习 场景理解
📋 核心要点
- 现有3D视觉定位方法依赖大量标注数据和预定义类别,难以扩展到开放世界场景。
- SeeGround利用2D视觉-语言模型,结合查询对齐的渲染视图和空间增强文本描述,实现零样本定位。
- 实验表明,SeeGround显著优于现有零样本方法,并在ScanRefer和Nr3D数据集上取得了7.7%和7.1%的性能提升。
📝 摘要(中文)
3D视觉定位(3DVG)旨在利用自然语言描述在3D场景中定位目标对象,从而支持增强现实和机器人等下游应用。现有方法通常依赖于带标签的3D数据和预定义的类别,限制了其在开放世界环境中的可扩展性。我们提出了SeeGround,一个零样本3DVG框架,它利用2D视觉-语言模型(VLMs)来绕过对3D特定训练的需求。为了弥合模态差距,我们引入了一种混合输入格式,将查询对齐的渲染视图与空间增强的文本描述配对。我们的框架包含两个核心组件:一个透视自适应模块,根据查询动态选择最佳视点;以及一个融合对齐模块,集成视觉和空间信号以提高定位精度。在ScanRefer和Nr3D上的大量评估表明,SeeGround在现有零样本基线上实现了显著改进——分别超过它们7.7%和7.1%——甚至可以与完全监督的替代方案相媲美,展示了在具有挑战性的条件下的强大泛化能力。
🔬 方法详解
问题定义:3D视觉定位旨在根据自然语言描述在3D场景中定位目标物体。现有方法的痛点在于需要大量的3D标注数据和预定义的物体类别,这限制了它们在开放世界场景中的应用,因为获取和维护这些标注成本高昂,且难以覆盖所有可能的物体类别。
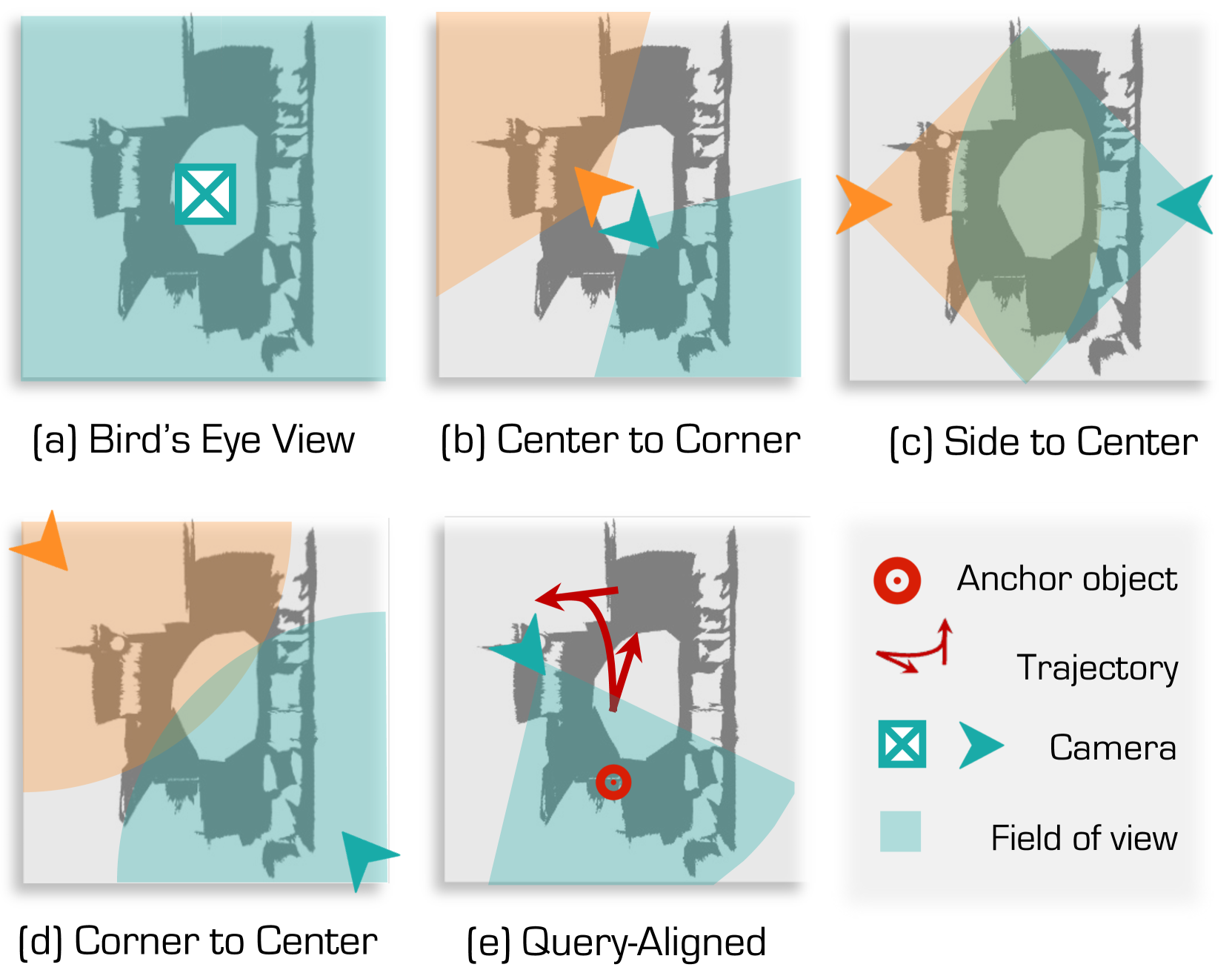
核心思路:SeeGround的核心思路是利用预训练的2D视觉-语言模型(VLM)的强大语义理解能力,避免直接在3D数据上进行训练。通过将3D场景渲染成2D图像,并结合空间信息增强的文本描述,将3D视觉定位问题转化为2D视觉-语言匹配问题。这样就可以利用VLM的泛化能力,实现零样本的3D视觉定位。
技术框架:SeeGround框架主要包含两个核心模块:透视自适应模块和融合对齐模块。首先,透视自适应模块根据输入的自然语言查询,动态选择最能体现目标物体的3D场景视点,生成查询对齐的渲染视图。然后,融合对齐模块将这些渲染视图与空间信息增强的文本描述进行融合,利用VLM进行视觉-语言匹配,从而定位目标物体。
关键创新:SeeGround的关键创新在于:1) 提出了一种混合输入格式,将查询对齐的渲染视图与空间增强的文本描述相结合,弥合了2D视觉和3D空间之间的模态差距。2) 设计了透视自适应模块,能够根据查询动态选择最佳视点,提高定位精度。3) 利用预训练的2D VLM,实现了零样本的3D视觉定位,无需3D特定训练数据。
关键设计:透视自适应模块通过计算不同视点下渲染图像与文本描述之间的相似度,选择相似度最高的视点。空间增强的文本描述包括目标物体的位置、大小和方向等信息。融合对齐模块使用Transformer结构,将视觉特征和文本特征进行融合,并通过对比学习损失函数来优化模型。
🖼️ 关键图片


📊 实验亮点
SeeGround在ScanRefer和Nr3D数据集上取得了显著的性能提升,分别超过现有零样本基线7.7%和7.1%,甚至可以与完全监督的替代方案相媲美。这表明SeeGround具有强大的泛化能力和实用价值,能够在复杂的3D场景中实现精确的零样本视觉定位。
🎯 应用场景
该研究成果可广泛应用于增强现实、机器人导航、智能家居等领域。例如,在AR应用中,用户可以通过语音指令快速定位房间内的特定物品;在机器人导航中,机器人可以根据自然语言指令找到目标物体并执行相应操作;在智能家居中,用户可以通过语音控制家电的位置和状态。
📄 摘要(原文)
3D Visual Grounding (3DVG) seeks to locate target objects in 3D scenes using natural language descriptions, enabling downstream applications such as augmented reality and robotics. Existing approaches typically rely on labeled 3D data and predefined categories, limiting scalability to open-world settings. We present SeeGround, a zero-shot 3DVG framework that leverages 2D Vision-Language Models (VLMs) to bypass the need for 3D-specific training. To bridge the modality gap, we introduce a hybrid input format that pairs query-aligned rendered views with spatially enriched textual descriptions. Our framework incorporates two core components: a Perspective Adaptation Module that dynamically selects optimal viewpoints based on the query, and a Fusion Alignment Module that integrates visual and spatial signals to enhance localization precision. Extensive evaluations on ScanRefer and Nr3D confirm that SeeGround achieves substantial improvements over existing zero-shot baselines -- outperforming them by 7.7% and 7.1%, respectively -- and even rivals fully supervised alternatives, demonstrating strong generalization under challenging conditions.