Learning World Models for Interactive Video Generation
作者: Taiye Chen, Xun Hu, Zihan Ding, Chi Jin
分类: cs.CV, cs.AI
发布日期: 2025-05-28 (更新: 2025-10-29)
备注: Project page: https://sites.google.com/view/vrag
💡 一句话要点
提出VRAG,通过视频检索增强生成实现交互式长视频生成的世界模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 视频生成 世界模型 交互式生成 检索增强 自回归模型
📋 核心要点
- 现有长视频生成模型在交互性和时空连贯性方面存在不足,主要受限于复合误差和内存机制。
- 论文提出视频检索增强生成(VRAG),通过显式全局状态条件来减少复合误差并提高时空一致性。
- 实验表明,VRAG优于朴素自回归生成和简单的检索增强生成,验证了其在长视频生成中的有效性。
📝 摘要(中文)
为了通过动作选择进行有效的未来规划,基础世界模型必须具备交互性并保持时空连贯性。然而,目前的长视频生成模型由于复合误差和内存机制不足这两个主要挑战,其固有的世界建模能力有限。本文通过额外的动作条件和自回归框架增强了图像到视频模型的交互能力,并揭示了复合误差在自回归视频生成中是不可避免的,而内存机制不足会导致世界模型的不连贯。因此,本文提出了一种带有显式全局状态条件的视频检索增强生成(VRAG),它显著减少了长期复合误差,并提高了世界模型的时空一致性。相比之下,具有扩展上下文窗口和检索增强生成的朴素自回归生成在视频生成方面效果较差,这主要是由于当前视频模型的上下文学习能力有限。本文阐明了视频世界模型中的根本挑战,并为改进具有内部世界建模能力的视频生成模型建立了一个全面的基准。
🔬 方法详解
问题定义:论文旨在解决长视频生成中世界模型存在的两个主要问题:一是由于自回归生成方式导致的复合误差累积,使得视频内容逐渐偏离预期;二是现有模型的记忆机制不足,导致生成的视频在时空上不连贯,缺乏长期一致性。现有方法,如扩展上下文窗口或简单的检索增强,无法有效解决这些问题。
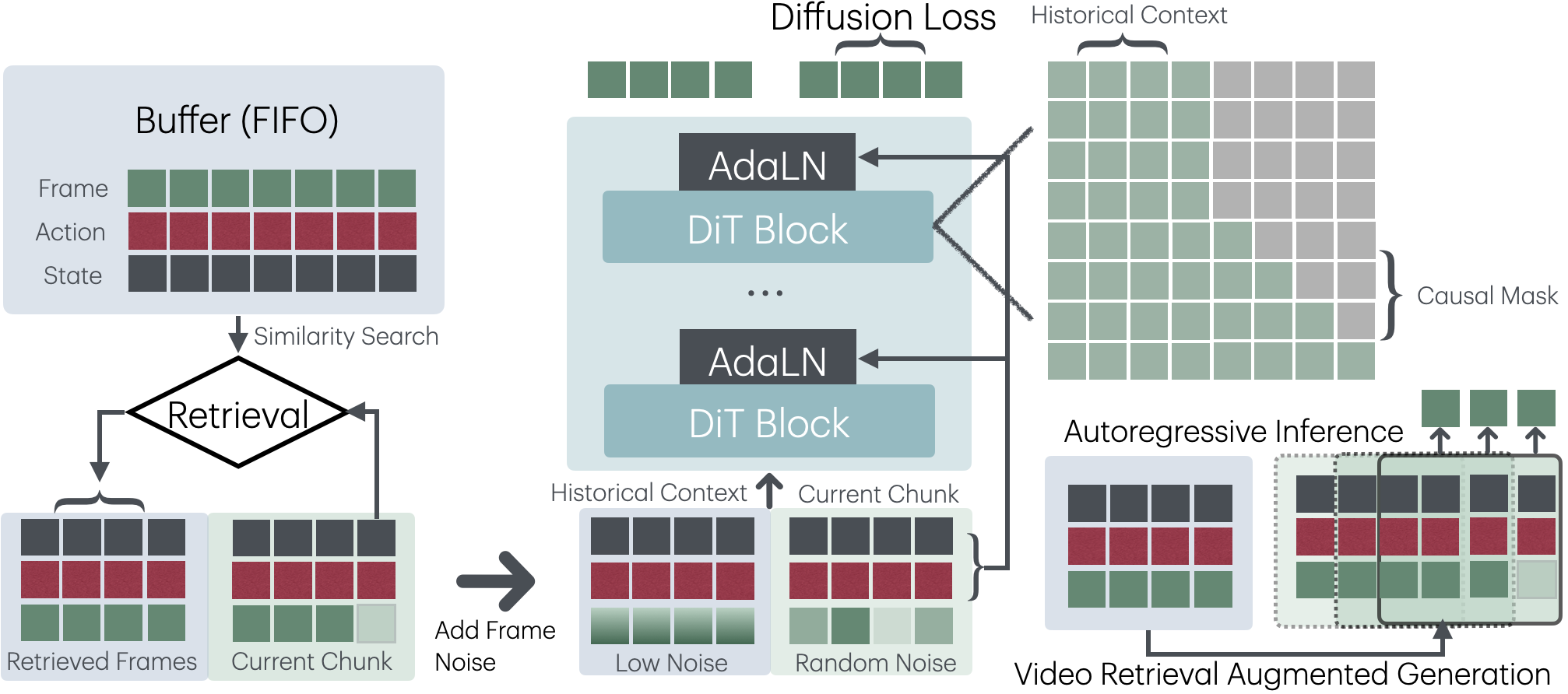
核心思路:论文的核心思路是利用视频检索增强生成(VRAG)来显式地建模全局状态,从而减少复合误差并提高时空一致性。通过检索与当前状态相关的视频片段,并将这些片段的信息融入到生成过程中,模型可以更好地理解和预测视频的长期演变。
技术框架:VRAG框架主要包含以下几个模块:1) 图像编码器:将初始图像编码为潜在表示。2) 动作编码器:将用户指定的动作序列编码为动作表示。3) 视频检索模块:根据当前状态(包括图像表示和动作表示)从视频数据库中检索相关的视频片段。4) 检索增强生成器:利用检索到的视频片段的信息,结合图像表示和动作表示,生成下一帧视频。整个过程是自回归的,即生成的每一帧都会作为下一步生成的基础。
关键创新:VRAG的关键创新在于显式地利用视频检索来增强生成过程。与传统的自回归生成方法相比,VRAG能够从外部知识库中获取信息,从而减少复合误差并提高生成视频的时空一致性。此外,VRAG还通过显式地建模全局状态,使得模型能够更好地理解和预测视频的长期演变。
关键设计:视频检索模块使用余弦相似度来衡量当前状态与视频数据库中视频片段之间的相关性。检索增强生成器可以使用Transformer或其他序列到序列模型来实现。损失函数可以包括生成损失(例如,像素级别的均方误差)和检索损失(例如,对比学习损失),以鼓励模型检索到相关的视频片段。
🖼️ 关键图片


📊 实验亮点
实验结果表明,VRAG在长视频生成任务上显著优于基线方法。具体来说,VRAG在时空一致性指标上取得了显著提升,并且能够生成更逼真、更符合用户意图的视频内容。与Naive autoregressive generation with extended context windows和retrieval-augmented generation相比,VRAG展现出更强的世界建模能力。
🎯 应用场景
该研究成果可应用于视频编辑、游戏开发、虚拟现实等领域。例如,可以根据用户的交互指令生成个性化的视频内容,或者创建具有高度真实感和交互性的虚拟环境。此外,该技术还可以用于训练机器人,使其能够更好地理解和预测周围环境的变化。
📄 摘要(原文)
Foundational world models must be both interactive and preserve spatiotemporal coherence for effective future planning with action choices. However, present models for long video generation have limited inherent world modeling capabilities due to two main challenges: compounding errors and insufficient memory mechanisms. We enhance image-to-video models with interactive capabilities through additional action conditioning and autoregressive framework, and reveal that compounding error is inherently irreducible in autoregressive video generation, while insufficient memory mechanism leads to incoherence of world models. We propose video retrieval augmented generation (VRAG) with explicit global state conditioning, which significantly reduces long-term compounding errors and increases spatiotemporal consistency of world models. In contrast, naive autoregressive generation with extended context windows and retrieval-augmented generation prove less effective for video generation, primarily due to the limited in-context learning capabilities of current video models. Our work illuminates the fundamental challenges in video world models and establishes a comprehensive benchmark for improving video generation models with internal world modeling capabilities.