CAST: Contrastive Adaptation and Distillation for Semi-Supervised Instance Segmentation
作者: Pardis Taghavi, Tian Liu, Renjie Li, Reza Langari, Zhengzhong Tu
分类: cs.CV, cs.AI
发布日期: 2025-05-28 (更新: 2025-10-08)
💡 一句话要点
提出CAST框架,通过对比自适应和蒸馏提升半监督实例分割性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 半监督学习 实例分割 知识蒸馏 对比学习 领域自适应
📋 核心要点
- 实例分割依赖大量标注数据和高计算量模型,半监督学习旨在降低标注成本。
- CAST框架利用对比学习和知识蒸馏,将预训练视觉模型迁移到小型专家模型,提升性能。
- 实验表明,CAST在Cityscapes和ADE20K数据集上显著优于现有半监督知识蒸馏方法。
📝 摘要(中文)
实例分割需要昂贵的像素级标注和计算成本高的模型。我们提出了CAST,一个半监督知识蒸馏(SSKD)框架,它使用有限的标注数据和大量的未标注数据,将预训练的视觉基础模型(VFM)压缩成紧凑的专家模型。CAST分为三个阶段:(1)通过对比校准的自训练进行VFM的领域自适应,(2)通过统一的多目标损失进行知识转移,(3)学生模型细化以减轻残余伪标签偏差。CAST的核心是实例感知的像素级对比损失,它融合了mask和类别分数,以提取信息丰富的负样本并强制执行清晰的实例间间隔。通过在自适应和蒸馏过程中保持这种对比信号,我们对齐了教师和学生模型的嵌入,并充分利用了未标注图像。在Cityscapes和ADE20K上,我们体积缩小约11倍的学生模型比其零样本VFM教师模型分别提高了+8.5和+7.1 AP,超过了自适应教师模型+3.4和+1.5 AP,并且在两个基准测试中进一步优于最先进的SSKD方法。
🔬 方法详解
问题定义:实例分割任务需要大量的像素级标注,标注成本高昂。同时,高性能的实例分割模型通常计算量巨大,难以部署到资源受限的设备上。现有的半监督知识蒸馏方法在利用未标注数据时,容易受到伪标签噪声的影响,导致性能提升有限。
核心思路:CAST框架的核心思路是利用对比学习来增强教师模型和学生模型之间的特征对齐,从而更有效地进行知识蒸馏。通过实例感知的像素级对比损失,模型能够学习到更具区分性的特征表示,从而提高伪标签的质量和蒸馏效果。同时,通过自适应和蒸馏两个阶段,逐步将知识从大型预训练模型迁移到小型学生模型。
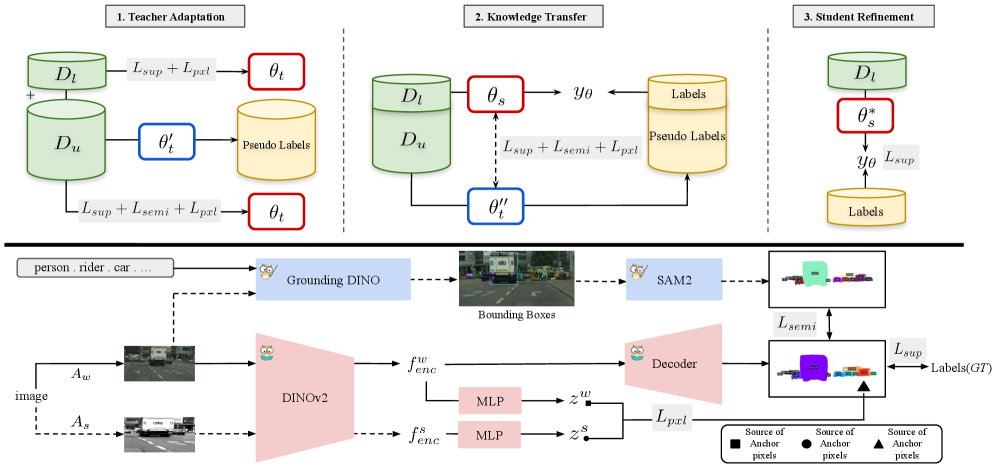
技术框架:CAST框架包含三个主要阶段:1) 领域自适应:使用对比校准的自训练方法,将预训练的视觉基础模型(VFM)适应到目标领域。2) 知识转移:通过统一的多目标损失函数,将知识从教师模型(VFM)转移到学生模型。3) 学生模型细化:通过减轻残余伪标签偏差的方法,进一步提升学生模型的性能。
关键创新:CAST的关键创新在于提出了实例感知的像素级对比损失。该损失函数融合了mask和类别分数,能够提取信息丰富的负样本,并强制执行清晰的实例间间隔。与传统的对比损失不同,CAST的对比损失是实例感知的,能够更好地处理实例分割任务中的复杂场景。
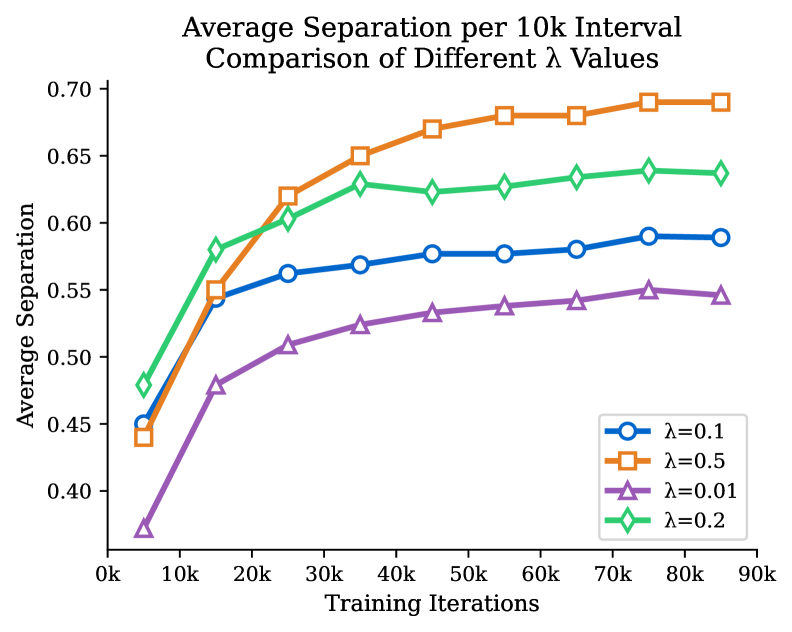
关键设计:实例感知的像素级对比损失是CAST的关键设计。该损失函数的计算方式如下:首先,对于每个像素,计算其特征向量与同一实例内其他像素特征向量的相似度,以及与不同实例像素特征向量的相似度。然后,通过对比损失函数,鼓励同一实例内的像素特征向量更加相似,而不同实例的像素特征向量更加不同。此外,CAST还使用了多目标损失函数,包括分割损失、分类损失和对比损失,以平衡不同任务之间的学习。
🖼️ 关键图片
📊 实验亮点
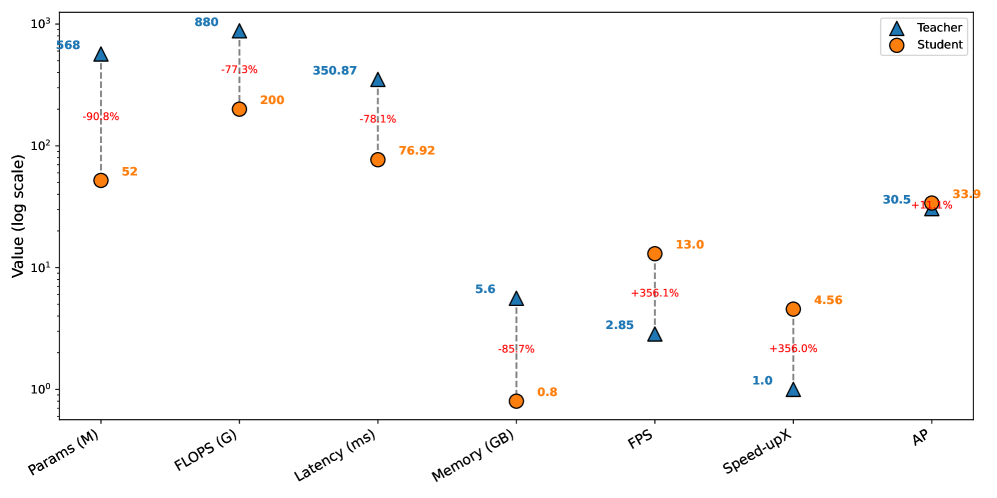
CAST框架在Cityscapes和ADE20K数据集上取得了显著的性能提升。在Cityscapes上,CAST的学生模型比零样本VFM教师模型提高了+8.5 AP,超过了自适应教师模型+3.4 AP。在ADE20K上,CAST的学生模型比零样本VFM教师模型提高了+7.1 AP,超过了自适应教师模型+1.5 AP。同时,CAST还优于现有的半监督知识蒸馏方法。
🎯 应用场景
CAST框架可应用于自动驾驶、医学图像分析、遥感图像处理等领域,降低实例分割任务的标注成本,并实现高性能模型的轻量化部署。该方法能够有效利用未标注数据,提升模型在实际应用场景中的泛化能力,具有重要的实际应用价值。
📄 摘要(原文)
Instance segmentation demands costly per-pixel annotations and computationally expensive models. We introduce CAST, a semi-supervised knowledge distillation (SSKD) framework that compresses pre-trained vision foundation models (VFM) into compact experts using limited labeled and abundant unlabeled data. CAST unfolds in three stages: (1) domain adaptation of the VFM(s) via self-training with contrastive calibration, (2) knowledge transfer through a unified multi-objective loss, and (3) student refinement to mitigate residual pseudo-label bias. Central to CAST is an \emph{instance-aware pixel-wise contrastive loss} that fuses mask and class scores to extract informative negatives and enforce clear inter-instance margins. By maintaining this contrastive signal across both adaptation and distillation, we align teacher and student embeddings and fully leverage unlabeled images. On Cityscapes and ADE20K, our ~11x smaller student improves over its zero-shot VFM teacher(s) by +8.5 and +7.1 AP, surpasses adapted teacher(s) by +3.4 and +1.5 AP, and further outperforms state-of-the-art SSKD methods on both benchmarks.