SANSA: Unleashing the Hidden Semantics in SAM2 for Few-Shot Segmentation
作者: Claudia Cuttano, Gabriele Trivigno, Giuseppe Averta, Carlo Masone
分类: cs.CV
发布日期: 2025-05-27 (更新: 2025-11-15)
备注: Accepted to NeurIPS 2025 as Spotlight
🔗 代码/项目: GITHUB
💡 一句话要点
SANSA:利用SAM2的潜在语义信息进行少样本分割
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 少样本分割 语义对齐 SAM2 预训练模型 图像分割
📋 核心要点
- 现有少样本分割方法难以有效利用预训练模型的语义信息,导致泛化能力不足。
- SANSA通过语义对齐,解耦SAM2中与任务相关的特征,从而显式地利用其潜在的语义结构。
- SANSA在少样本分割基准上达到SOTA,且速度更快、模型更小,支持多种提示方式。
📝 摘要(中文)
少样本分割旨在仅利用少量带标注的样本分割未见过的物体类别。这需要能够识别图像间语义相关物体并准确生成分割掩码的机制。本文指出,Segment Anything 2 (SAM2) 凭借其提示和传播机制,提供了强大的分割能力和内置的特征匹配过程。然而,研究表明其表征与为目标跟踪优化的特定任务线索纠缠在一起,这损害了其在需要更高层次语义理解的任务中的应用。本文的关键见解是,尽管SAM2经过了类别无关的预训练,但它已经在其特征中编码了丰富的语义结构。因此,本文提出了SANSA (Semantically AligNed Segment Anything 2),一个通过最小的任务特定修改来显式化这种潜在结构并重新利用SAM2进行少样本分割的框架。SANSA在专门用于评估泛化能力的少样本分割基准测试中取得了最先进的性能,在流行的上下文学习设置中优于通用方法,支持通过点、框或涂鸦进行各种提示的灵活交互,并且比以前的方法更快、更紧凑。
🔬 方法详解
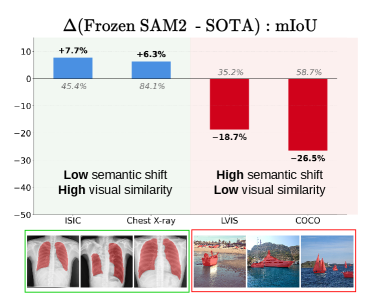
问题定义:少样本分割旨在利用少量标注样本分割未见过的物体类别。现有方法通常难以有效利用预训练模型的语义信息,导致在面对新的物体类别时泛化能力不足。SAM2虽然具有强大的分割能力,但其特征与目标跟踪等任务相关的线索纠缠,限制了其在少样本分割中的应用。
核心思路:SANSA的核心思路是解耦SAM2的特征表示,使其能够更好地捕捉图像中物体的语义信息。通过语义对齐,SANSA旨在消除SAM2特征中与特定任务相关的噪声,从而显式地利用其潜在的语义结构。这样,模型就能更好地理解不同物体类别之间的关系,从而提高少样本分割的性能。
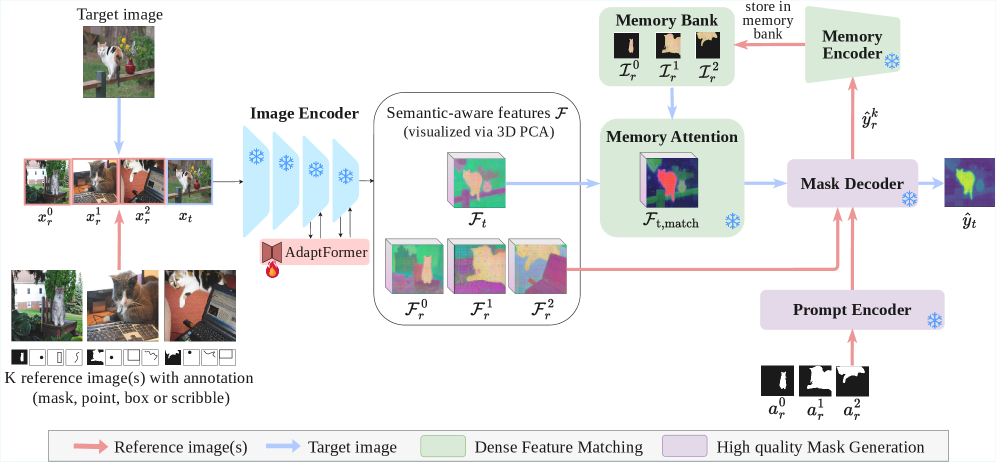
技术框架:SANSA框架主要包括以下几个阶段:首先,利用SAM2提取图像特征。然后,通过语义对齐模块,解耦SAM2特征中与任务相关的部分,提取更纯粹的语义信息。最后,利用提取的语义信息进行少样本分割,生成分割掩码。该框架支持多种提示方式,如点、框和涂鸦。
关键创新:SANSA的关键创新在于其语义对齐模块,该模块能够有效地解耦SAM2特征,提取更纯粹的语义信息。与现有方法相比,SANSA能够更好地利用SAM2的潜在语义结构,从而提高少样本分割的性能。此外,SANSA框架的设计使其能够支持多种提示方式,提高了其灵活性和易用性。
关键设计:SANSA的具体实现细节包括:语义对齐模块采用了一种自监督学习的方法,通过对比学习来区分语义信息和任务相关信息。损失函数的设计旨在最大化语义信息的一致性,同时最小化任务相关信息的干扰。网络结构方面,SANSA在SAM2的基础上添加了少量的可学习参数,以实现语义对齐。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
SANSA在少样本分割基准测试中取得了显著的性能提升。例如,在COCO-20i数据集上,SANSA的性能超过了现有SOTA方法,并且在速度和模型大小方面具有优势。实验结果表明,SANSA能够有效地利用SAM2的潜在语义信息,从而提高少样本分割的性能。
🎯 应用场景
SANSA在医疗图像分析、遥感图像处理、自动驾驶等领域具有广泛的应用前景。例如,在医疗图像分析中,可以利用SANSA对罕见疾病的病灶进行分割,辅助医生进行诊断。在遥感图像处理中,可以利用SANSA对新的地物类型进行分割,提高遥感图像的解译精度。在自动驾驶领域,可以利用SANSA对未知的障碍物进行分割,提高自动驾驶系统的安全性。
📄 摘要(原文)
Few-shot segmentation aims to segment unseen object categories from just a handful of annotated examples. This requires mechanisms that can both identify semantically related objects across images and accurately produce segmentation masks. We note that Segment Anything 2 (SAM2), with its prompt-and-propagate mechanism, offers both strong segmentation capabilities and a built-in feature matching process. However, we show that its representations are entangled with task-specific cues optimized for object tracking, which impairs its use for tasks requiring higher level semantic understanding. Our key insight is that, despite its class-agnostic pretraining, SAM2 already encodes rich semantic structure in its features. We propose SANSA (Semantically AligNed Segment Anything 2), a framework that makes this latent structure explicit, and repurposes SAM2 for few-shot segmentation through minimal task-specific modifications. SANSA achieves state-of-the-art performance on few-shot segmentation benchmarks specifically designed to assess generalization, outperforms generalist methods in the popular in-context setting, supports various prompts flexible interaction via points, boxes, or scribbles, and remains significantly faster and more compact than prior approaches. Code is available at https://github.com/ClaudiaCuttano/SANSA.