MedBridge: Bridging Foundation Vision-Language Models to Medical Image Diagnosis in Chest X-Ray
作者: Yitong Li, Morteza Ghahremani, Christian Wachinger
分类: cs.CV
发布日期: 2025-05-27 (更新: 2025-11-24)
🔗 代码/项目: GITHUB
💡 一句话要点
MedBridge:桥接视觉-语言基础模型至胸部X光医学图像诊断
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学图像诊断 视觉-语言模型 迁移学习 胸部X光 多模态学习
📋 核心要点
- 现有视觉-语言模型在医学图像领域表现不佳,且训练医学专用模型成本高昂,限制了其应用。
- MedBridge通过焦点采样、查询编码器和混合专家机制,轻量级地适配预训练视觉-语言模型到医学图像诊断。
- 在胸部X光数据集上的实验表明,MedBridge在跨域和域内自适应任务中均优于现有方法,AUC提升显著。
📝 摘要(中文)
近期的视觉-语言基础模型在自然图像分类中取得了最先进的结果,但由于显著的领域差异,在医学图像中表现不佳。训练医学基础模型需要大量的资源,包括广泛的标注数据和高计算能力。为了以最小的开销弥合这一差距,我们引入了MedBridge,这是一个轻量级多模态自适应框架,可以灵活地将任意预训练的基础视觉-语言模型重新用于医学图像诊断。MedBridge包含三个新的核心组件。首先,一个焦点采样模块,它对高分辨率局部区域进行子采样和提取,以捕获细微的病理特征,弥补了基础视觉-语言模型有限的输入分辨率。其次,一个查询编码器模型,它使用一小组可学习的查询来将冻结的视觉-语言模型的特征图与医学语义对齐,而无需重新训练骨干层。第三,一种混合专家机制,由可学习的查询驱动,利用各种视觉-语言模型的互补优势,以最大限度地提高诊断性能。我们在五个胸部X光基准上评估了MedBridge在三个关键自适应任务中的表现,证明了其在不同训练数据可用性下的跨领域和领域内自适应设置中的优越性能。与最先进的视觉-语言模型自适应方法相比,MedBridge在多标签胸腔疾病诊断中实现了6-15%的AUC提升,突显了其在利用各种基础模型进行准确和数据高效的医学诊断方面的有效性。
🔬 方法详解
问题定义:论文旨在解决视觉-语言基础模型在医学图像诊断领域表现不佳的问题。现有方法要么需要大量标注数据和计算资源来训练医学专用模型,要么直接应用预训练模型效果不佳,无法有效捕捉医学图像中的细微病理特征。
核心思路:论文的核心思路是设计一个轻量级的多模态自适应框架MedBridge,通过三个关键模块,将预训练的视觉-语言模型有效地迁移到医学图像诊断任务中,而无需重新训练整个模型。这样既能利用预训练模型的知识,又能降低训练成本。
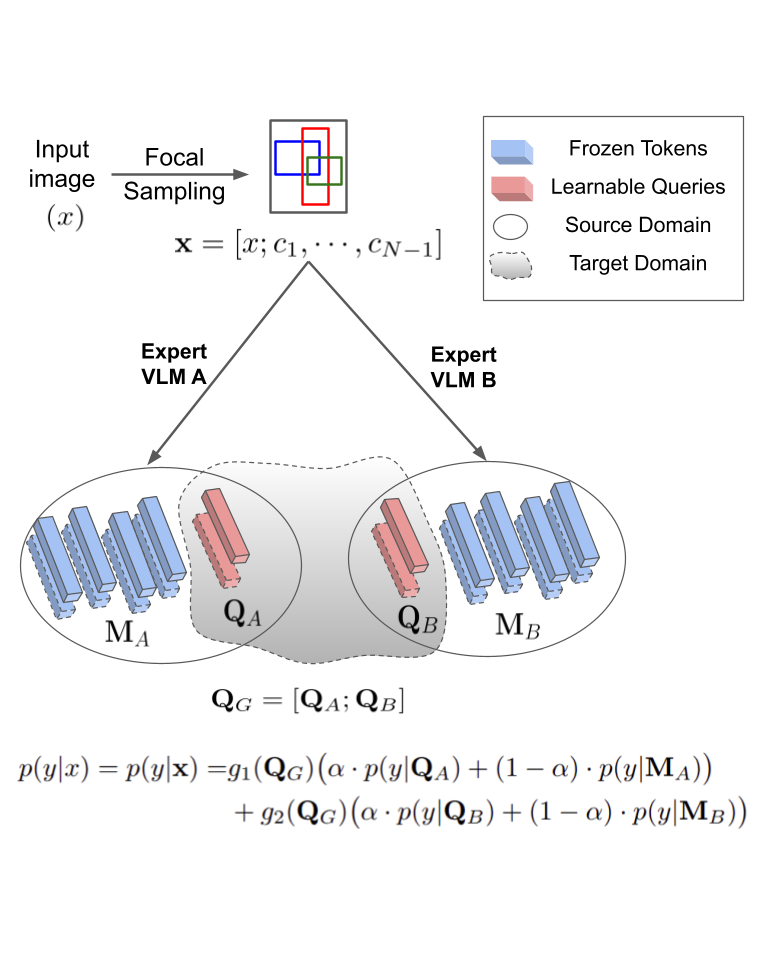
技术框架:MedBridge的整体架构包含三个主要模块:1) 焦点采样模块:用于提取高分辨率的局部区域,以捕捉细微的病理特征。2) 查询编码器模型:使用一组可学习的查询向量,将视觉-语言模型的特征图与医学语义对齐。3) 混合专家机制:利用多个视觉-语言模型的互补优势,提高诊断性能。整个流程是先通过焦点采样提取图像特征,然后使用查询编码器对齐特征,最后通过混合专家机制进行诊断。
关键创新:MedBridge的关键创新在于其轻量级的自适应框架,它不需要重新训练视觉-语言模型的骨干网络,而是通过焦点采样、查询编码器和混合专家机制,有效地将预训练模型迁移到医学图像诊断任务中。与现有方法相比,MedBridge更加高效且数据友好。
关键设计:焦点采样模块通过子采样和提取高分辨率局部区域来弥补视觉-语言模型输入分辨率的限制。查询编码器使用少量可学习的查询向量,避免了对整个骨干网络进行微调。混合专家机制通过可学习的权重,动态地组合不同视觉-语言模型的预测结果。损失函数的设计旨在优化查询向量的学习,并提高诊断的准确性。
🖼️ 关键图片


📊 实验亮点
MedBridge在五个胸部X光基准数据集上进行了评估,结果表明,与最先进的视觉-语言模型自适应方法相比,MedBridge在多标签胸腔疾病诊断中实现了6-15%的AUC提升。实验结果证明了MedBridge在利用各种基础模型进行准确和数据高效的医学诊断方面的有效性。
🎯 应用场景
MedBridge具有广泛的应用前景,可用于各种医学图像诊断任务,例如胸部X光、CT扫描、MRI等。该研究可以帮助医生更准确、更高效地诊断疾病,提高医疗水平。此外,MedBridge的轻量级设计使其易于部署和应用,有望在资源有限的医疗机构中发挥重要作用。
📄 摘要(原文)
Recent vision-language foundation models deliver state-of-the-art results in natural image classification, but falter in medical images due to pronounced domain shifts. Training a medical foundation model also requires substantial resources, including extensive annotated data and high computational capacity. To bridge this gap with minimal overhead, we introduce MedBridge, a lightweight multimodal adaptation framework that flexibly re-purposes arbitrary pre-trained foundation VLMs for medical image diagnosis. MedBridge comprises three novel core components. First, a Focal Sampling module that subsamples and extracts high-resolution local regions to capture subtle pathological features, compensating for the limited input resolution of foundation VLMs. Second, a Query-Encoder model with a small set of learnable queries to align the feature maps of frozen VLMs with medical semantics, without requiring retraining of the backbone layers. Third, a Mixture of Experts mechanism, driven by learnable queries, harnesses the complementary strength of various VLMs to maximize diagnostic performance. We evaluate MedBridge on five chest radiograph benchmarks in three key adaptation tasks, demonstrating its superior performance in both cross-domain and in-domain adaptation settings under varying levels of training data availability. MedBridge achieved an improvement of 6-15% in AUC compared to state-of-the-art VLM adaptation methods in multi-label thoracic disease diagnosis, underscoring its effectiveness in leveraging diverse foundation models for accurate and data-efficient medical diagnosis. Our project and code are available at https://github.com/ai-med/MedBridge.