ViewSpatial-Bench: Evaluating Multi-perspective Spatial Localization in Vision-Language Models
作者: Dingming Li, Hongxing Li, Zixuan Wang, Yuchen Yan, Hang Zhang, Siqi Chen, Guiyang Hou, Shengpei Jiang, Wenqi Zhang, Yongliang Shen, Weiming Lu, Yueting Zhuang
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-05-27 (更新: 2025-09-30)
备注: Project: https://zju-real.github.io/ViewSpatial-Page/
💡 一句话要点
提出ViewSpatial-Bench基准,评估视觉语言模型在多视角空间定位中的能力
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 多视角学习 空间推理 具身AI 基准数据集
📋 核心要点
- 现有视觉语言模型在以自我为中心的空间推理上表现良好,但在需要理解他人视角下的空间关系时存在不足。
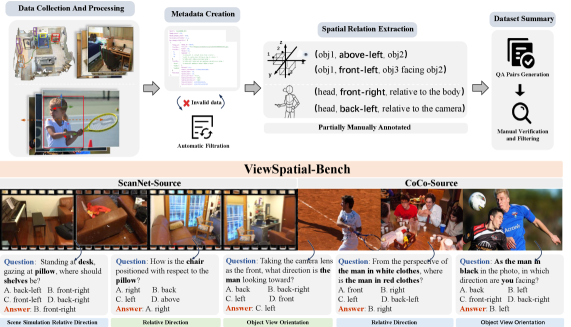
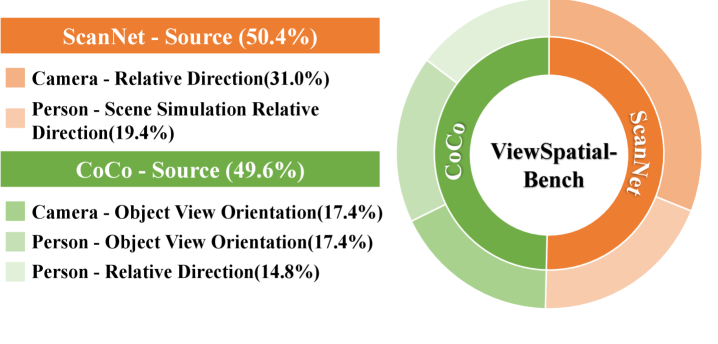
- 论文提出ViewSpatial-Bench基准,包含五种任务类型,并使用自动化3D标注流程生成精确的方向标签,用于评估模型的多视角空间定位能力。
- 实验表明,在多视角空间数据集上微调VLMs后,模型在各项任务上的性能提升了46.24%,验证了该方法的有效性。
📝 摘要(中文)
视觉语言模型(VLMs)在理解和推理视觉内容方面表现出卓越的能力,但在需要跨视角理解和空间推理的任务中仍然存在重大挑战。我们发现一个关键限制:目前的VLMs主要擅长以自我为中心的空间推理(从相机的角度),但当需要采用另一个实体的空间参考框架时,无法推广到以他人为中心的视角。我们推出了ViewSpatial-Bench,这是第一个全面的基准,专门用于跨五种不同任务类型的多视角空间定位识别评估,并由自动化的3D标注流程支持,该流程生成精确的方向标签。对ViewSpatial-Bench上各种VLMs的全面评估显示出显著的性能差异:模型在相机视角任务上表现出合理的性能,但在从人的视角进行推理时,准确性降低。通过在我们的多视角空间数据集上微调VLMs,我们实现了跨任务的46.24%的总体性能提升,突出了我们方法的有效性。我们的工作为具身AI系统中的空间智能建立了一个关键基准,并提供了经验证据,表明建模3D空间关系可以增强VLMs相应的空间理解能力。
🔬 方法详解
问题定义:现有视觉语言模型在空间推理方面存在局限性,尤其是在需要理解和推理非相机视角的空间关系时。模型通常擅长以相机为中心的自我视角推理,但在需要转换到其他实体(例如人)的视角进行推理时,性能显著下降。这种局限性阻碍了VLMs在具身AI等领域的应用,因为这些应用通常需要模型理解和操作不同视角下的空间信息。
核心思路:论文的核心思路是构建一个专门用于评估和提升VLMs在多视角空间定位能力上的基准数据集和评估方法。通过提供包含不同视角和空间关系的标注数据,并设计相应的评估任务,可以更全面地了解VLMs在空间推理方面的优势和不足,并指导模型进行改进。
技术框架:ViewSpatial-Bench基准包含一个多视角空间数据集和一个评估框架。数据集通过自动化的3D标注流程生成,包含精确的方向标签,涵盖五种不同的任务类型,旨在测试模型在不同视角下的空间定位能力。评估框架则提供了一套标准的评估指标和流程,用于比较不同VLMs在ViewSpatial-Bench上的性能。
关键创新:该论文的关键创新在于提出了ViewSpatial-Bench,这是第一个专门针对多视角空间定位识别评估的综合基准。该基准通过自动化的3D标注流程生成精确的方向标签,并包含五种不同的任务类型,可以更全面地评估VLMs在空间推理方面的能力。与现有方法相比,ViewSpatial-Bench更关注模型在不同视角下的空间推理能力,这对于具身AI等应用至关重要。
关键设计:ViewSpatial-Bench的关键设计包括:1) 自动化3D标注流程,用于生成精确的方向标签;2) 五种不同的任务类型,涵盖不同的空间推理场景;3) 标准化的评估指标和流程,用于比较不同VLMs的性能。具体参数设置和网络结构取决于所评估的VLMs,论文主要关注基准的构建和评估,而非特定的模型架构。
🖼️ 关键图片

📊 实验亮点
在ViewSpatial-Bench基准上,现有VLMs在相机视角任务上表现出合理的性能,但在从人的视角进行推理时,准确性显著降低。通过在多视角空间数据集上微调VLMs,模型在各项任务上的总体性能提升了46.24%,证明了该基准和微调方法的有效性。该结果表明,建模3D空间关系可以显著增强VLMs的空间理解能力。
🎯 应用场景
该研究成果可应用于具身AI、机器人导航、人机交互等领域。例如,机器人可以利用多视角空间定位能力,更好地理解人类指令,并在复杂环境中进行导航和操作。此外,该研究还可以促进虚拟现实和增强现实技术的发展,提升用户在虚拟环境中的空间感知和交互体验。
📄 摘要(原文)
Vision-language models (VLMs) have demonstrated remarkable capabilities in understanding and reasoning about visual content, but significant challenges persist in tasks requiring cross-viewpoint understanding and spatial reasoning. We identify a critical limitation: current VLMs excel primarily at egocentric spatial reasoning (from the camera's perspective) but fail to generalize to allocentric viewpoints when required to adopt another entity's spatial frame of reference. We introduce ViewSpatial-Bench, the first comprehensive benchmark designed specifically for multi-viewpoint spatial localization recognition evaluation across five distinct task types, supported by an automated 3D annotation pipeline that generates precise directional labels. Comprehensive evaluation of diverse VLMs on ViewSpatial-Bench reveals a significant performance disparity: models demonstrate reasonable performance on camera-perspective tasks but exhibit reduced accuracy when reasoning from a human viewpoint. By fine-tuning VLMs on our multi-perspective spatial dataset, we achieve an overall performance improvement of 46.24% across tasks, highlighting the efficacy of our approach. Our work establishes a crucial benchmark for spatial intelligence in embodied AI systems and provides empirical evidence that modeling 3D spatial relationships enhances VLMs' corresponding spatial comprehension capabilities.