Mitigating Hallucination in Large Vision-Language Models via Adaptive Attention Calibration
作者: Mehrdad Fazli, Bowen Wei, Ahmet Sari, Ziwei Zhu
分类: cs.CV, cs.CL
发布日期: 2025-05-27 (更新: 2025-08-11)
💡 一句话要点
提出CAAC框架,通过自适应注意力校准缓解大型视觉语言模型中的幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 幻觉缓解 注意力校准 多模态学习 长文本生成
📋 核心要点
- 现有大型视觉语言模型易产生幻觉,在开放式生成和长文本生成中表现不佳,缺乏对图像内容的准确理解。
- CAAC框架通过视觉Token校准(VTC)平衡视觉注意力,并利用自适应注意力重缩放(AAR)增强视觉基础,提升模型置信度。
- 实验表明,CAAC在CHAIR、AMBER和POPE等基准测试中优于现有方法,尤其在长文本生成方面,有效降低了幻觉。
📝 摘要(中文)
大型视觉语言模型(LVLMs)在多模态任务上表现出色,但常出现幻觉问题,即自信地描述图像中不存在的物体或属性。现有的免训练干预方法难以在开放式和长文本生成场景中保持准确性。本文提出了置信度感知注意力校准(CAAC)框架,通过解决两个关键偏差来应对这一挑战:空间感知偏差(在图像tokens上分配不成比例的注意力)和模态偏差(随着时间推移将焦点从视觉输入转移到文本输入)。CAAC采用两步方法:视觉Token校准(VTC)来平衡视觉tokens之间的注意力,以及自适应注意力重缩放(AAR)来增强视觉基础,并由模型的置信度引导。这种置信度驱动的调整确保了生成过程中视觉对齐的一致性。在CHAIR、AMBER和POPE基准上的实验表明,CAAC优于基线方法,尤其是在长文本生成中,有效地减少了幻觉。
🔬 方法详解
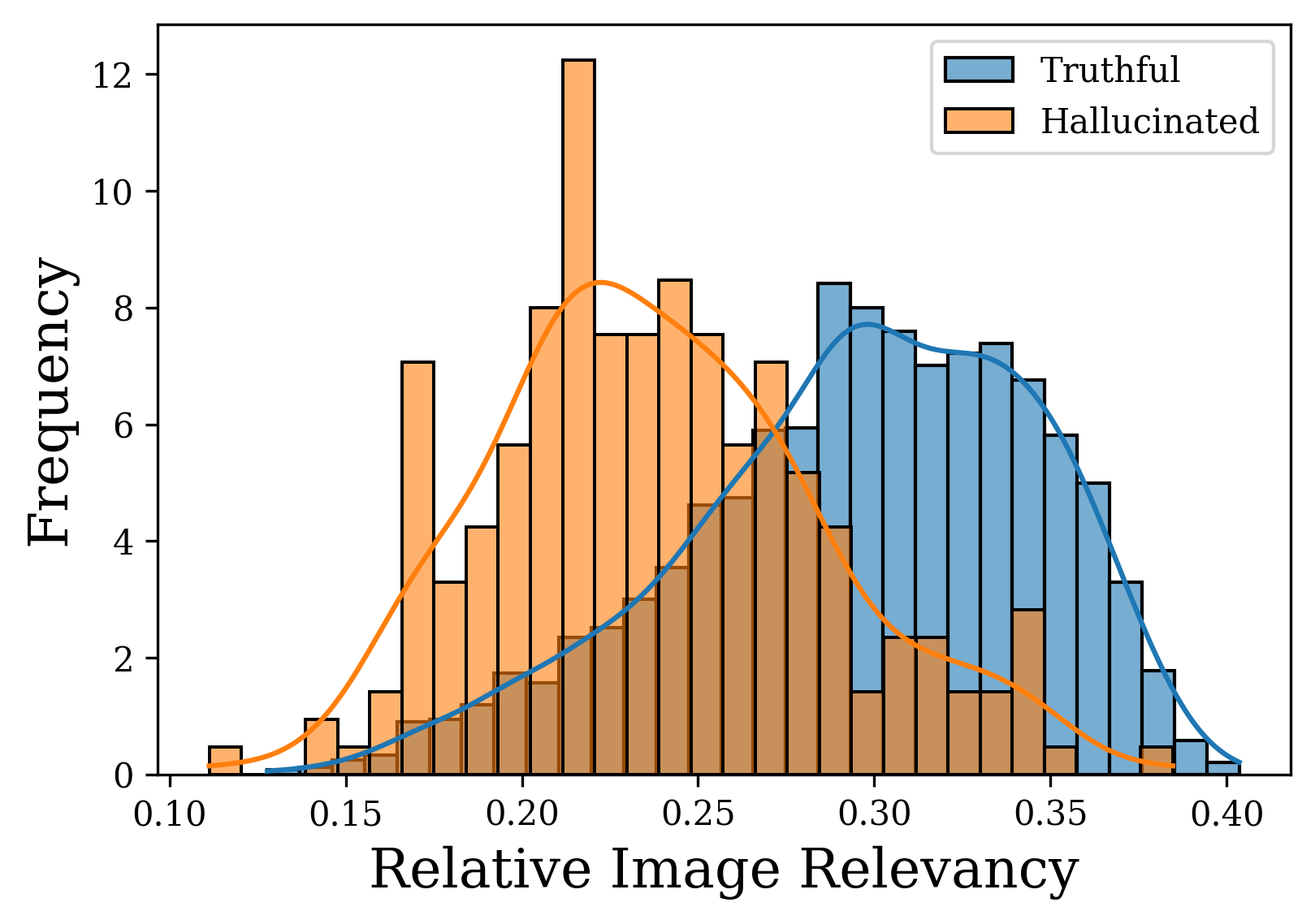
问题定义:大型视觉语言模型(LVLMs)在多模态任务中表现出强大的能力,但一个显著的问题是“幻觉”,即模型会生成与图像内容不符的信息。现有的免训练干预方法在开放式和长文本生成场景中效果有限,无法有效抑制幻觉现象。这些方法通常难以平衡视觉和文本信息,导致模型过度依赖文本先验知识,忽略图像的真实内容。
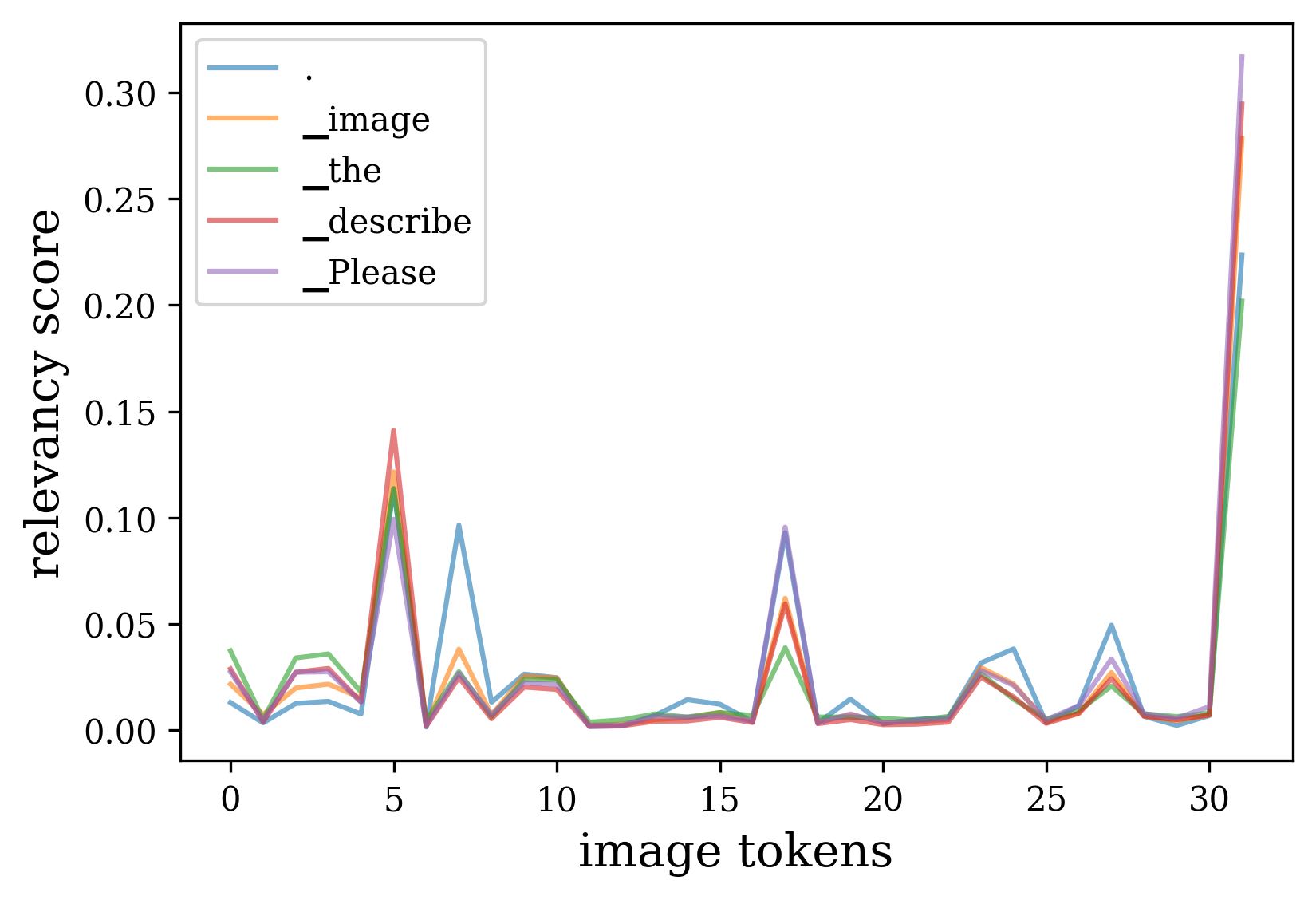
核心思路:CAAC的核心思路是通过校准注意力机制来解决LVLMs中的幻觉问题。它认为幻觉的产生源于两个关键偏差:空间感知偏差和模态偏差。空间感知偏差指的是模型在处理图像时,注意力在不同视觉tokens上的分配不均衡,导致某些重要区域被忽略。模态偏差指的是模型在生成过程中,注意力逐渐从视觉输入转移到文本输入,导致视觉信息逐渐丢失。CAAC旨在通过平衡视觉tokens的注意力分配和强化视觉信息的利用来缓解这些偏差。
技术框架:CAAC框架包含两个主要模块:视觉Token校准(VTC)和自适应注意力重缩放(AAR)。首先,VTC模块对视觉tokens的注意力进行校准,使其更加均衡,避免过度关注某些区域而忽略其他区域。然后,AAR模块根据模型的置信度自适应地调整注意力权重,强化视觉信息的利用。整个框架的目标是在生成过程中保持视觉对齐的一致性,从而减少幻觉的产生。
关键创新:CAAC的关键创新在于其置信度驱动的自适应注意力校准机制。与传统的注意力校准方法不同,CAAC不是静态地调整注意力权重,而是根据模型自身的置信度动态地进行调整。这种自适应的调整方式可以更好地适应不同的图像和文本输入,从而更有效地缓解幻觉问题。此外,CAAC同时考虑了空间感知偏差和模态偏差,并分别设计了VTC和AAR模块来解决这两个问题,从而更全面地提升了模型的性能。
关键设计:VTC模块的具体实现方式未知,但其目标是平衡视觉tokens的注意力权重。AAR模块的关键在于如何定义和计算模型的置信度,以及如何根据置信度调整注意力权重。具体的置信度计算方法和注意力权重调整策略在论文中可能有所描述,但摘要中未提及。损失函数的设计目标是最小化幻觉的产生,可能涉及到对生成文本与图像内容一致性的约束。
🖼️ 关键图片

📊 实验亮点
CAAC在CHAIR、AMBER和POPE基准测试中均取得了优于基线方法的性能。尤其是在长文本生成任务中,CAAC能够显著减少幻觉现象,生成更符合图像内容的描述。具体的性能提升数据需要在论文中查找,摘要中未提供具体的数值。
🎯 应用场景
该研究成果可应用于各种需要可靠视觉信息理解的场景,例如:自动驾驶(准确识别交通标志和行人)、医疗诊断(辅助医生分析医学影像)、智能客服(根据用户上传的图片提供准确的解答)以及内容审核(检测图像中是否存在违规内容)。通过减少视觉语言模型中的幻觉,可以提高这些应用的安全性、可靠性和用户体验。
📄 摘要(原文)
Large vision-language models (LVLMs) achieve impressive performance on multimodal tasks but often suffer from hallucination, and confidently describe objects or attributes not present in the image. Current training-free interventions struggle to maintain accuracy in open-ended and long-form generation scenarios. We introduce the Confidence-Aware Attention Calibration (CAAC) framework to address this challenge by targeting two key biases: spatial perception bias, which distributes attention disproportionately across image tokens, and modality bias, which shifts focus from visual to textual inputs over time. CAAC employs a two-step approach: Visual-Token Calibration (VTC) to balance attention across visual tokens, and Adaptive Attention Re-Scaling (AAR) to reinforce visual grounding guided by the model's confidence. This confidence-driven adjustment ensures consistent visual alignment during generation. Experiments on CHAIR, AMBER, and POPE benchmarks demonstrate that CAAC outperforms baselines, particularly in long-form generations, effectively reducing hallucination.