GeoLLaVA-8K: Scaling Remote-Sensing Multimodal Large Language Models to 8K Resolution
作者: Fengxiang Wang, Mingshuo Chen, Yueying Li, Di Wang, Haotian Wang, Zonghao Guo, Zefan Wang, Boqi Shan, Long Lan, Yulin Wang, Hongzhen Wang, Wenjing Yang, Bo Du, Jing Zhang
分类: cs.CV
发布日期: 2025-05-27 (更新: 2025-11-04)
备注: NeurlPS 2025 Spotlight
💡 一句话要点
GeoLLaVA-8K:提出首个遥感领域8K分辨率多模态大语言模型,解决超高分辨率图像处理难题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 遥感图像处理 多模态大语言模型 超高分辨率图像 token选择 视觉问答 LLaVA 地球观测
📋 核心要点
- 现有方法难以处理超高分辨率遥感图像,主要瓶颈在于缺乏足够的高分辨率训练数据和图像尺寸过大导致的token数量爆炸。
- 论文核心思想是利用遥感图像的冗余性,通过背景token修剪和锚定token选择,在减少计算量的同时保留关键语义信息。
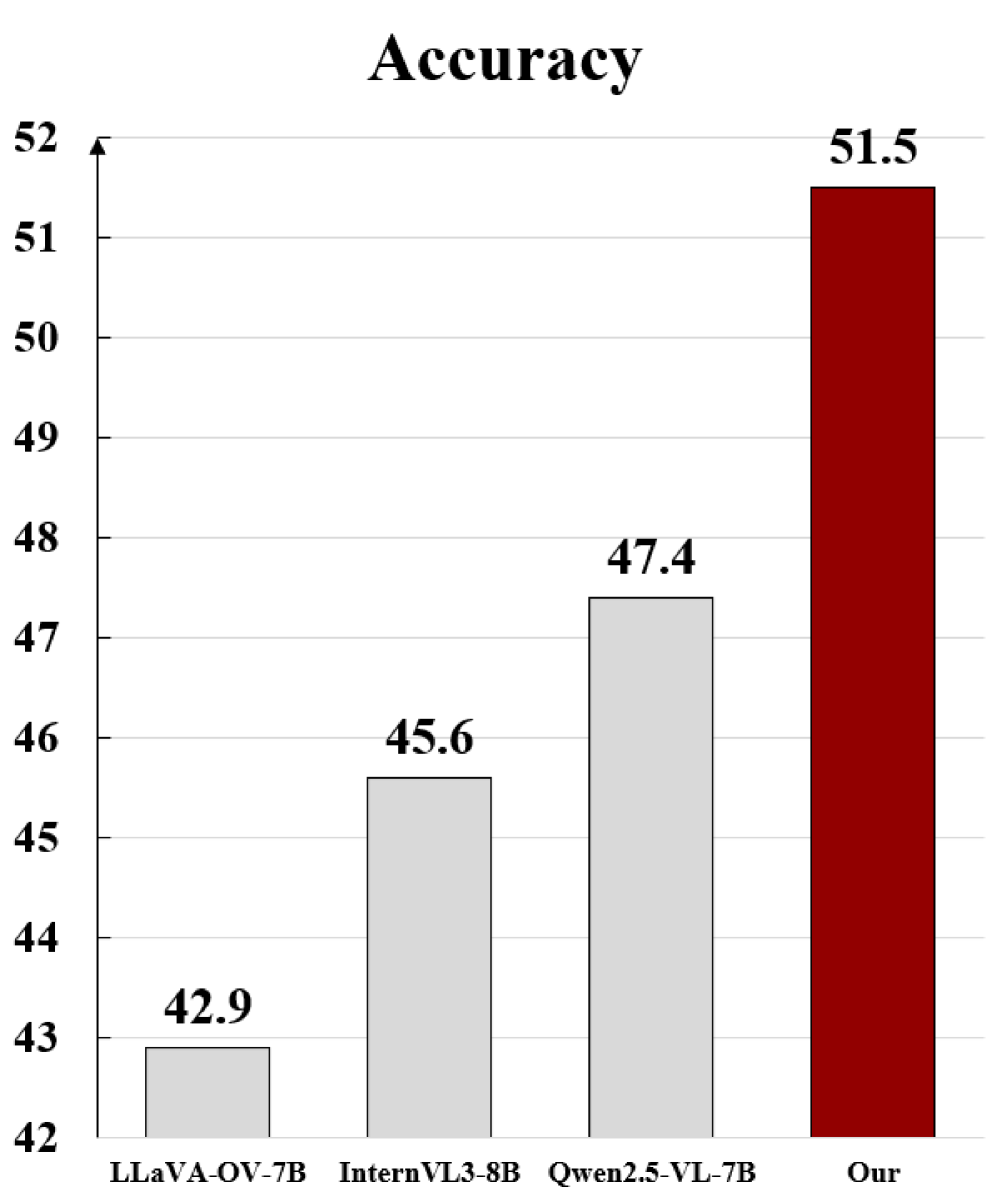
- 提出的GeoLLaVA-8K模型在XLRS-Bench遥感数据集上取得了新的state-of-the-art结果,验证了方法的有效性。
📝 摘要(中文)
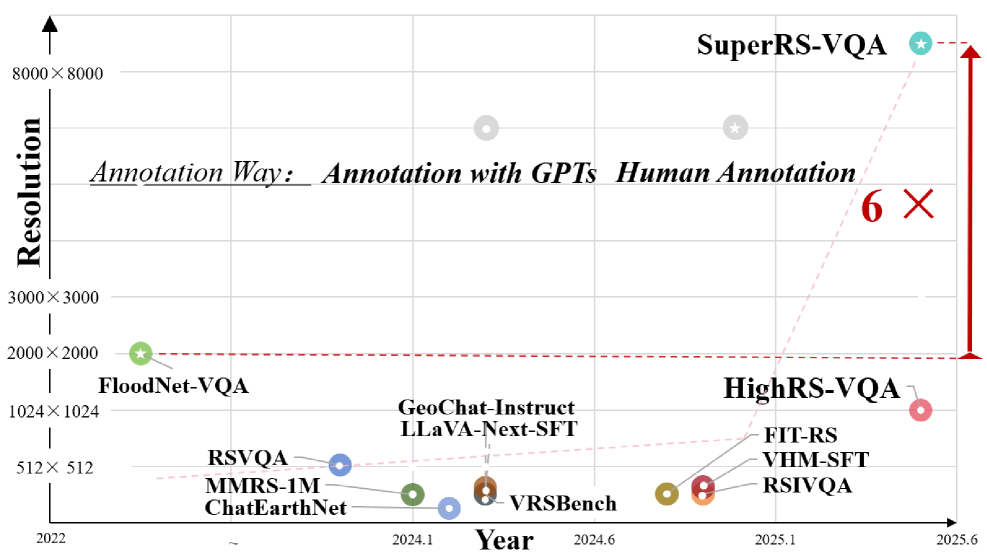
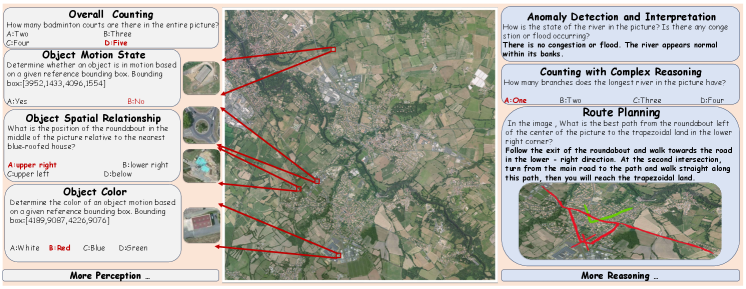
超高分辨率(UHR)遥感(RS)图像为地球观测提供了宝贵的数据,但由于两个关键瓶颈,对现有的多模态基础模型提出了挑战:(1) UHR训练数据的可用性有限,(2) 大图像尺寸导致token爆炸。为了解决数据稀缺问题,我们引入了SuperRS-VQA (平均8,376x8,376)和HighRS-VQA (平均2,000x1,912),这是迄今为止RS中最高分辨率的视觉语言数据集,涵盖22个真实世界的对话任务。为了缓解token爆炸,我们的初步研究揭示了RS图像中的显著冗余:关键信息集中在以对象为中心的token的一个小子集中,而修剪背景token(例如,海洋或森林)甚至可以提高性能。受这些发现的启发,我们提出了两种策略:背景token修剪和锚定token选择,以减少内存占用,同时保留关键语义。结合这些技术,我们推出了GeoLLaVA-8K,这是第一个专注于RS的多模态大型语言模型,能够处理高达8Kx8K分辨率的输入,建立在LLaVA框架之上。GeoLLaVA-8K在SuperRS-VQA和HighRS-VQA上进行训练,在XLRS-Bench上创造了新的技术水平。
🔬 方法详解
问题定义:现有遥感图像处理模型难以有效利用超高分辨率遥感图像,主要面临两个挑战:一是缺乏足够的高分辨率视觉-语言训练数据;二是高分辨率图像导致token数量爆炸,显著增加计算和内存需求。现有方法难以兼顾性能和效率。
核心思路:论文的核心思路是利用遥感图像的冗余性。作者观察到,遥感图像中的关键信息往往集中在少数以对象为中心的token上,而背景区域(如海洋、森林)包含大量冗余信息。因此,通过选择性地保留关键token并修剪冗余背景token,可以在显著减少计算量的同时,保持甚至提升模型性能。
技术框架:GeoLLaVA-8K建立在LLaVA框架之上,整体流程包括:1) 图像编码:使用视觉编码器(如CLIP)提取图像特征;2) token选择/修剪:应用背景token修剪和锚定token选择策略,减少token数量;3) 语言模型:将处理后的图像特征输入到大型语言模型(LLM)中,进行视觉问答等任务。模型在SuperRS-VQA和HighRS-VQA数据集上进行训练。
关键创新:论文的关键创新在于提出了两种token选择策略:背景token修剪和锚定token选择。背景token修剪旨在移除图像中不包含关键信息的背景区域token,减少计算冗余。锚定token选择则侧重于保留包含重要对象信息的token,确保模型能够捕捉到图像的关键语义。这两种策略的结合,使得模型能够在处理高分辨率图像时,兼顾性能和效率。
关键设计:背景token修剪的具体实现方式未知,可能涉及阈值化或聚类等方法来区分背景和前景token。锚定token选择可能基于注意力机制或目标检测等技术来确定关键对象的位置和重要性。损失函数方面,可能采用标准的视觉问答损失函数,并针对token选择策略进行调整,以鼓励模型选择更具信息量的token。
🖼️ 关键图片
📊 实验亮点
GeoLLaVA-8K在XLRS-Bench遥感数据集上取得了state-of-the-art的结果,证明了其在高分辨率遥感图像处理方面的优越性能。通过背景token修剪和锚定token选择策略,模型能够在显著减少计算量的同时,保持甚至提升性能,为高分辨率遥感图像的有效利用提供了新的思路。
🎯 应用场景
该研究成果可广泛应用于遥感图像分析领域,例如城市规划、环境监测、灾害评估和农业管理等。GeoLLaVA-8K能够处理高分辨率遥感图像,为更精细化的地球观测和分析提供技术支持,具有重要的实际应用价值和潜力。
📄 摘要(原文)
Ultra-high-resolution (UHR) remote sensing (RS) imagery offers valuable data for Earth observation but pose challenges for existing multimodal foundation models due to two key bottlenecks: (1) limited availability of UHR training data, and (2) token explosion caused by the large image size. To address data scarcity, we introduce SuperRS-VQA (avg. 8,376$\times$8,376) and HighRS-VQA (avg. 2,000$\times$1,912), the highest-resolution vision-language datasets in RS to date, covering 22 real-world dialogue tasks. To mitigate token explosion, our pilot studies reveal significant redundancy in RS images: crucial information is concentrated in a small subset of object-centric tokens, while pruning background tokens (e.g., ocean or forest) can even improve performance. Motivated by these findings, we propose two strategies: Background Token Pruning and Anchored Token Selection, to reduce the memory footprint while preserving key semantics.Integrating these techniques, we introduce GeoLLaVA-8K, the first RS-focused multimodal large language model capable of handling inputs up to 8K$\times$8K resolution, built on the LLaVA framework. Trained on SuperRS-VQA and HighRS-VQA, GeoLLaVA-8K sets a new state-of-the-art on the XLRS-Bench.