Think Twice, Act Once: Token-Aware Compression and Action Reuse for Efficient Inference in Vision-Language-Action Models
作者: Xudong Tan, Yaoxin Yang, Peng Ye, Jialin Zheng, Bizhe Bai, Xinyi Wang, Jia Hao, Tao Chen
分类: cs.CV
发布日期: 2025-05-27
💡 一句话要点
FlashVLA:面向VLA模型的Token感知压缩与动作复用高效推理框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 机器人控制 模型压缩 动作复用 Token选择 高效推理 边缘计算
📋 核心要点
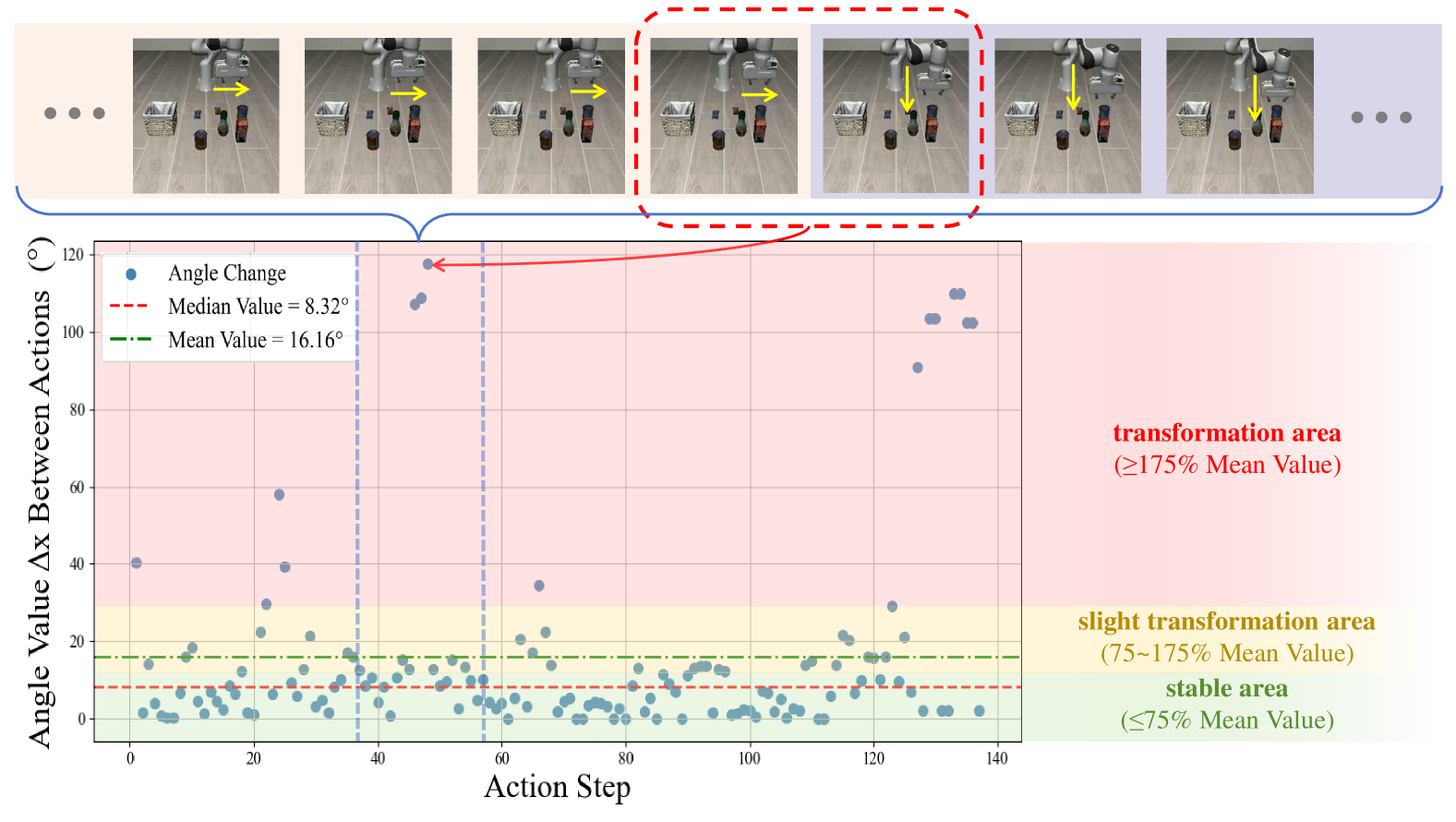
- VLA模型推理成本高昂,源于token计算和自回归解码,阻碍了其在实时和边缘场景的应用。
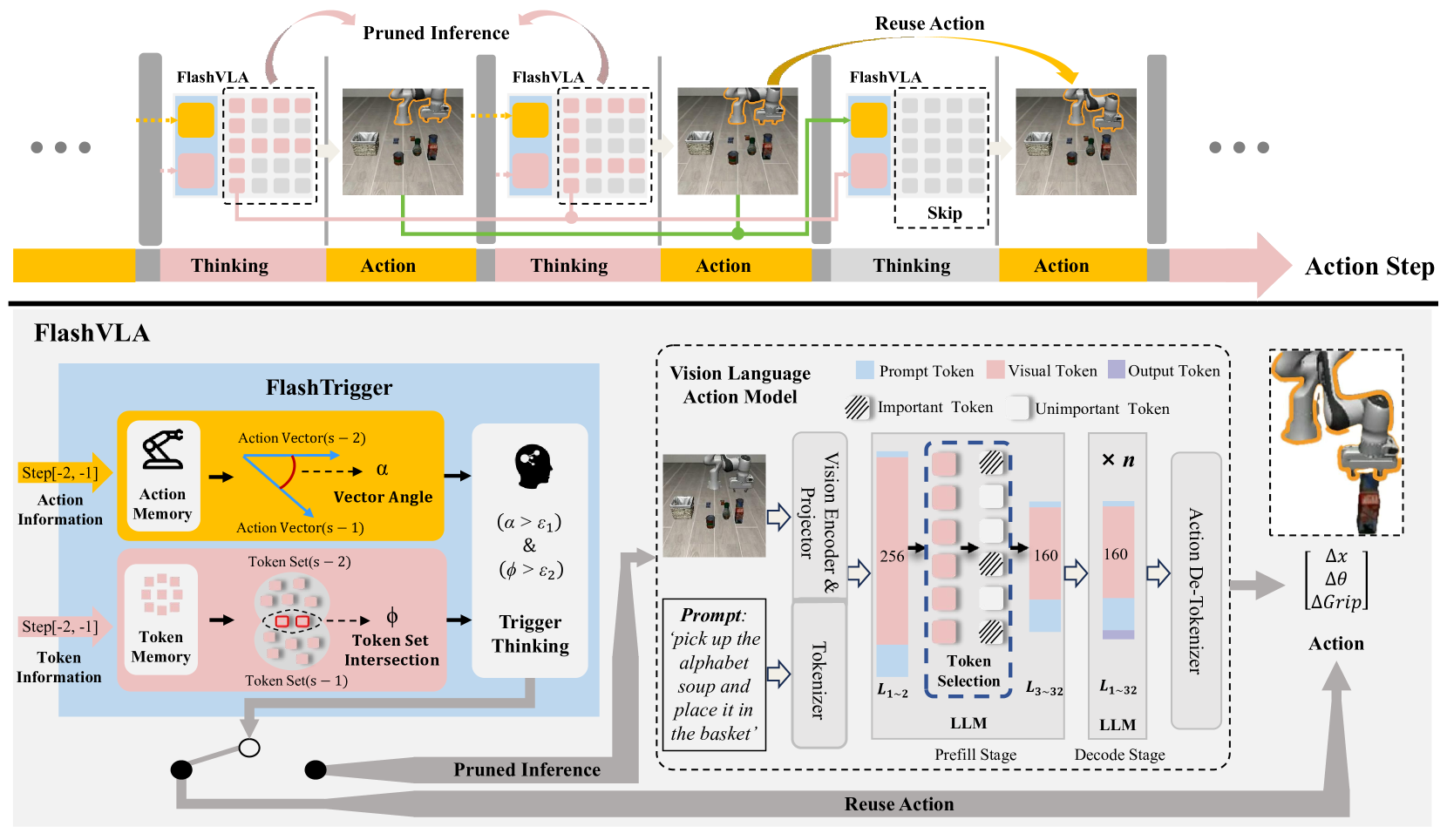
- FlashVLA通过token感知的动作复用和信息引导的视觉token选择,减少冗余计算,提升推理效率。
- 实验表明,FlashVLA在LIBERO基准上显著降低了FLOPs和延迟,同时保持了任务成功率。
📝 摘要(中文)
视觉-语言-动作(VLA)模型已成为通过自然语言指令进行通用机器人控制的强大范例。然而,它们的高推理成本——源于大规模的token计算和自回归解码——对实时部署和边缘应用构成了重大挑战。虽然先前的工作主要集中在架构优化上,但我们采取了不同的视角,通过识别VLA模型中的双重形式的冗余:(i)连续动作步骤之间的高度相似性,以及(ii)视觉token中的大量冗余。受这些观察的启发,我们提出了FlashVLA,这是第一个无需训练且即插即用的加速框架,它支持VLA模型中的动作复用。FlashVLA通过token感知的动作复用机制来避免稳定动作步骤中的冗余解码,并通过信息引导的视觉token选择策略来修剪低贡献的token,从而提高推理效率。在LIBERO基准上的大量实验表明,FlashVLA将FLOPs减少了55.7%,延迟降低了36.0%,而任务成功率仅下降了0.7%。这些结果证明了FlashVLA在无需重新训练的情况下实现轻量级、低延迟VLA推理的有效性。
🔬 方法详解
问题定义:VLA模型在机器人控制领域展现出潜力,但其高昂的计算成本限制了实际部署,尤其是在资源受限的边缘设备上。现有方法主要集中于模型架构的优化,忽略了动作序列和视觉token中存在的冗余信息。因此,如何降低VLA模型的推理成本,同时保持其性能,是一个亟待解决的问题。
核心思路:FlashVLA的核心思路是利用VLA模型中存在的冗余信息,包括连续动作步骤之间的高度相似性以及视觉token中的大量冗余。通过复用相似的动作和选择性地保留重要的视觉token,可以显著减少计算量,从而加速推理过程。这种方法无需重新训练模型,具有良好的通用性和易用性。
技术框架:FlashVLA框架主要包含两个核心模块:Token感知的动作复用机制和信息引导的视觉token选择策略。Token感知的动作复用机制通过比较当前动作步骤与前序步骤的token相似度,如果相似度较高,则复用前序步骤的解码结果,避免冗余计算。信息引导的视觉token选择策略则根据每个视觉token对最终动作预测的贡献程度,选择性地保留重要的token,去除低贡献的token,从而减少视觉信息的处理量。
关键创新:FlashVLA的关键创新在于其双重冗余消除策略。首先,它首次提出了在VLA模型中进行动作复用的概念,并设计了token感知的动作复用机制,能够有效地避免连续动作步骤之间的冗余解码。其次,它提出了信息引导的视觉token选择策略,能够根据token的重要性进行选择性处理,进一步降低计算量。与现有方法相比,FlashVLA无需重新训练模型,具有更好的通用性和易用性。
关键设计:Token感知的动作复用机制的关键在于相似度阈值的设定,该阈值决定了何时进行动作复用。信息引导的视觉token选择策略的关键在于如何评估每个视觉token的贡献程度,论文可能采用了注意力机制或其他相关方法来衡量token的重要性。具体的损失函数和网络结构细节需要在论文中进一步查找。
🖼️ 关键图片

📊 实验亮点
FlashVLA在LIBERO基准测试中表现出色,在任务成功率仅下降0.7%的情况下,FLOPs减少了55.7%,延迟降低了36.0%。这些结果表明,FlashVLA能够有效地降低VLA模型的推理成本,同时保持其性能,为VLA模型在实际应用中的部署提供了有力的支持。
🎯 应用场景
FlashVLA可应用于各种机器人控制场景,尤其是在计算资源受限的边缘设备上,例如移动机器人、无人机和智能家居设备。通过降低VLA模型的推理成本,FlashVLA能够实现更快速、更实时的机器人控制,从而提高机器人的自主性和智能化水平。未来,FlashVLA有望推动VLA模型在更广泛的领域得到应用。
📄 摘要(原文)
Vision-Language-Action (VLA) models have emerged as a powerful paradigm for general-purpose robot control through natural language instructions. However, their high inference cost-stemming from large-scale token computation and autoregressive decoding-poses significant challenges for real-time deployment and edge applications. While prior work has primarily focused on architectural optimization, we take a different perspective by identifying a dual form of redundancy in VLA models: (i) high similarity across consecutive action steps, and (ii) substantial redundancy in visual tokens. Motivated by these observations, we propose FlashVLA, the first training-free and plug-and-play acceleration framework that enables action reuse in VLA models. FlashVLA improves inference efficiency through a token-aware action reuse mechanism that avoids redundant decoding across stable action steps, and an information-guided visual token selection strategy that prunes low-contribution tokens. Extensive experiments on the LIBERO benchmark show that FlashVLA reduces FLOPs by 55.7% and latency by 36.0%, with only a 0.7% drop in task success rate. These results demonstrate the effectiveness of FlashVLA in enabling lightweight, low-latency VLA inference without retraining.