RefAV: Towards Planning-Centric Scenario Mining
作者: Cainan Davidson, Deva Ramanan, Neehar Peri
分类: cs.CV, cs.CL, cs.RO
发布日期: 2025-05-27 (更新: 2025-12-27)
备注: Project Page: https://cainand.github.io/RefAV/
🔗 代码/项目: GITHUB | PROJECT_PAGE
💡 一句话要点
RefAV:提出以规划为中心的场景挖掘方法,解决自动驾驶日志分析难题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 自动驾驶 场景挖掘 视觉-语言模型 运动规划 数据集 多智能体交互
📋 核心要点
- 现有场景挖掘技术依赖手工查询,易错且耗时,难以有效分析海量自动驾驶数据。
- 利用视觉-语言模型(VLM)理解自然语言描述的场景,并在驾驶日志中进行时空定位。
- 构建大规模数据集RefAV,包含10000个自然语言查询,用于评估和提升场景挖掘性能。
📝 摘要(中文)
自动驾驶车辆(AV)在日常车队测试中收集并伪标记了TB级别的多模态数据,这些数据与高清地图相关联。然而,从未经整理的驾驶日志中识别有趣和安全关键的场景仍然是一个重大挑战。传统的场景挖掘技术容易出错且耗时,通常依赖于手工构建的结构化查询。本文通过最新的视觉-语言模型(VLM)重新审视时空场景挖掘,以检测描述的场景是否发生在驾驶日志中,如果是,则在时间和空间上精确定位它。为了解决这个问题,我们引入了RefAV,这是一个大型数据集,包含10,000个不同的自然语言查询,这些查询描述了与运动规划相关的复杂多智能体交互,这些查询来自Argoverse 2传感器数据集中1000个驾驶日志。我们评估了几个参考多目标跟踪器,并对我们的基线进行了实证分析。值得注意的是,我们发现简单地重新利用现成的VLM会产生较差的性能,这表明场景挖掘提出了独特的挑战。最后,我们讨论了最近举办的比赛,并分享了来自社区的见解。我们的代码和数据集可在https://github.com/CainanD/RefAV/和https://argoverse.github.io/user-guide/tasks/scenario_mining.html获得。
🔬 方法详解
问题定义:自动驾驶场景挖掘旨在从海量驾驶数据中自动识别和定位符合特定描述的场景。现有方法主要依赖于人工设计的规则或查询,存在泛化能力差、维护成本高、难以处理复杂场景等问题。这些方法无法有效利用自动驾驶数据中蕴含的丰富信息,难以满足实际应用需求。
核心思路:论文的核心思路是将场景挖掘问题转化为一个基于视觉-语言模型的检索和定位问题。通过自然语言描述场景,利用VLM理解场景描述,并在驾驶日志中搜索匹配的场景片段。这种方法避免了人工规则的编写,提高了场景挖掘的灵活性和泛化能力。
技术框架:RefAV方法主要包含以下几个阶段:1) 场景描述:使用自然语言描述目标场景,例如“车辆在十字路口左转,行人正在过马路”。2) 视觉-语言模型:利用VLM将自然语言描述转换为场景的语义表示。3) 驾驶日志编码:将驾驶日志中的视觉和传感器数据编码为特征向量。4) 场景检索:在驾驶日志的特征向量中搜索与场景语义表示最匹配的片段。5) 时空定位:精确定位匹配场景在驾驶日志中的时间和空间位置。
关键创新:该论文的关键创新在于将视觉-语言模型应用于自动驾驶场景挖掘,并构建了大规模数据集RefAV。这种方法能够有效利用自然语言描述的场景信息,提高场景挖掘的准确性和效率。此外,RefAV数据集的构建为场景挖掘领域的研究提供了重要的资源。
关键设计:论文中,VLM的选择和训练至关重要。需要选择能够有效处理视觉和语言信息,并具有良好泛化能力的VLM。同时,需要设计合适的损失函数,以优化VLM在场景挖掘任务上的性能。此外,驾驶日志的编码方式也会影响场景检索的效率和准确性。论文中可能采用了特定的特征提取方法和索引结构,以加速场景检索过程。具体的参数设置、损失函数、网络结构等技术细节在论文中会有更详细的描述(未知)。
🖼️ 关键图片
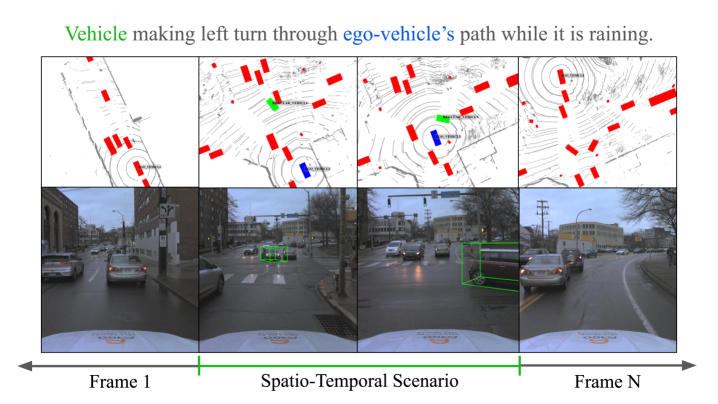


📊 实验亮点
论文构建了包含10000个自然语言查询的大规模数据集RefAV,并评估了多个参考多目标跟踪器。实验结果表明,直接使用现成的VLM效果不佳,表明场景挖掘任务具有独特的挑战性。社区竞赛的结果也为该领域的研究提供了宝贵的经验。
🎯 应用场景
该研究成果可应用于自动驾驶系统的测试与验证、事故分析、驾驶行为分析等领域。通过自动挖掘危险或异常场景,可以提高自动驾驶系统的安全性和可靠性。此外,该技术还可以用于分析驾驶员的行为模式,为驾驶员提供个性化的驾驶辅助服务。未来,该技术有望在智能交通领域发挥重要作用。
📄 摘要(原文)
Autonomous Vehicles (AVs) collect and pseudo-label terabytes of multi-modal data localized to HD maps during normal fleet testing. However, identifying interesting and safety-critical scenarios from uncurated driving logs remains a significant challenge. Traditional scenario mining techniques are error-prone and prohibitively time-consuming, often relying on hand-crafted structured queries. In this work, we revisit spatio-temporal scenario mining through the lens of recent vision-language models (VLMs) to detect whether a described scenario occurs in a driving log and, if so, precisely localize it in both time and space. To address this problem, we introduce RefAV, a large-scale dataset of 10,000 diverse natural language queries that describe complex multi-agent interactions relevant to motion planning derived from 1000 driving logs in the Argoverse 2 Sensor dataset. We evaluate several referential multi-object trackers and present an empirical analysis of our baselines. Notably, we find that naively repurposing off-the-shelf VLMs yields poor performance, suggesting that scenario mining presents unique challenges. Lastly, we discuss our recently held competition and share insights from the community. Our code and dataset are available at https://github.com/CainanD/RefAV/ and https://argoverse.github.io/user-guide/tasks/scenario_mining.html