Rendering-Aware Reinforcement Learning for Vector Graphics Generation
作者: Juan A. Rodriguez, Haotian Zhang, Abhay Puri, Aarash Feizi, Rishav Pramanik, Pascal Wichmann, Arnab Mondal, Mohammad Reza Samsami, Rabiul Awal, Perouz Taslakian, Spandana Gella, Sai Rajeswar, David Vazquez, Christopher Pal, Marco Pedersoli
分类: cs.CV, cs.AI
发布日期: 2025-05-27 (更新: 2025-11-30)
💡 一句话要点
提出RLRF:利用渲染反馈的强化学习方法提升向量图形生成质量
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 向量图形生成 强化学习 视觉-语言模型 SVG渲染 自回归模型
📋 核心要点
- 现有视觉-语言模型在SVG生成中缺乏对渲染结果的直接监督,导致生成质量受限。
- RLRF方法利用强化学习,通过比较渲染结果与原始图像来提供视觉反馈,指导模型优化SVG生成。
- 实验表明,RLRF显著优于监督微调,能够生成更准确、高效且语义连贯的SVG。
📝 摘要(中文)
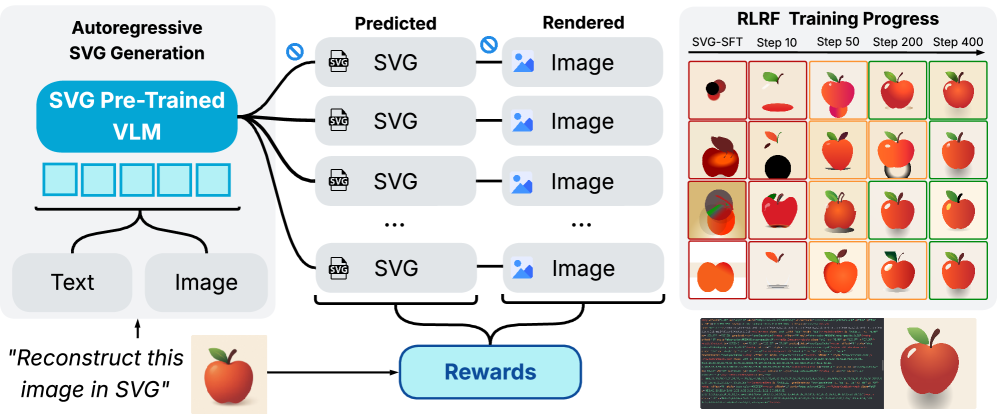
可缩放矢量图形(SVG)提供了一种强大的格式,用于将视觉设计表示为可解释的代码。视觉-语言模型(VLM)的最新进展已将该问题转化为代码生成任务,并利用大规模预训练实现了高质量的SVG生成。VLM特别适合这项任务,因为它们可以捕获全局语义和细粒度的视觉模式,同时在视觉、自然语言和代码领域之间转移知识。然而,现有的VLM方法通常难以生成忠实且高效的SVG,因为它们在训练期间从未观察到渲染图像。虽然用于自回归SVG代码生成的可微渲染仍然不可用,但渲染输出仍然可以与原始输入进行比较,从而实现适用于强化学习(RL)的评估反馈。我们引入了RLRF(Reinforcement Learning from Rendering Feedback),这是一种RL方法,通过利用渲染SVG输出的反馈来增强自回归VLM中的SVG生成。给定输入图像,模型生成SVG roll-out,对其进行渲染并与原始图像进行比较以计算奖励。这种视觉保真度反馈引导模型生成更准确、高效和语义连贯的SVG。RLRF显著优于监督微调,解决了常见的失败模式,并实现了精确、高质量的SVG生成,具有强大的结构理解和泛化能力。
🔬 方法详解
问题定义:论文旨在解决现有视觉-语言模型(VLM)在生成SVG图形时,由于缺乏对渲染结果的直接监督,导致生成的SVG图形不够准确、高效,并且可能存在语义不一致的问题。现有的VLM方法虽然能够生成SVG代码,但它们在训练过程中从未观察到渲染后的图像,因此无法直接优化渲染质量。
核心思路:论文的核心思路是利用强化学习(RL),通过比较生成的SVG图形渲染后的图像与原始输入图像,来提供视觉反馈信号,从而指导VLM模型生成更符合要求的SVG图形。这种方法的核心在于将SVG生成过程视为一个序列决策问题,并通过奖励函数来评估生成结果的质量。
技术框架:RLRF方法的整体框架包括以下几个主要模块:1) VLM模型:用于生成SVG代码;2) 渲染器:将生成的SVG代码渲染成图像;3) 奖励函数:用于评估渲染图像与原始图像之间的相似度;4) 强化学习算法:用于优化VLM模型的参数,使其能够生成更高质量的SVG代码。整个流程是:给定输入图像,VLM模型生成SVG代码,然后通过渲染器将SVG代码渲染成图像,接着通过奖励函数计算渲染图像与原始图像之间的相似度,最后利用强化学习算法根据奖励信号更新VLM模型的参数。
关键创新:RLRF方法的关键创新在于引入了渲染反馈机制,通过强化学习的方式来优化SVG生成过程。与传统的监督学习方法不同,RLRF方法能够直接优化渲染结果的视觉质量,从而生成更准确、高效和语义连贯的SVG图形。此外,该方法还能够解决监督学习中常见的失败模式,并提高SVG生成的结构理解和泛化能力。
关键设计:RLRF方法的关键设计包括:1) 奖励函数的设计:奖励函数需要能够准确地评估渲染图像与原始图像之间的相似度,常用的奖励函数包括像素级别的差异、感知损失等;2) 强化学习算法的选择:需要选择合适的强化学习算法来优化VLM模型的参数,常用的强化学习算法包括策略梯度方法、Q-learning方法等;3) VLM模型的选择:可以选择不同的VLM模型作为SVG生成的基础模型,例如Transformer模型、LSTM模型等。
🖼️ 关键图片


📊 实验亮点
RLRF方法在SVG生成任务上显著优于监督微调方法,能够生成更准确、高效和语义连贯的SVG图形。实验结果表明,RLRF能够有效解决监督学习中常见的失败模式,并提高SVG生成的结构理解和泛化能力。具体性能数据未知,但论文强调了其在视觉保真度、效率和语义一致性方面的提升。
🎯 应用场景
该研究成果可应用于矢量图形编辑、图像生成、计算机辅助设计等领域。通过自动生成高质量的SVG图形,可以提高设计效率,降低人工成本,并为用户提供更加便捷的图形编辑体验。未来,该技术有望在游戏开发、动画制作、网页设计等领域发挥重要作用。
📄 摘要(原文)
Scalable Vector Graphics (SVG) offer a powerful format for representing visual designs as interpretable code. Recent advances in vision-language models (VLMs) have enabled high-quality SVG generation by framing the problem as a code generation task and leveraging large-scale pretraining. VLMs are particularly suitable for this task as they capture both global semantics and fine-grained visual patterns, while transferring knowledge across vision, natural language, and code domains. However, existing VLM approaches often struggle to produce faithful and efficient SVGs because they never observe the rendered images during training. Although differentiable rendering for autoregressive SVG code generation remains unavailable, rendered outputs can still be compared to original inputs, enabling evaluative feedback suitable for reinforcement learning (RL). We introduce RLRF (Reinforcement Learning from Rendering Feedback), an RL method that enhances SVG generation in autoregressive VLMs by leveraging feedback from rendered SVG outputs. Given an input image, the model generates SVG roll-outs that are rendered and compared to the original image to compute a reward. This visual fidelity feedback guides the model toward producing more accurate, efficient, and semantically coherent SVGs. RLRF significantly outperforms supervised fine-tuning, addressing common failure modes and enabling precise, high-quality SVG generation with strong structural understanding and generalization.