PARTONOMY: Large Multimodal Models with Part-Level Visual Understanding
作者: Ansel Blume, Jeonghwan Kim, Hyeonjeong Ha, Elen Chatikyan, Xiaomeng Jin, Khanh Duy Nguyen, Nanyun Peng, Kai-Wei Chang, Derek Hoiem, Heng Ji
分类: cs.CV, cs.AI
发布日期: 2025-05-27 (更新: 2025-10-26)
备注: NeurIPS 2025 Spotlight; project page: https://wjdghks950.github.io/partonomy.github.io/
💡 一句话要点
提出PARTONOMY基准测试和PLUM模型,提升大模型部件级视觉理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 部件定位 视觉理解 大型语言模型 分割模型
📋 核心要点
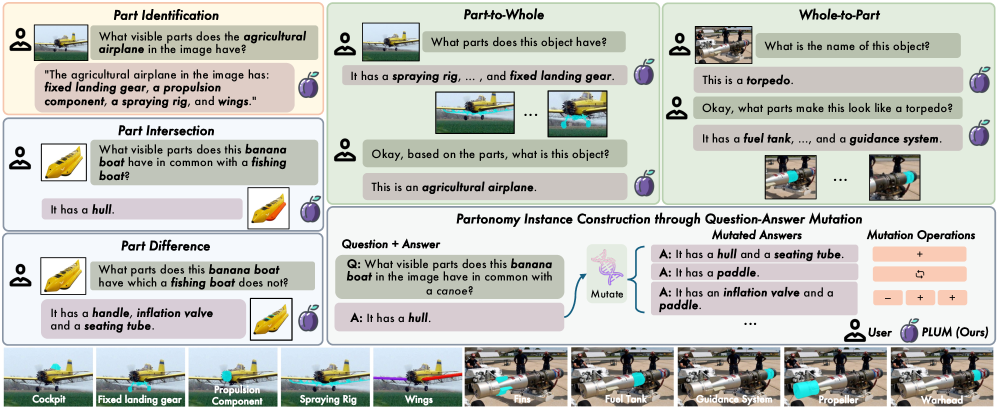
- 现有大型多模态模型在细粒度的、组合推理任务中表现不佳,尤其是在识别和定位对象特定部件方面存在困难。
- 论文提出PARTONOMY基准测试,用于评估模型在像素级别部件定位的能力,并设计了PLUM模型,通过span tagging和反馈循环来提升性能。
- 实验结果表明,PLUM模型在推理分割、VQA和视觉幻觉等基准测试中优于现有模型,并在解释性部件分割任务上表现出竞争力。
📝 摘要(中文)
本文提出了PARTONOMY,一个用于像素级部件定位的大型多模态模型(LMM)基准。PARTONOMY由现有的部件数据集和作者们严格标注的图像集构成,包含862个部件标签和534个对象标签用于评估。与现有仅要求模型识别通用部件的数据集不同,PARTONOMY使用专业概念(例如,农业飞机),并挑战模型比较对象的部件、考虑部件-整体关系,以及使用视觉分割来证明文本预测的合理性。实验表明,现有最先进的LMM存在显著局限性(例如,LISA-13B仅达到5.9%的gIoU),突出了其部件定位能力的关键差距。作者们指出,现有的支持分割的LMM(segmenting LMMs)存在两个关键的架构缺陷:它们使用预训练期间未见过的特殊[SEG] tokens,导致分布偏移;并且它们丢弃了预测的分割,而不是使用过去的预测来指导未来的预测。为了解决这些缺陷,作者们训练了几个以部件为中心的LMM,并提出了PLUM,一种新颖的segmenting LMM,它使用span tagging代替分割tokens,并在反馈循环中以先前的预测为条件。预训练的PLUM在推理分割、VQA和视觉幻觉基准测试中优于现有的segmenting LMM。此外,在作者们提出的解释性部件分割任务上进行微调的PLUM与在更多分割数据上训练的segmenting LMM具有竞争力。这项工作为实现LMM中细粒度的、基于基础的视觉理解开辟了新的途径。
🔬 方法详解
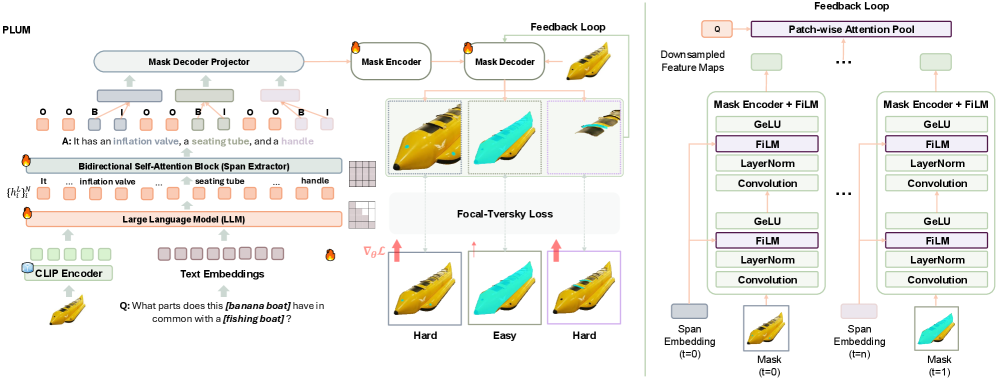
问题定义:现有的大型多模态模型(LMMs)在理解图像中细粒度的部件信息方面存在不足。它们难以准确地识别和定位物体中具有区分性的、特定于对象的部件,这限制了它们在需要组合推理的任务中的表现。现有的分割LMMs存在两个主要问题:一是使用预训练中未见过的特殊分割token,导致分布偏移;二是丢弃了预测的分割结果,没有利用这些信息来指导后续的预测。
核心思路:论文的核心思路是通过构建一个更具挑战性的部件定位基准测试(PARTONOMY)来暴露现有LMM的不足,并设计一种新的分割LMM(PLUM)来解决现有模型的架构缺陷。PLUM通过使用span tagging代替分割token,避免了分布偏移,并通过反馈循环利用先前的预测结果来指导后续的预测,从而提升部件定位的准确性。
技术框架:PLUM模型的整体框架是一个encoder-decoder结构,其中encoder负责提取图像和文本的特征,decoder负责生成分割结果。与传统的分割LMM不同,PLUM使用span tagging来表示分割结果,而不是使用特殊的[SEG] token。此外,PLUM还引入了一个反馈循环,将先前的预测结果作为输入,指导后续的预测。这个反馈循环允许模型逐步细化分割结果,并利用上下文信息来提高准确性。
关键创新:PLUM模型的主要创新点在于:1) 使用span tagging代替分割token,避免了分布偏移;2) 引入反馈循环,利用先前的预测结果来指导后续的预测。这两个创新点有效地解决了现有分割LMM的架构缺陷,并显著提升了部件定位的准确性。
关键设计:PLUM模型的关键设计包括:1) 使用预训练的语言模型作为decoder,以利用其强大的语言生成能力;2) 设计了一个专门的损失函数,用于训练span tagging模型;3) 使用了一种注意力机制,将先前的预测结果与当前的输入进行融合。
🖼️ 关键图片

📊 实验亮点
实验结果表明,PLUM模型在PARTONOMY基准测试中显著优于现有的LMM,例如在推理分割任务中取得了显著的性能提升。此外,PLUM模型在VQA和视觉幻觉等基准测试中也表现出竞争力,证明了其在细粒度视觉理解方面的优势。在作者们提出的解释性部件分割任务上进行微调的PLUM与在更多分割数据上训练的segmenting LMM具有竞争力。
🎯 应用场景
该研究成果可应用于机器人视觉、自动驾驶、智能制造等领域。例如,机器人可以利用部件级视觉理解来更好地识别和操作物体;自动驾驶系统可以利用部件信息来更准确地识别交通标志和车辆;智能制造系统可以利用部件信息来检测产品缺陷。
📄 摘要(原文)
Real-world objects are composed of distinctive, object-specific parts. Identifying these parts is key to performing fine-grained, compositional reasoning-yet, large multimodal models (LMMs) struggle to perform this seemingly straightforward task. In this work, we introduce PARTONOMY, an LMM benchmark designed for pixel-level part grounding. We construct PARTONOMY from existing part datasets and our own rigorously annotated set of images, encompassing 862 part labels and 534 object labels for evaluation. Unlike existing datasets that simply ask models to identify generic parts, PARTONOMY uses specialized concepts (e.g., agricultural airplane), and challenges models to compare objects' parts, consider part-whole relationships, and justify textual predictions with visual segmentations. Our experiments demonstrate significant limitations in state-of-the-art LMMs (e.g., LISA-13B achieves only 5.9% gIoU), highlighting a critical gap in their part grounding abilities. We note that existing segmentation-enabled LMMs (segmenting LMMs) have two key architectural shortcomings: they use special [SEG] tokens not seen during pretraining which induce distribution shift, and they discard predicted segmentations instead of using past predictions to guide future ones. To address these deficiencies, we train several part-centric LMMs and propose PLUM, a novel segmenting LMM that uses span tagging instead of segmentation tokens and that conditions on prior predictions in a feedback loop. We find that pretrained PLUM outperforms existing segmenting LMMs on reasoning segmentation, VQA, and visual hallucination benchmarks. In addition, PLUM finetuned on our proposed Explanatory Part Segmentation task is competitive with segmenting LMMs trained on significantly more segmentation data. Our work opens up new avenues towards enabling fine-grained, grounded visual understanding in LMMs.