OccLE: Label-Efficient 3D Semantic Occupancy Prediction
作者: Naiyu Fang, Zheyuan Zhou, Fayao Liu, Xulei Yang, Jiacheng Wei, Lemiao Qiu, Hongsheng Li, Guosheng Lin
分类: cs.CV
发布日期: 2025-05-27 (更新: 2026-01-22)
🔗 代码/项目: GITHUB
💡 一句话要点
OccLE:一种标签高效的3D语义占据预测方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D语义占据预测 标签高效学习 自动驾驶 跨模态融合 伪标签 几何学习 语义学习
📋 核心要点
- 现有3D语义占据预测方法依赖大量体素级标注或效果有限的自监督,成本高昂且性能受限。
- OccLE解耦语义和几何学习,利用2D基础模型生成伪标签,并结合跨平面协同的半监督几何学习。
- 实验表明,OccLE仅使用10%的体素标注,在SemanticKITTI和Occ3D-nuScenes数据集上实现了有竞争力的性能。
📝 摘要(中文)
3D语义占据预测提供了一种直观高效的场景理解方式,在自动驾驶感知领域引起了广泛关注。现有方法要么依赖于全监督,需要昂贵的体素级标注,要么依赖于自监督,提供的指导有限,导致性能欠佳。为了解决这些挑战,我们提出了OccLE,一种标签高效的3D语义占据预测方法,它以图像和激光雷达作为输入,并在有限的体素标注下保持高性能。我们的直觉是将语义和几何学习任务解耦,然后融合来自这两个任务的学习特征网格,用于最终的语义占据预测。因此,语义分支提炼2D基础模型,为2D和3D语义学习提供对齐的伪标签。几何分支基于图像和激光雷达的内在特性,在跨平面协同中集成图像和激光雷达输入,采用半监督来增强几何学习。我们通过Dual Mamba融合语义-几何特征网格,并结合散射累积投影来使用对齐的伪标签监督未标注的预测。实验表明,OccLE在SemanticKITTI和Occ3D-nuScenes数据集上仅使用10%的体素标注即可实现具有竞争力的性能。代码将在https://github.com/NerdFNY/OccLE上公开发布。
🔬 方法详解
问题定义:论文旨在解决3D语义占据预测中,对大量体素级标注的依赖问题。现有方法要么需要全监督,标注成本高昂;要么采用自监督,但性能往往不尽如人意。因此,如何在有限的标注下实现高性能的3D语义占据预测是本研究的核心问题。
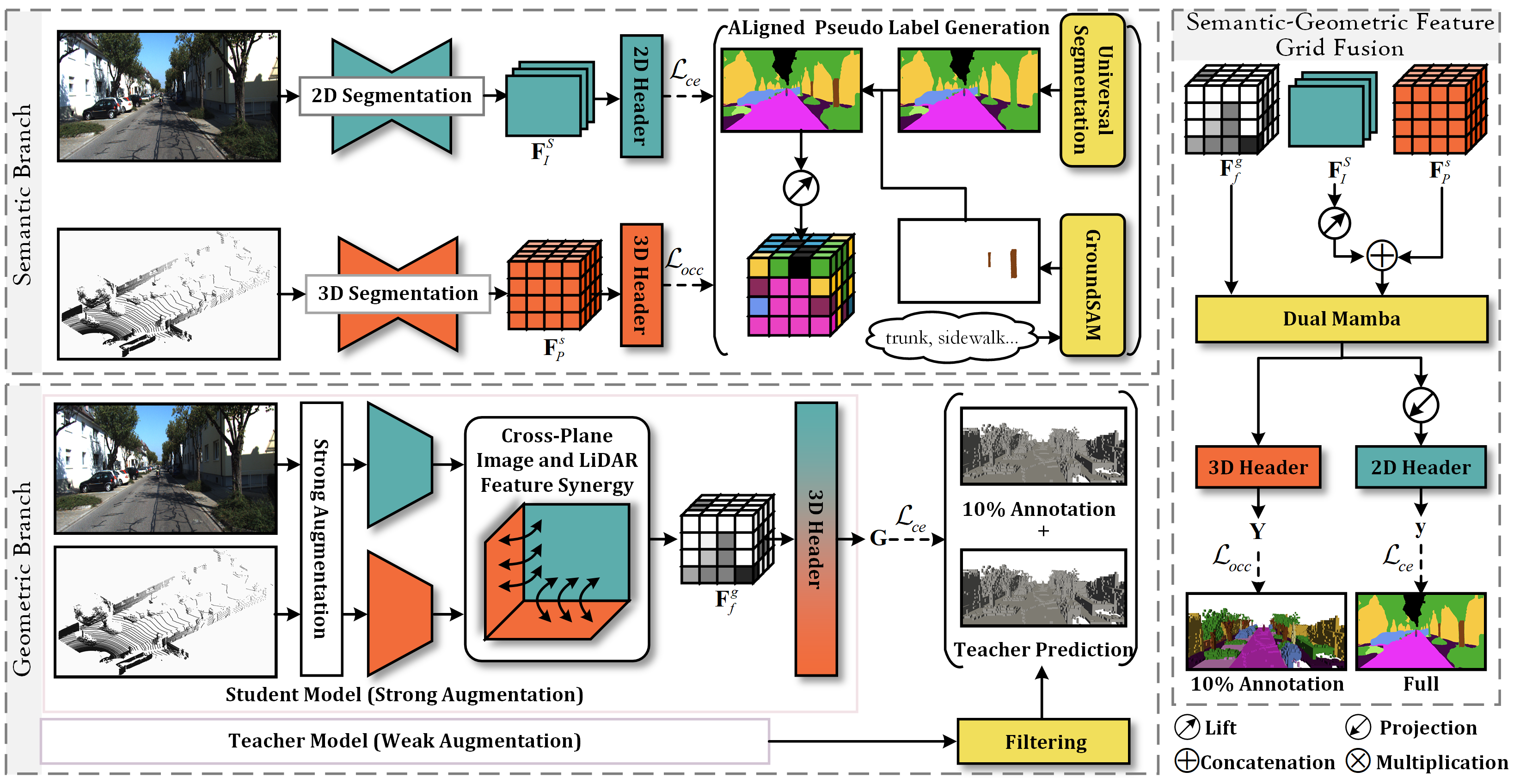
核心思路:OccLE的核心思路是将语义学习和几何学习解耦,分别进行优化,然后融合两者的特征。语义分支负责学习场景的语义信息,几何分支负责学习场景的几何结构。通过解耦,可以更有效地利用有限的标注信息,并引入外部知识(如2D基础模型)来提升性能。
技术框架:OccLE的整体框架包含语义分支和几何分支。语义分支利用2D基础模型提取图像特征,并生成伪标签,用于监督3D语义学习。几何分支融合图像和激光雷达数据,通过跨平面协同和半监督学习增强几何特征提取。最后,使用Dual Mamba模块融合语义和几何特征,并使用散射累积投影来监督未标注区域的预测。
关键创新:OccLE的关键创新在于:1) 解耦语义和几何学习,分别进行优化;2) 利用2D基础模型生成伪标签,降低对3D标注的依赖;3) 提出跨平面协同的几何特征提取方法,有效融合图像和激光雷达数据;4) 使用Dual Mamba模块进行特征融合,提升性能。与现有方法相比,OccLE在标签效率方面具有显著优势。
关键设计:语义分支使用预训练的2D基础模型(具体模型未知)提取图像特征,并生成伪标签。几何分支采用跨平面注意力机制(具体实现未知)融合图像和激光雷达数据。Dual Mamba模块的具体结构和参数设置未知。损失函数包括语义分割损失、几何重建损失和一致性损失(具体形式未知)。散射累积投影的具体实现方式未知。
🖼️ 关键图片


📊 实验亮点
OccLE在SemanticKITTI和Occ3D-nuScenes数据集上进行了实验,结果表明,仅使用10%的体素标注,OccLE即可实现与全监督方法具有竞争力的性能。具体的性能指标和提升幅度在论文中给出,但摘要中未明确提及具体数值。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、场景理解等领域。通过降低对大量标注数据的依赖,可以更经济高效地部署3D语义占据预测系统。例如,在自动驾驶中,可以利用少量标注数据和车载传感器数据,实现高精度的环境感知,提高驾驶安全性。
📄 摘要(原文)
3D semantic occupancy prediction offers an intuitive and efficient scene understanding and has attracted significant interest in autonomous driving perception. Existing approaches either rely on full supervision, which demands costly voxel-level annotations, or on self-supervision, which provides limited guidance and yields suboptimal performance. To address these challenges, we propose OccLE, a Label-Efficient 3D Semantic Occupancy Prediction that takes images and LiDAR as inputs and maintains high performance with limited voxel annotations. Our intuition is to decouple the semantic and geometric learning tasks and then fuse the learned feature grids from both tasks for the final semantic occupancy prediction. Therefore, the semantic branch distills 2D foundation model to provide aligned pseudo labels for 2D and 3D semantic learning. The geometric branch integrates image and LiDAR inputs in cross-plane synergy based on their inherency, employing semi-supervision to enhance geometry learning. We fuse semantic-geometric feature grids through Dual Mamba and incorporate a scatter-accumulated projection to supervise unannotated prediction with aligned pseudo labels. Experiments show that OccLE achieves competitive performance with only 10\% of voxel annotations on the SemanticKITTI and Occ3D-nuScenes datasets. The code will be publicly released on https://github.com/NerdFNY/OccLE