Mamba-Driven Topology Fusion for Monocular 3D Human Pose Estimation
作者: Zenghao Zheng, Lianping Yang, Jinshan Pan, Hegui Zhu
分类: cs.CV
发布日期: 2025-05-27 (更新: 2025-09-26)
💡 一句话要点
提出Mamba驱动的拓扑融合框架,提升单目3D人体姿态估计精度与效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 3D人体姿态估计 Mamba模型 拓扑融合 图卷积网络 骨骼感知 状态空间模型 单目视觉
📋 核心要点
- Transformer在3D人体姿态估计中计算量大,Mamba虽高效但缺乏对人体结构关系的建模能力。
- 提出Mamba驱动的拓扑融合框架,利用骨骼感知模块和图卷积增强Mamba对人体结构的理解。
- 实验表明,该方法在Human3.6M和MPI-INF-3DHP数据集上显著降低计算成本并提升精度。
📝 摘要(中文)
本文针对基于Transformer的3D人体姿态估计方法中自注意力机制复杂度随序列长度呈平方增长,导致计算量巨大的问题,提出了一种Mamba驱动的拓扑融合框架。该框架利用状态空间模型(SSM)Mamba在长序列建模方面的优势,显著降低计算开销。为了解决SSM不适合处理具有拓扑结构的3D关节序列以及Mamba中因果卷积结构缺乏对局部关节关系理解的问题,本文设计了骨骼感知模块,在球坐标系中推断骨骼向量的方向和长度,为Mamba模型处理关节序列提供有效的拓扑指导。此外,通过集成前向和后向图卷积网络,增强了Mamba模型中的卷积结构,使其能够更好地捕获局部关节依赖关系。最后,设计了一个时空细化模块来建模序列中的时间和空间关系。在Human3.6M和MPI-INF-3DHP数据集上的实验结果表明,该方法在大大降低计算成本的同时,实现了更高的精度。消融研究进一步证明了每个模块的有效性。
🔬 方法详解
问题定义:现有的基于Transformer的3D人体姿态估计方法,由于自注意力机制的复杂度与序列长度呈平方关系增长,导致计算量巨大,难以应用到长序列或高分辨率的场景中。虽然Mamba模型在长序列建模上表现出色,但其固有的序列处理方式不适合具有拓扑结构的3D人体关节序列,并且Mamba中的因果卷积结构缺乏对局部关节关系的有效建模能力。
核心思路:本文的核心思路是将Mamba模型与人体骨骼的拓扑结构信息进行融合,从而弥补Mamba在处理3D人体姿态估计任务时的不足。通过引入骨骼感知模块和图卷积网络,增强Mamba模型对人体结构关系的理解,使其能够更有效地处理3D关节序列。
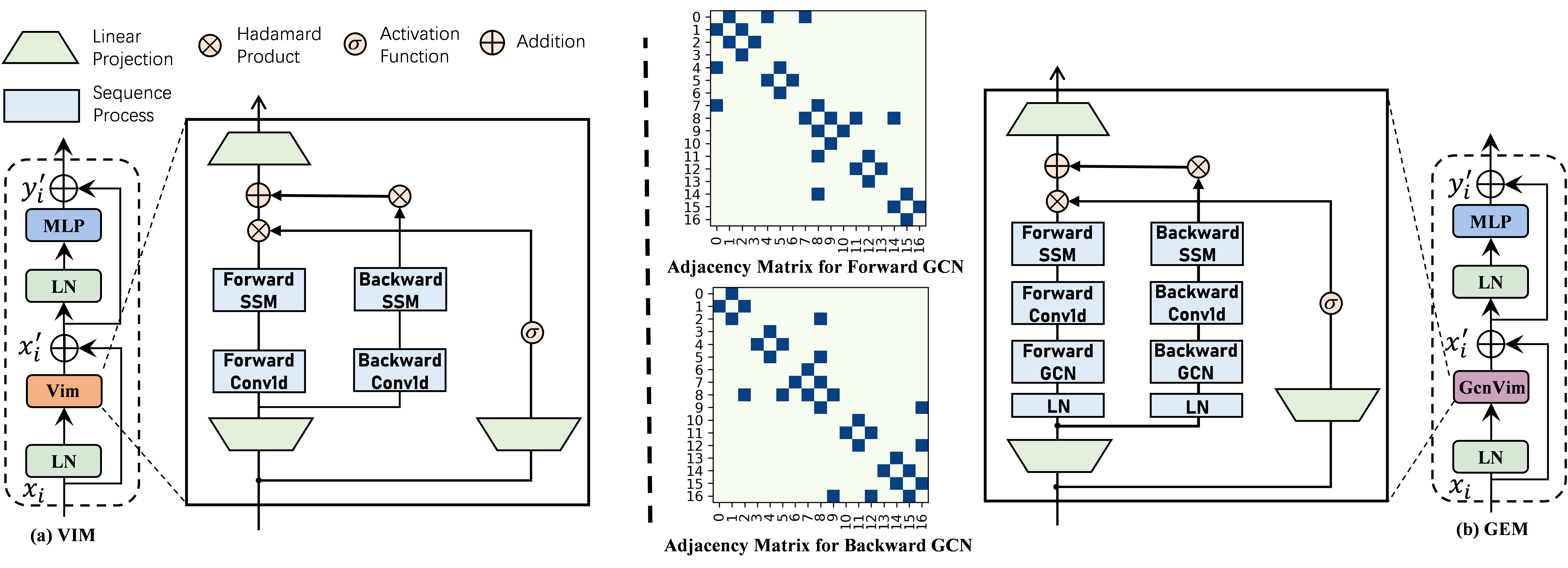
技术框架:该框架主要包含三个模块:骨骼感知模块(Bone Aware Module)、图卷积增强的Mamba模块以及时空细化模块(Spatiotemporal Refinement Module)。首先,骨骼感知模块负责推断骨骼向量的方向和长度,为后续的Mamba模型提供拓扑指导。然后,图卷积增强的Mamba模块利用前向和后向图卷积网络来捕获局部关节依赖关系。最后,时空细化模块用于建模序列中的时间和空间关系,进一步提升姿态估计的精度。
关键创新:该论文的关键创新在于将Mamba模型与人体骨骼的拓扑结构信息进行有效融合。具体来说,骨骼感知模块通过在球坐标系中推断骨骼向量的方向和长度,为Mamba模型提供了明确的拓扑指导。此外,通过集成前向和后向图卷积网络,增强了Mamba模型对局部关节依赖关系的建模能力,克服了传统Mamba模型在处理具有拓扑结构的数据时的局限性。
关键设计:骨骼感知模块的关键设计在于使用球坐标系来表示骨骼向量的方向和长度,这使得模型能够更好地学习骨骼的几何信息。图卷积增强的Mamba模块的关键设计在于同时使用前向和后向图卷积网络,从而能够更全面地捕获局部关节依赖关系。时空细化模块的具体结构和参数设置未知,需要在论文中进一步查找。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在Human3.6M和MPI-INF-3DHP数据集上取得了显著的性能提升,同时大大降低了计算成本。具体性能数据和对比基线未知,需要在论文中进一步查找。消融实验证明了骨骼感知模块、图卷积增强的Mamba模块以及时空细化模块的有效性。
🎯 应用场景
该研究成果可应用于虚拟现实、增强现实、游戏、运动分析、康复训练、人机交互等领域。通过准确高效地估计人体姿态,可以为这些应用提供更自然、更流畅的用户体验,并为运动分析和康复训练提供更精确的数据支持。未来,该方法有望扩展到更复杂的场景,例如多人交互、遮挡情况下的姿态估计等。
📄 摘要(原文)
Transformer-based methods for 3D human pose estimation face significant computational challenges due to the quadratic growth of self-attention mechanism complexity with sequence length. Recently, the Mamba model has substantially reduced computational overhead and demonstrated outstanding performance in modeling long sequences by leveraging state space model (SSM). However, the ability of SSM to process sequential data is not suitable for 3D joint sequences with topological structures, and the causal convolution structure in Mamba also lacks insight into local joint relationships. To address these issues, we propose the Mamba-Driven Topology Fusion framework in this paper. Specifically, the proposed Bone Aware Module infers the direction and length of bone vectors in the spherical coordinate system, providing effective topological guidance for the Mamba model in processing joint sequences. Furthermore, we enhance the convolutional structure within the Mamba model by integrating forward and backward graph convolutional network, enabling it to better capture local joint dependencies. Finally, we design a Spatiotemporal Refinement Module to model both temporal and spatial relationships within the sequence. Through the incorporation of skeletal topology, our approach effectively alleviates Mamba's limitations in capturing human structural relationships. We conduct extensive experiments on the Human3.6M and MPI-INF-3DHP datasets for testing and comparison, and the results show that the proposed method greatly reduces computational cost while achieving higher accuracy. Ablation studies further demonstrate the effectiveness of each proposed module. The code and models will be released.