MMPerspective: Do MLLMs Understand Perspective? A Comprehensive Benchmark for Perspective Perception, Reasoning, and Robustness
作者: Yolo Y. Tang, Pinxin Liu, Zhangyun Tan, Mingqian Feng, Rui Mao, Chao Huang, Jing Bi, Yunzhong Xiao, Susan Liang, Hang Hua, Ali Vosoughi, Luchuan Song, Zeliang Zhang, Chenliang Xu
分类: cs.CV
发布日期: 2025-05-26 (更新: 2025-11-25)
备注: Accepted to NeurIPS 2025 DB Track. Rating: 5,5,5,5
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
MMPerspective:首个多模态大语言模型透视理解能力综合评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 透视理解 视觉感知 空间推理 基准数据集
📋 核心要点
- 现有MLLM在透视几何理解方面能力未知,缺乏系统性的评估方法。
- 构建MMPerspective基准,包含感知、推理和鲁棒性三个维度,共10个任务。
- 评估43个MLLM,发现模型在组合推理和空间一致性方面存在不足,并分析了模型架构、规模与透视能力的关系。
📝 摘要(中文)
透视理解是人类视觉感知的基本能力,但多模态大语言模型(MLLM)在多大程度上内化了透视几何仍然不清楚。我们提出了MMPerspective,这是第一个专门设计的基准,旨在通过10个精心设计的任务,从透视感知、推理和鲁棒性三个互补维度系统地评估MLLM对透视的理解。我们的基准包含2711个真实和合成图像实例,以及5083个问答对,用于探测关键能力,如消失点感知和计数、透视类型推理、3D空间中的线条关系理解、透视保持变换的不变性等。通过对43个最先进的MLLM的全面评估,我们发现了显著的局限性:虽然模型在表面感知任务上表现出能力,但它们在组合推理和在扰动下保持空间一致性方面存在困难。我们的分析进一步揭示了模型架构、规模和透视能力之间有趣的模式,突出了鲁棒性瓶颈以及思维链提示的好处。MMPerspective为诊断和推进视觉语言系统中的空间理解建立了一个有价值的测试平台。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLMs)是否真正理解透视几何的问题。现有方法缺乏针对透视理解能力的系统性评估,无法准确衡量MLLMs在空间推理方面的能力。现有的视觉语言任务通常侧重于物体识别、场景描述等,而忽略了对图像中透视关系的理解。
核心思路:论文的核心思路是构建一个专门用于评估MLLMs透视理解能力的基准数据集MMPerspective。该基准包含多种任务,涵盖透视感知、透视推理和透视鲁棒性三个维度,通过精心设计的图像和问题,系统性地测试MLLMs在不同方面的透视理解能力。通过分析MLLMs在这些任务上的表现,可以深入了解其在空间推理方面的优势和不足。
技术框架:MMPerspective基准包含以下几个主要模块: 1. 图像数据集:包含真实图像和合成图像,涵盖不同的场景和透视类型。 2. 任务设计:设计了10个任务,包括消失点检测、透视类型识别、3D空间中的线条关系理解等。 3. 评估指标:针对每个任务设计了相应的评估指标,用于衡量MLLMs的性能。 4. MLLM评估:使用MMPerspective基准评估了43个最先进的MLLMs。
关键创新:MMPerspective是第一个专门针对MLLMs透视理解能力设计的基准数据集。它通过精心设计的任务和图像,系统性地评估了MLLMs在透视感知、推理和鲁棒性方面的能力。该基准的提出填补了现有视觉语言评估体系的空白,为研究MLLMs的空间推理能力提供了新的工具。
关键设计:MMPerspective基准的关键设计包括: 1. 多样化的图像数据集:包含真实图像和合成图像,以保证基准的泛化能力。 2. 精心设计的任务:任务设计涵盖了透视理解的各个方面,包括感知、推理和鲁棒性。 3. 细粒度的评估指标:针对每个任务设计了相应的评估指标,以便更准确地衡量MLLMs的性能。 4. 全面的MLLM评估:评估了43个最先进的MLLMs,以便更全面地了解MLLMs在透视理解方面的能力。
🖼️ 关键图片

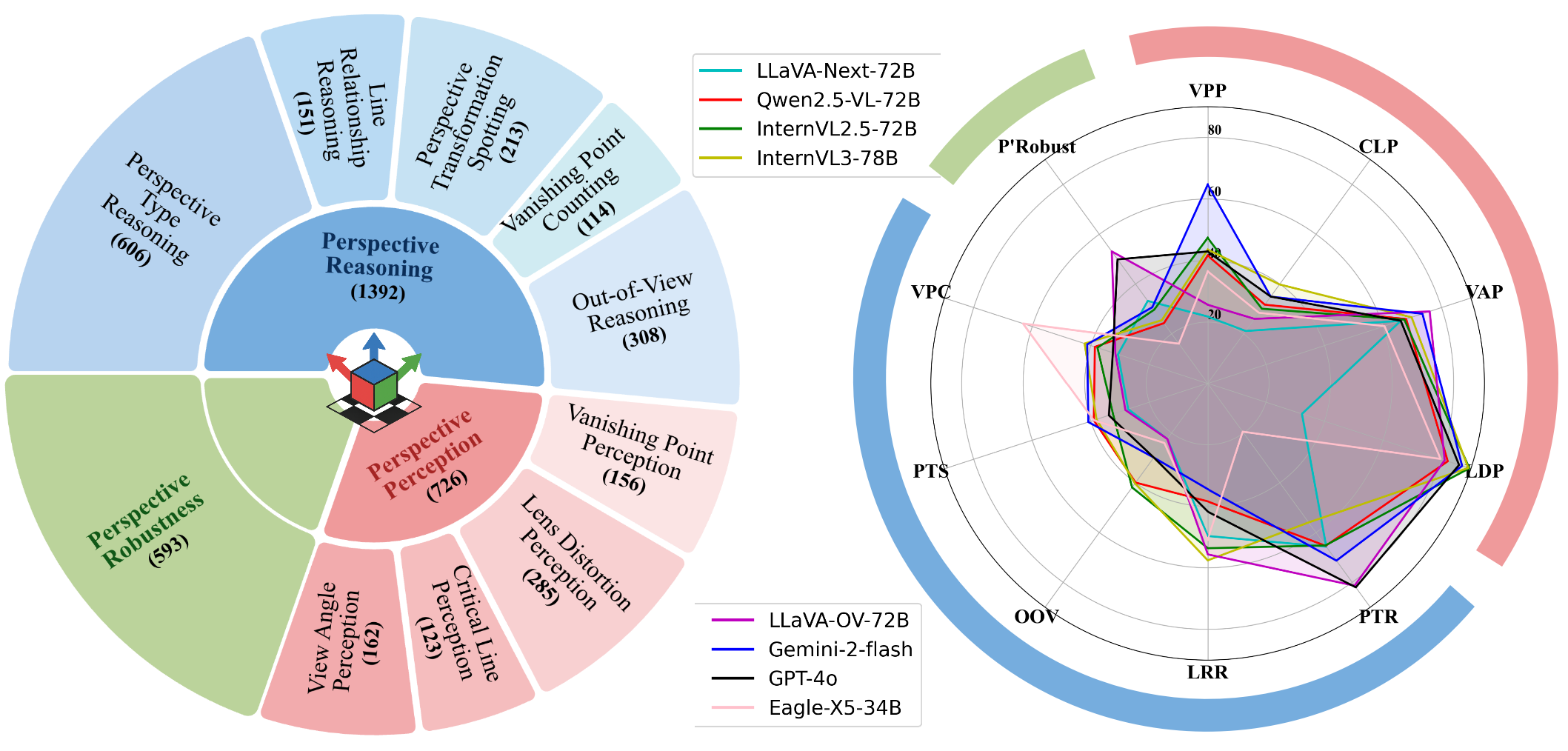

📊 实验亮点
实验结果表明,现有MLLM在表面感知任务上表现良好,但在组合推理和空间一致性方面存在不足。例如,模型在消失点检测任务上表现尚可,但在理解3D空间中的线条关系方面表现较差。此外,研究还发现模型架构、规模和透视能力之间存在一定的关联性,思维链提示可以提升模型的性能。
🎯 应用场景
该研究成果可应用于提升机器人导航、自动驾驶、增强现实等领域中视觉系统的空间理解能力。通过更准确地理解图像中的透视关系,可以提高这些系统在复杂环境中的感知和决策能力。此外,该基准数据集可促进多模态大语言模型在空间推理方面的研究进展。
📄 摘要(原文)
Understanding perspective is fundamental to human visual perception, yet the extent to which multimodal large language models (MLLMs) internalize perspective geometry remains unclear. We introduce MMPerspective, the first benchmark specifically designed to systematically evaluate MLLMs' understanding of perspective through 10 carefully crafted tasks across three complementary dimensions: Perspective Perception, Reasoning, and Robustness. Our benchmark comprises 2,711 real-world and synthetic image instances with 5,083 question-answer pairs that probe key capabilities, such as vanishing point perception and counting, perspective type reasoning, line relationship understanding in 3D space, invariance to perspective-preserving transformations, etc. Through a comprehensive evaluation of 43 state-of-the-art MLLMs, we uncover significant limitations: while models demonstrate competence on surface-level perceptual tasks, they struggle with compositional reasoning and maintaining spatial consistency under perturbations. Our analysis further reveals intriguing patterns between model architecture, scale, and perspective capabilities, highlighting both robustness bottlenecks and the benefits of chain-of-thought prompting. MMPerspective establishes a valuable testbed for diagnosing and advancing spatial understanding in vision-language systems. Resources available at: https://yunlong10.github.io/MMPerspective/