MMGeoLM: Hard Negative Contrastive Learning for Fine-Grained Geometric Understanding in Large Multimodal Models
作者: Kai Sun, Yushi Bai, Zhen Yang, Jiajie Zhang, Ji Qi, Lei Hou, Juanzi Li
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-05-26 (更新: 2025-10-01)
🔗 代码/项目: GITHUB
💡 一句话要点
MMGeoLM:通过难负例对比学习提升大模型在几何场景中的细粒度理解能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 几何推理 难负例对比学习 视觉编码器 大型语言模型
📋 核心要点
- 现有LMMs在几何场景中难以捕捉细粒度视觉差异,限制了几何推理能力。
- 提出MMGeoLM,通过结合图像和文本的难负例对比学习,提升视觉编码器性能。
- 实验表明,MMGeoLM在几何推理任务上显著优于其他开源模型,甚至媲美GPT-4o。
📝 摘要(中文)
大型多模态模型(LMMs)通常基于ViT(例如CLIP)构建,但使用简单的随机批内负例进行训练限制了其捕获细粒度视觉差异的能力,尤其是在几何场景中。为了解决这个挑战,我们提出了一种新的视觉编码器难负例对比学习框架,该框架结合了基于图像的对比学习(使用通过扰动图表生成代码创建的基于生成的难负例)和基于文本的对比学习(使用从修改后的几何描述中导出的基于规则的负例,以及基于标题相似性选择的基于检索的负例)。我们使用我们的难负例训练方法训练了一个视觉编码器(CLIP),即MMCLIP(多模态数学CLIP),然后训练一个用于解决几何问题的大型多模态模型。实验表明,我们训练的模型MMGeoLM在三个几何推理基准测试中显著优于其他开源模型。即使只有7B的大小,它也能与像GPT-4o这样强大的闭源模型相媲美。我们进一步进行了消融研究,以分析三个关键因素:难负例类型、基于图像的负例的效率以及训练配置。这些分析为优化视觉编码器在细粒度几何推理任务中的训练流程提供了重要的见解。
🔬 方法详解
问题定义:现有的大型多模态模型在处理几何问题时,由于视觉编码器在训练过程中使用了简单的随机负例,导致模型难以捕捉图像中细微的几何差异。这限制了模型在几何推理任务中的表现,尤其是在需要精确理解几何关系的情况下。
核心思路:论文的核心思路是通过引入难负例对比学习来增强视觉编码器对细粒度几何信息的感知能力。具体来说,通过生成对抗网络和规则生成等方法,构造与正例相似但具有细微差异的负例,迫使模型学习区分这些细微差异,从而提升模型的几何理解能力。
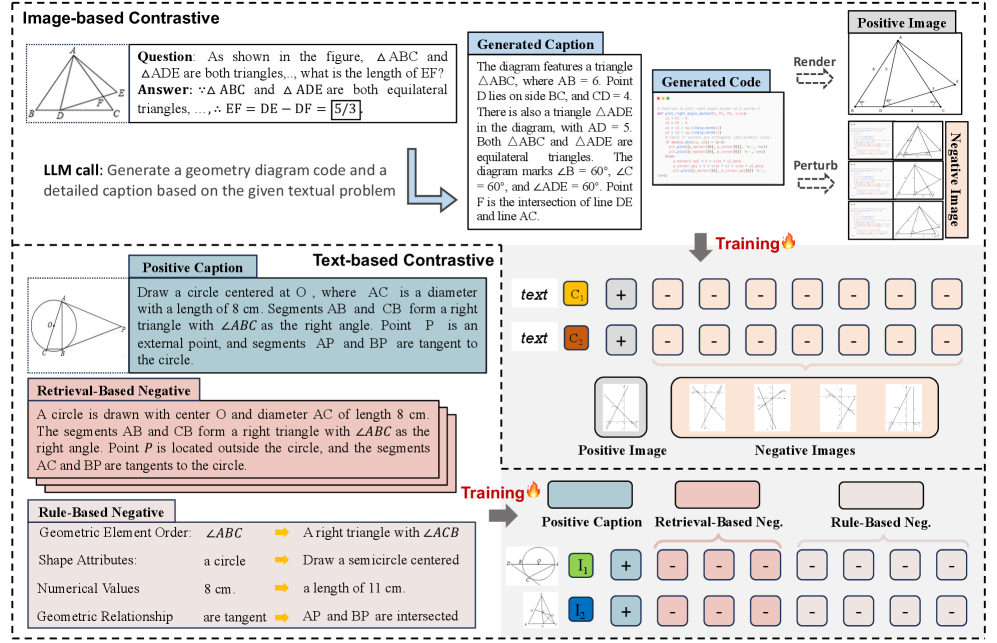
技术框架:MMGeoLM的整体框架包含两个主要阶段:首先,使用提出的难负例对比学习方法训练视觉编码器(MMCLIP);然后,将训练好的视觉编码器集成到大型多模态模型中,用于解决几何问题。难负例生成模块包含图像和文本两个分支,分别生成基于图像和文本的难负例。
关键创新:论文的关键创新在于提出了一个综合性的难负例对比学习框架,该框架结合了图像和文本两种模态的难负例生成方法。图像分支利用生成模型扰动图表生成代码来创建难负例,文本分支则利用规则和检索方法生成难负例。这种多模态难负例的结合能够更全面地提升视觉编码器的几何理解能力。
关键设计:图像分支的难负例生成依赖于对图表生成代码的扰动,扰动的方式和程度需要仔细设计,以保证生成的负例既具有挑战性,又不会过于偏离原始图像。文本分支的难负例生成则依赖于几何描述的修改和检索,需要设计合适的规则和相似度度量方法,以保证生成的负例与正例在语义上相关,但在几何细节上存在差异。损失函数采用对比学习常用的InfoNCE损失,用于拉近正例对的距离,推远负例对的距离。
🖼️ 关键图片


📊 实验亮点
MMGeoLM在三个几何推理基准测试中显著优于其他开源模型,例如在Geometry3K数据集上取得了显著的性能提升。更令人印象深刻的是,仅有7B参数的MMGeoLM能够与强大的闭源模型GPT-4o相媲美,证明了难负例对比学习在提升几何理解能力方面的有效性。
🎯 应用场景
MMGeoLM在教育、科研和工程领域具有广泛的应用前景。例如,可以用于自动几何题解答、CAD设计辅助、机器人视觉导航等。通过提升模型对几何信息的理解能力,可以实现更智能、更高效的几何问题求解和应用。
📄 摘要(原文)
Large Multimodal Models (LMMs) typically build on ViTs (e.g., CLIP), yet their training with simple random in-batch negatives limits the ability to capture fine-grained visual differences, particularly in geometric scenarios. To address this challenge, we propose a novel hard negative contrastive learning framework for the vision encoder, which combines image-based contrastive learning using generation-based hard negatives created by perturbing diagram generation code, and text-based contrastive learning using rule-based negatives derived from modified geometric descriptions and retrieval-based negatives selected based on caption similarity. We train a vision encoder (CLIP) using our hard negative training method, namely MMCLIP (Multimodal Math CLIP), and subsequently train an LMM for geometric problem-solving. Experiments show that our trained model, MMGeoLM, significantly outperforms other open-source models on three geometric reasoning benchmarks. Even with a size of 7B, it can rival powerful closed-source models like GPT-4o. We further conduct ablation studies to analyze three key factors: hard negative types, the efficiency of image-based negatives, and training configurations. These analyses yield important insights into optimizing the training pipeline of vision encoder for fine-grained geometric reasoning tasks. https://github.com/THU-KEG/MMGeoLM.