ViTaPEs: Visuotactile Position Encodings for Cross-Modal Alignment in Multimodal Transformers
作者: Fotios Lygerakis, Ozan Özdenizci, Elmar Rückert
分类: cs.CV, cs.LG, cs.RO
发布日期: 2025-05-26
💡 一句话要点
ViTaPEs:用于多模态Transformer中视觉触觉对齐的视觉触觉位置编码
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉触觉融合 多模态学习 位置编码 Transformer 机器人抓取
📋 核心要点
- 现有视觉触觉融合方法依赖预训练模型,且忽略了位置编码对多尺度空间推理的重要性,限制了泛化能力。
- ViTaPEs提出一种多尺度位置编码方案,用于捕获模态内结构和跨模态线索,实现任务无关的视觉触觉表征学习。
- 实验证明ViTaPEs在多个真实数据集上超越了现有方法,并展现出零样本泛化能力和迁移学习优势。
📝 摘要(中文)
触觉传感提供了对视觉感知具有互补作用的局部关键信息,例如纹理、柔顺性和力。尽管视觉触觉表征学习取得了最新进展,但在融合这些模态以及在没有严重依赖预训练视觉-语言模型的情况下跨任务和环境进行泛化方面仍然存在挑战。此外,现有方法没有研究位置编码,从而忽略了捕获细粒度视觉触觉相关性所需的多尺度空间推理。我们引入了ViTaPEs,这是一个基于Transformer的框架,可以稳健地集成视觉和触觉输入数据,以学习用于视觉触觉感知的任务无关表征。我们的方法利用一种新颖的多尺度位置编码方案来捕获模态内结构,同时对跨模态线索进行建模。与先前的工作不同,我们提供了视觉触觉融合方面的可证明保证,表明我们的编码是单射的、刚体运动等变的和信息保持的,并对这些属性进行了经验验证。在多个大规模真实世界数据集上的实验表明,ViTaPEs不仅超越了各种识别任务中的最先进基线,而且还展示了对未见过的、领域外场景的零样本泛化能力。我们进一步证明了ViTaPEs在机器人抓取任务中的迁移学习强度,在该任务中,它在预测抓取成功率方面优于最先进的基线。
🔬 方法详解
问题定义:论文旨在解决视觉和触觉信息融合的难题,特别是在缺乏大量预训练数据的情况下,如何有效地利用这两种模态的信息进行感知和推理。现有方法要么过度依赖预训练的视觉-语言模型,要么忽略了视觉和触觉信息之间的空间关系,导致泛化能力不足。
核心思路:论文的核心思路是设计一种能够有效编码视觉和触觉信息的位置编码方案,从而在Transformer架构中更好地融合这两种模态的信息。通过多尺度位置编码,模型能够同时捕获模态内的结构信息和模态间的关联信息,从而提高感知和推理的准确性和鲁棒性。
技术框架:ViTaPEs是一个基于Transformer的框架,它接收视觉和触觉输入数据,并使用多尺度位置编码方案对这些数据进行编码。编码后的数据被输入到Transformer编码器中,以学习视觉触觉表征。该框架包含视觉编码模块、触觉编码模块和Transformer编码器。视觉和触觉编码模块负责将原始数据转换为特征向量,多尺度位置编码模块负责对特征向量进行位置编码,Transformer编码器负责融合视觉和触觉信息并学习表征。
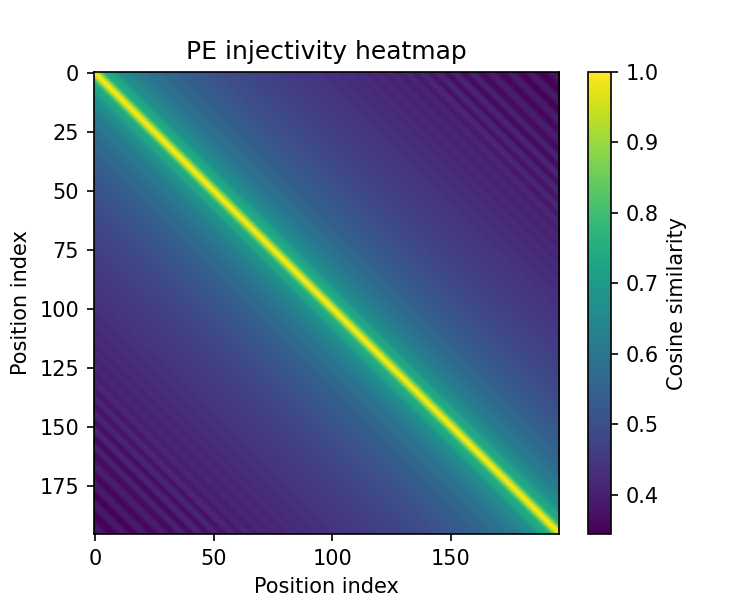
关键创新:论文的关键创新在于提出了ViTaPEs,一种新颖的多尺度位置编码方案,该方案能够同时捕获模态内的结构信息和模态间的关联信息。此外,论文还提供了视觉触觉融合方面的可证明保证,表明所提出的编码是单射的、刚体运动等变的和信息保持的。
关键设计:ViTaPEs的关键设计包括:1) 多尺度位置编码:使用不同尺度的位置编码来捕获不同粒度的空间信息。2) Transformer编码器:使用Transformer编码器来融合视觉和触觉信息。3) 可证明保证:证明了所提出的编码具有单射性、刚体运动等变性和信息保持性。损失函数根据具体任务而定,例如分类任务使用交叉熵损失,回归任务使用均方误差损失。
🖼️ 关键图片


📊 实验亮点
ViTaPEs在多个大规模真实世界数据集上进行了评估,包括视觉触觉物体识别、零样本泛化和机器人抓取任务。实验结果表明,ViTaPEs在各种识别任务中超越了最先进的基线,并且展示了对未见过的、领域外场景的零样本泛化能力。在机器人抓取任务中,ViTaPEs在预测抓取成功率方面优于最先进的基线。
🎯 应用场景
ViTaPEs在机器人操作、自动驾驶、医疗诊断等领域具有广泛的应用前景。例如,在机器人操作中,ViTaPEs可以帮助机器人更好地理解环境,从而实现更精确的抓取和操作。在自动驾驶中,ViTaPEs可以帮助车辆更好地感知周围环境,从而提高驾驶安全性。在医疗诊断中,ViTaPEs可以帮助医生更好地分析医学图像和触觉数据,从而提高诊断准确率。
📄 摘要(原文)
Tactile sensing provides local essential information that is complementary to visual perception, such as texture, compliance, and force. Despite recent advances in visuotactile representation learning, challenges remain in fusing these modalities and generalizing across tasks and environments without heavy reliance on pre-trained vision-language models. Moreover, existing methods do not study positional encodings, thereby overlooking the multi-scale spatial reasoning needed to capture fine-grained visuotactile correlations. We introduce ViTaPEs, a transformer-based framework that robustly integrates visual and tactile input data to learn task-agnostic representations for visuotactile perception. Our approach exploits a novel multi-scale positional encoding scheme to capture intra-modal structures, while simultaneously modeling cross-modal cues. Unlike prior work, we provide provable guarantees in visuotactile fusion, showing that our encodings are injective, rigid-motion-equivariant, and information-preserving, validating these properties empirically. Experiments on multiple large-scale real-world datasets show that ViTaPEs not only surpasses state-of-the-art baselines across various recognition tasks but also demonstrates zero-shot generalization to unseen, out-of-domain scenarios. We further demonstrate the transfer-learning strength of ViTaPEs in a robotic grasping task, where it outperforms state-of-the-art baselines in predicting grasp success. Project page: https://sites.google.com/view/vitapes