ReasonPlan: Unified Scene Prediction and Decision Reasoning for Closed-loop Autonomous Driving
作者: Xueyi Liu, Zuodong Zhong, Yuxin Guo, Yun-Fu Liu, Zhiguo Su, Qichao Zhang, Junli Wang, Yinfeng Gao, Yupeng Zheng, Qiao Lin, Huiyong Chen, Dongbin Zhao
分类: cs.CV, cs.AI, cs.RO
发布日期: 2025-05-26 (更新: 2025-09-22)
备注: 18 pages; 9 figures; https://github.com/Liuxueyi/ReasonPlan
🔗 代码/项目: GITHUB
💡 一句话要点
ReasonPlan:面向闭环自动驾驶的统一场景预测与决策推理框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 多模态大语言模型 闭环控制 场景预测 决策推理 模仿学习 零样本学习
📋 核心要点
- 现有基于多模态大语言模型的端到端自动驾驶方法在闭环系统中应用不足,且性能未超越传统模仿学习。
- ReasonPlan通过自监督的下一场景预测和监督的决策链式思考,提升视觉表征与驾驶环境的对齐,增强决策可解释性。
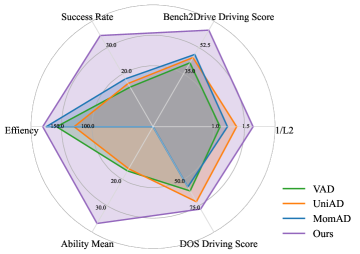
- ReasonPlan在Bench2Drive上显著优于模仿学习,并在DOS基准测试中展现出强大的零样本泛化能力。
📝 摘要(中文)
多模态大型语言模型(MLLM)凭借其强大的视觉-语言推理和泛化能力,在端到端(E2E)自动驾驶领域备受关注。然而,它们在闭环系统中的应用仍有待探索,并且目前基于MLLM的方法尚未显示出相对于主流E2E模仿学习方法的明显优势。本文提出了ReasonPlan,一种新颖的MLLM微调框架,旨在通过自监督的下一场景预测任务和监督的决策链式思考过程进行整体推理,从而实现闭环驾驶。这种双重机制鼓励模型将视觉表征与可操作的驾驶环境对齐,同时促进可解释和因果驱动的决策。我们整理了一个面向规划的决策推理数据集,即PDR,包含21万个多样化和高质量的样本。在Bench2Drive基准测试中,我们的方法优于主流E2E模仿学习方法,L2指标提升了19%,驾驶分数提升了16.1%。此外,ReasonPlan在未见过的DOS基准测试中表现出强大的零样本泛化能力,突显了其在处理零样本极端情况下的适应性。
🔬 方法详解
问题定义:现有基于多模态大语言模型的端到端自动驾驶方法,虽然具备强大的视觉-语言推理能力,但在闭环自动驾驶系统中,其性能并未显著超越传统的模仿学习方法。这些方法在将视觉信息转化为可执行的驾驶指令时,缺乏对场景的深入理解和对决策过程的合理推理,导致泛化能力不足,难以应对复杂和未知的驾驶场景。
核心思路:ReasonPlan的核心思路是通过结合自监督的下一场景预测和监督的决策链式思考,来提升模型对驾驶场景的理解和推理能力。下一场景预测任务促使模型学习预测未来场景,从而更好地理解当前场景的动态变化。决策链式思考则引导模型逐步推理决策过程,使其能够生成可解释的驾驶指令,并建立视觉表征与驾驶行为之间的因果关系。
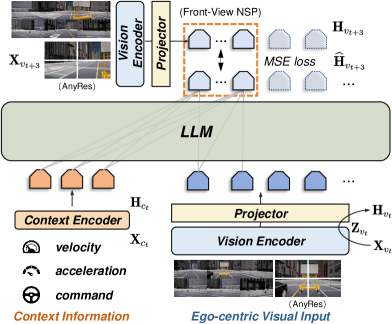
技术框架:ReasonPlan的技术框架主要包含两个关键模块:下一场景预测模块和决策链式思考模块。下一场景预测模块利用自监督学习的方式,通过预测下一时刻的场景信息来学习场景的动态表征。决策链式思考模块则通过监督学习的方式,学习从场景信息到驾驶决策的逐步推理过程。这两个模块共同作用,使得模型能够更好地理解场景,并生成合理的驾驶指令。整体流程是,首先输入当前场景的视觉信息,经过模型处理后,输出下一场景的预测以及驾驶决策的推理过程,最终生成驾驶指令。
关键创新:ReasonPlan的关键创新在于其双重机制:自监督的下一场景预测和监督的决策链式思考。这种双重机制使得模型能够同时学习场景的动态表征和决策的推理过程,从而提升了模型的泛化能力和可解释性。与现有方法相比,ReasonPlan更加注重对场景的理解和对决策过程的推理,而不仅仅是简单地模仿驾驶行为。
关键设计:ReasonPlan的关键设计包括:1) 精心设计的损失函数,用于优化下一场景预测和决策链式思考模块;2) 大规模的规划导向决策推理数据集PDR,包含21万个多样化和高质量的样本,用于训练决策链式思考模块;3) 针对MLLM的微调策略,以充分利用MLLM的视觉-语言推理能力。
🖼️ 关键图片

📊 实验亮点
ReasonPlan在Bench2Drive基准测试中,L2指标优于主流E2E模仿学习方法19%,驾驶分数提升16.1%。更重要的是,ReasonPlan在未见过的DOS基准测试中表现出强大的零样本泛化能力,证明了其在处理复杂和未知驾驶场景方面的优越性。这些实验结果表明,ReasonPlan是一种有效的闭环自动驾驶解决方案。
🎯 应用场景
ReasonPlan的研究成果可应用于各种自动驾驶场景,例如城市道路自动驾驶、高速公路自动驾驶以及特定场景下的自动驾驶(如物流配送、矿山运输等)。该方法通过提升自动驾驶系统的决策能力和泛化能力,有望提高自动驾驶的安全性和可靠性,加速自动驾驶技术的商业化落地。未来,该研究还可以扩展到其他机器人领域,例如服务机器人、工业机器人等。
📄 摘要(原文)
Due to the powerful vision-language reasoning and generalization abilities, multimodal large language models (MLLMs) have garnered significant attention in the field of end-to-end (E2E) autonomous driving. However, their application to closed-loop systems remains underexplored, and current MLLM-based methods have not shown clear superiority to mainstream E2E imitation learning approaches. In this work, we propose ReasonPlan, a novel MLLM fine-tuning framework designed for closed-loop driving through holistic reasoning with a self-supervised Next Scene Prediction task and supervised Decision Chain-of-Thought process. This dual mechanism encourages the model to align visual representations with actionable driving context, while promoting interpretable and causally grounded decision making. We curate a planning-oriented decision reasoning dataset, namely PDR, comprising 210k diverse and high-quality samples. Our method outperforms the mainstream E2E imitation learning method by a large margin of 19% L2 and 16.1 driving score on Bench2Drive benchmark. Furthermore, ReasonPlan demonstrates strong zero-shot generalization on unseen DOS benchmark, highlighting its adaptability in handling zero-shot corner cases. Code and dataset will be found in https://github.com/Liuxueyi/ReasonPlan.