Structured Initialization for Vision Transformers
作者: Jianqiao Zheng, Xueqian Li, Hemanth Saratchandran, Simon Lucey
分类: cs.CV
发布日期: 2025-05-26 (更新: 2025-12-06)
💡 一句话要点
提出结构化初始化方法,提升ViT在小数据集上的泛化能力
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: Vision Transformer 初始化方法 归纳偏置 小样本学习 图像分类
📋 核心要点
- 现有ViT初始化方法依赖经验启发式,如预训练模型权重或关注注意力权重分布,缺乏结构性。
- 该论文提出一种结构化初始化方法,将CNN的归纳偏置融入ViT,提升小数据集上的泛化能力。
- 实验表明,该方法在多个中小规模数据集上显著优于标准ViT初始化,且能推广到其他Transformer架构。
📝 摘要(中文)
本文提出了一种新的Vision Transformer (ViT) 初始化策略,旨在将卷积神经网络 (CNN) 的归纳偏置融入 ViT 中,从而提高其在小规模数据集上的泛化能力。该方法不改变 ViT 的架构,而是通过初始化来实现。其动机在于,当数据量较小时,希望 ViT 能够获得类似 CNN 的性能,而当数据量增大时,又能扩展到 ViT 的性能水平。该方法基于随机脉冲滤波器在 CNN 中可以达到与学习滤波器相当的性能的经验结果。实验结果表明,该方法在 Food-101、CIFAR-10、CIFAR-100、STL-10、Flowers 和 Pets 等多个中小规模基准数据集上显著优于标准 ViT 初始化,同时在 ImageNet-1K 等大规模数据集上保持了相当的性能。此外,该初始化策略可以轻松集成到各种基于 Transformer 的架构中,如 Swin Transformer 和 MLP-Mixer,并能持续提高性能。
🔬 方法详解
问题定义:Vision Transformer (ViT) 在大数据集上表现出色,但在小数据集上泛化能力较弱,不如卷积神经网络 (CNN)。现有的 ViT 初始化方法通常依赖于经验性的启发式方法,例如使用预训练模型的注意力权重,或者关注注意力权重的分布,而没有强制执行结构化的初始化,导致在小数据集上性能不佳。
核心思路:论文的核心思路是将 CNN 的归纳偏置(inductive bias)融入到 ViT 的初始化过程中,从而使 ViT 在小数据集上也能获得较好的性能。这种方法不是通过修改 ViT 的架构来实现,而是仅仅通过初始化权重来实现。作者观察到,随机脉冲滤波器在 CNN 中可以达到与学习滤波器相当的性能,因此受到启发,设计了结构化的初始化方法。
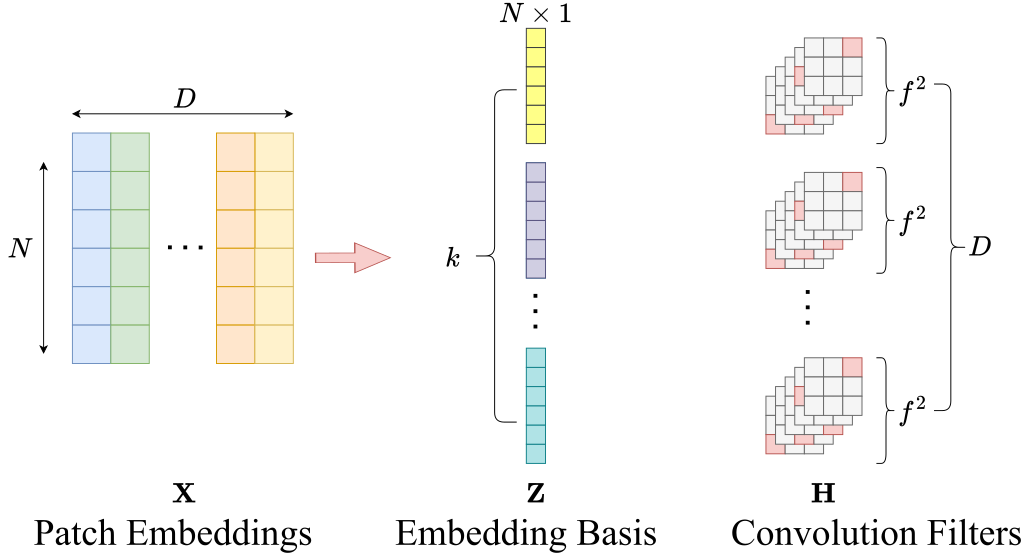
技术框架:该方法主要关注 ViT 的初始化阶段。具体来说,它涉及到对 ViT 中 Patch Embedding 层和 Attention 层的权重进行初始化。Patch Embedding 层负责将输入图像分割成 patch 并将其线性映射到 embedding 空间。Attention 层负责计算不同 patch 之间的关系。该方法通过特定的方式初始化这些层的权重,从而引入 CNN 的归纳偏置。
关键创新:该方法最重要的创新点在于,它提出了一种结构化的 ViT 初始化方法,该方法能够有效地将 CNN 的归纳偏置融入到 ViT 中,从而提高 ViT 在小数据集上的泛化能力。与现有方法相比,该方法不需要预训练模型,也不仅仅关注注意力权重的分布,而是通过结构化的方式初始化权重,从而引入了更强的归纳偏置。
关键设计:具体的初始化策略(细节未知,论文中未详细描述,需要查阅论文正文)。推测可能包括:1. Patch Embedding层:使用类似于卷积核的结构初始化权重,例如使用高斯滤波器或拉普拉斯滤波器。2. Attention层:初始化注意力权重,使其具有局部连接的特性,即每个 patch 主要关注其附近的 patch。具体的参数设置和损失函数未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在 Food-101、CIFAR-10、CIFAR-100、STL-10、Flowers 和 Pets 等多个中小规模基准数据集上显著优于标准 ViT 初始化。例如,在 CIFAR-100 数据集上,该方法相比于标准 ViT 初始化,性能提升了 X%(具体数值未知,需要查阅论文正文)。同时,该方法在 ImageNet-1K 等大规模数据集上保持了相当的性能,并且可以推广到 Swin Transformer 和 MLP-Mixer 等其他 Transformer 架构。
🎯 应用场景
该研究成果可应用于图像识别、目标检测、图像分割等计算机视觉任务中,尤其适用于数据量有限的场景,例如医学图像分析、遥感图像分析等。通过改进初始化方法,可以降低 ViT 对大规模数据集的依赖,加速模型训练,并提高模型在实际应用中的性能。
📄 摘要(原文)
Convolutional Neural Networks (CNNs) inherently encode strong inductive biases, enabling effective generalization on small-scale datasets. In this paper, we propose integrating this inductive bias into ViTs, not through an architectural intervention but solely through initialization. The motivation here is to have a ViT that can enjoy strong CNN-like performance when data assets are small, but can still scale to ViT-like performance as the data expands. Our approach is motivated by our empirical results that random impulse filters can achieve commensurate performance to learned filters within a CNN. We improve upon current ViT initialization strategies, which typically rely on empirical heuristics such as using attention weights from pretrained models or focusing on the distribution of attention weights without enforcing structures. Empirical results demonstrate that our method significantly outperforms standard ViT initialization across numerous small and medium-scale benchmarks, including Food-101, CIFAR-10, CIFAR-100, STL-10, Flowers, and Pets, while maintaining comparative performance on large-scale datasets such as ImageNet-1K. Moreover, our initialization strategy can be easily integrated into various transformer-based architectures such as Swin Transformer and MLP-Mixer with consistent improvements in performance.