Vad-R1: Towards Video Anomaly Reasoning via Perception-to-Cognition Chain-of-Thought
作者: Chao Huang, Benfeng Wang, Jie Wen, Chengliang Liu, Wei Wang, Li Shen, Xiaochun Cao
分类: cs.CV
发布日期: 2025-05-26
备注: 9 pages, 4 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出Vad-R1,通过感知-认知链式思考实现视频异常推理
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频异常检测 视频异常推理 多模态大语言模型 链式思考 强化学习
📋 核心要点
- 现有基于MLLM的视频异常检测方法缺乏深度推理能力,仅限于浅层的异常描述。
- Vad-R1通过感知-认知链式思考(P2C-CoT)模拟人类识别异常的过程,引导MLLM逐步推理。
- 提出的AVA-GRPO强化学习算法,通过自验证机制,有效提升了MLLM的异常推理能力,实验效果显著。
📝 摘要(中文)
本文提出了一种新的任务:视频异常推理(VAR),旨在通过要求多模态大型语言模型(MLLM)在回答前进行显式思考,从而实现对视频中异常的深度分析和理解。为此,我们提出了Vad-R1,一个基于MLLM的端到端VAR框架。具体来说,我们设计了一种感知-认知链式思考(P2C-CoT)方法,模拟人类识别异常的过程,引导MLLM逐步推理异常。基于结构化的P2C-CoT,我们构建了Vad-Reasoning,一个专门用于VAR的数据集。此外,我们提出了一种改进的强化学习算法AVA-GRPO,通过带有有限标注的自验证机制,显式地激励MLLM的异常推理能力。实验结果表明,Vad-R1取得了优异的性能,在VAD和VAR任务上均优于开源和专有模型。
🔬 方法详解
问题定义:现有基于多模态大型语言模型(MLLM)的视频异常检测(VAD)方法,虽然在视觉任务上取得了进展,但它们通常只能提供浅层的异常描述,缺乏对异常事件进行深度分析和推理的能力。因此,如何让MLLM能够像人类一样,逐步思考并理解视频中的异常事件,成为了一个亟待解决的问题。
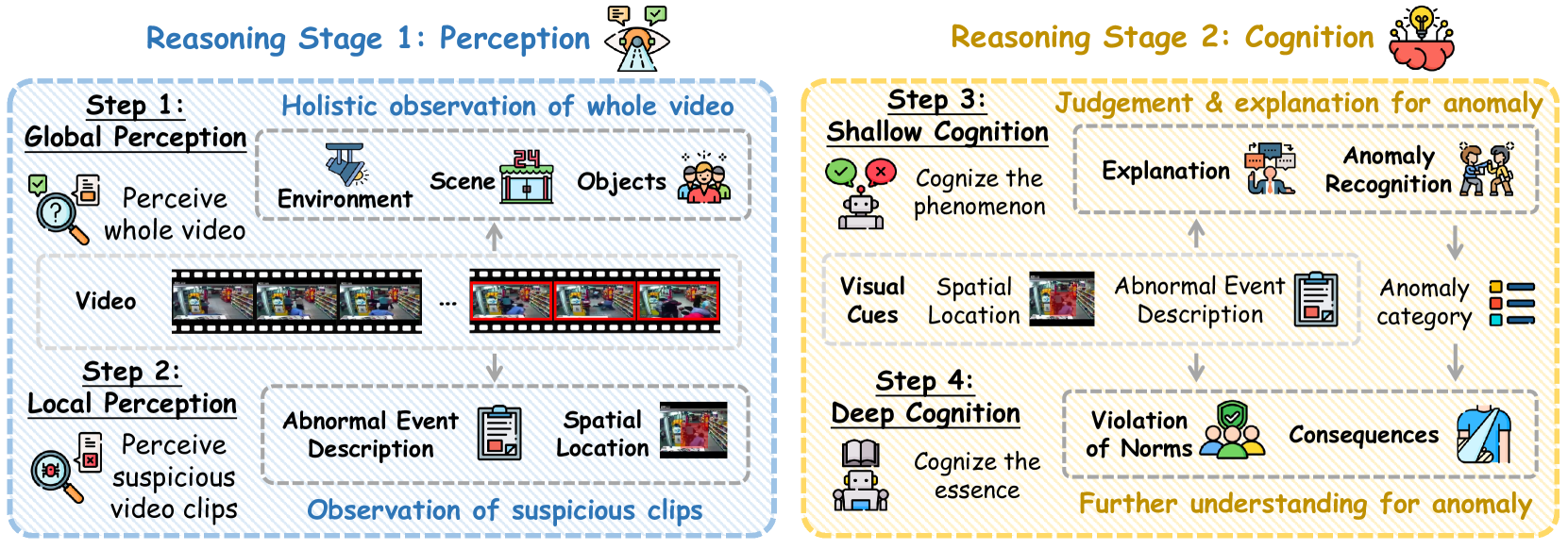
核心思路:本文的核心思路是模拟人类识别异常的认知过程,设计一种感知-认知链式思考(P2C-CoT)方法。P2C-CoT将异常推理过程分解为多个步骤,引导MLLM逐步进行感知、分析和推理,从而实现对异常事件的深度理解。这种方法借鉴了人类的思维模式,使得MLLM能够更好地理解视频内容并进行推理。
技术框架:Vad-R1是一个端到端的MLLM框架,主要包含以下几个模块:1) 视频特征提取模块:用于提取视频帧的视觉特征。2) 感知模块:将视觉特征输入MLLM,使其感知视频内容。3) 认知模块:通过P2C-CoT引导MLLM逐步进行异常推理。4) 答案生成模块:根据推理结果生成最终的异常描述。整个流程从视频感知开始,逐步过渡到认知推理,最终生成对异常事件的全面理解。
关键创新:本文最重要的技术创新点在于提出了感知-认知链式思考(P2C-CoT)方法和AVA-GRPO强化学习算法。P2C-CoT模拟了人类的认知过程,使得MLLM能够更好地理解视频内容并进行推理。AVA-GRPO则通过自验证机制,显式地激励MLLM的异常推理能力,从而进一步提升了模型的性能。与现有方法相比,Vad-R1能够进行更深层次的异常推理,提供更全面的异常描述。
关键设计:P2C-CoT的关键设计在于如何将异常推理过程分解为多个步骤,并设计合适的提示语引导MLLM进行推理。AVA-GRPO的关键设计在于如何设计自验证机制,以及如何利用有限的标注数据进行强化学习。具体的参数设置、损失函数和网络结构等细节,需要在实际应用中进行调整和优化。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Vad-R1在视频异常检测和视频异常推理任务上均取得了优异的性能,显著优于现有的开源和专有模型。具体而言,Vad-R1在Vad-Reasoning数据集上取得了显著的提升,证明了其在深度异常推理方面的优势。提出的AVA-GRPO强化学习算法也有效地提升了模型的性能。
🎯 应用场景
该研究成果可应用于智能监控、自动驾驶、医疗影像分析等领域。例如,在智能监控中,Vad-R1可以帮助自动识别异常行为,提高安全防范能力。在自动驾驶中,它可以帮助车辆识别潜在的危险情况,提高驾驶安全性。在医疗影像分析中,它可以帮助医生识别病灶,提高诊断效率和准确性。未来,该技术有望在更多领域发挥重要作用。
📄 摘要(原文)
Recent advancements in reasoning capability of Multimodal Large Language Models (MLLMs) demonstrate its effectiveness in tackling complex visual tasks. However, existing MLLM-based Video Anomaly Detection (VAD) methods remain limited to shallow anomaly descriptions without deep reasoning. In this paper, we propose a new task named Video Anomaly Reasoning (VAR), which aims to enable deep analysis and understanding of anomalies in the video by requiring MLLMs to think explicitly before answering. To this end, we propose Vad-R1, an end-to-end MLLM-based framework for VAR. Specifically, we design a Perception-to-Cognition Chain-of-Thought (P2C-CoT) that simulates the human process of recognizing anomalies, guiding the MLLM to reason anomaly step-by-step. Based on the structured P2C-CoT, we construct Vad-Reasoning, a dedicated dataset for VAR. Furthermore, we propose an improved reinforcement learning algorithm AVA-GRPO, which explicitly incentivizes the anomaly reasoning capability of MLLMs through a self-verification mechanism with limited annotations. Experimental results demonstrate that Vad-R1 achieves superior performance, outperforming both open-source and proprietary models on VAD and VAR tasks. Codes and datasets will be released at https://github.com/wbfwonderful/Vad-R1.