StyleAR: Customizing Multimodal Autoregressive Model for Style-Aligned Text-to-Image Generation
作者: Yi Wu, Lingting Zhu, Shengju Qian, Lei Liu, Wandi Qiao, Lequan Yu, Bin Li
分类: cs.CV, cs.AI, cs.MM
发布日期: 2025-05-26
💡 一句话要点
StyleAR:定制多模态自回归模型,实现风格对齐的文本到图像生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 风格迁移 文本到图像生成 自回归模型 多模态学习 CLIP编码器
📋 核心要点
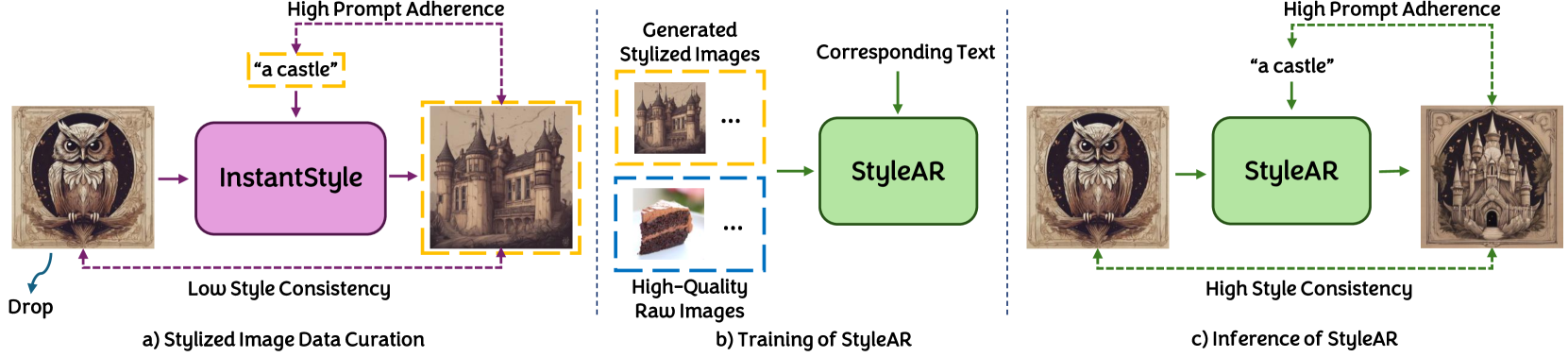
- 风格对齐的文本到图像生成任务面临数据获取难题,难以获得大量风格一致的三元组数据。
- StyleAR利用文本到图像的二元数据,结合数据管理方法和改进的自回归模型,实现风格对齐生成。
- 实验结果表明,StyleAR在风格对齐的文本到图像生成任务上表现优异,能够有效提取风格特征并保持风格一致性。
📝 摘要(中文)
当前,多模态自回归(AR)模型在视觉理解和生成等领域表现出卓越的能力。然而,风格对齐的文本到图像生成等复杂任务,尤其是在数据获取方面,提出了重大挑战。类似于AR模型图像编辑的指令跟随微调,风格对齐生成需要参考风格图像和提示,从而产生文本-图像-图像三元组,其中输出共享输入的风格和语义。然而,获取大量具有特定风格的此类三元组数据,比获取用于训练生成模型的传统文本到图像数据更具挑战性。为了解决这个问题,我们提出了一种创新的方法StyleAR,它结合了专门设计的数据管理方法和我们提出的AR模型,以有效地利用文本到图像的二元数据进行风格对齐的文本到图像生成。我们的方法使用参考风格图像和提示合成目标风格化数据,但仅将目标风格化图像作为图像模态纳入,以创建高质量的二元数据。为了促进二元数据训练,我们引入了一个带有感知器重采样器的CLIP图像编码器,该编码器将图像输入转换为与AR模型中的多模态token对齐的风格token,并实现了一种风格增强token技术,以防止内容泄露,这是先前工作中常见的问题。此外,我们将从大规模文本-图像数据集中提取的原始图像与风格化图像混合,以增强StyleAR提取更丰富的风格特征并确保风格一致性的能力。大量的定性和定量实验证明了我们卓越的性能。
🔬 方法详解
问题定义:论文旨在解决风格对齐的文本到图像生成问题。现有方法难以获取大量风格一致的训练数据,并且容易出现内容泄露,导致生成的图像与参考风格不一致。
核心思路:论文的核心思路是利用现有的文本到图像二元数据,通过特定的数据合成和模型设计,使得模型能够学习到风格信息,并生成风格对齐的图像。关键在于如何将风格信息有效地融入到自回归模型中,并防止内容泄露。
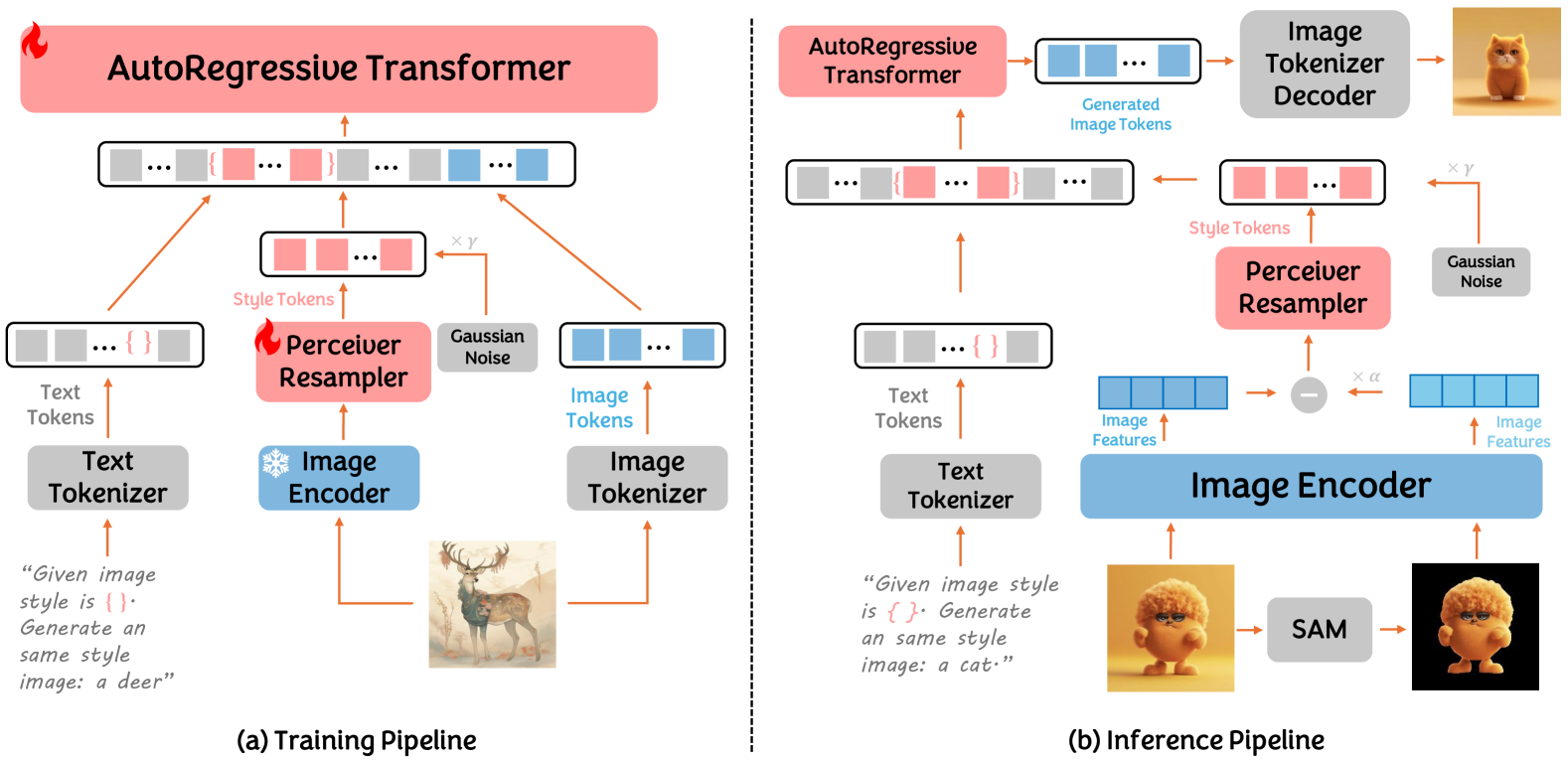
技术框架:StyleAR的整体框架包括以下几个主要模块:1) 数据合成模块:利用参考风格图像和文本提示,合成目标风格化图像,构建二元训练数据。2) CLIP图像编码器:使用CLIP图像编码器提取图像的风格特征,并通过感知器重采样器将图像输入转换为与多模态token对齐的风格token。3) 风格增强token技术:防止内容泄露,确保生成图像的风格一致性。4) 自回归模型:使用改进的自回归模型进行图像生成。
关键创新:论文的关键创新点在于:1) 提出了一种新的数据合成方法,能够有效地利用文本到图像的二元数据进行风格对齐的训练。2) 引入了带有感知器重采样器的CLIP图像编码器,能够将图像输入转换为与多模态token对齐的风格token。3) 提出了一种风格增强token技术,能够有效地防止内容泄露。
关键设计:在数据合成方面,论文采用了特定的策略来保证合成数据的质量。在模型设计方面,论文对自回归模型进行了改进,使其能够更好地处理风格信息。具体的技术细节包括感知器重采样器的参数设置、风格增强token的实现方式等。此外,论文还采用了混合训练策略,将原始图像和风格化图像混合在一起进行训练,以增强模型提取风格特征的能力。
🖼️ 关键图片

📊 实验亮点
论文通过大量的定性和定量实验验证了StyleAR的有效性。实验结果表明,StyleAR在风格对齐的文本到图像生成任务上取得了显著的性能提升,能够生成风格一致且高质量的图像。与现有方法相比,StyleAR在风格相似度和图像质量方面均有明显优势。具体指标数据未知,但结论是优于现有方法。
🎯 应用场景
StyleAR技术可应用于图像编辑、艺术创作、虚拟现实等领域。例如,用户可以通过输入文本描述和参考风格图像,快速生成具有特定风格的图像,从而实现个性化的图像定制。该技术还可以用于生成具有艺术风格的图像,为艺术创作提供新的工具和方法。在虚拟现实领域,StyleAR可以用于生成具有特定风格的虚拟场景,提升用户体验。
📄 摘要(原文)
In the current research landscape, multimodal autoregressive (AR) models have shown exceptional capabilities across various domains, including visual understanding and generation. However, complex tasks such as style-aligned text-to-image generation present significant challenges, particularly in data acquisition. In analogy to instruction-following tuning for image editing of AR models, style-aligned generation requires a reference style image and prompt, resulting in a text-image-to-image triplet where the output shares the style and semantics of the input. However, acquiring large volumes of such triplet data with specific styles is considerably more challenging than obtaining conventional text-to-image data used for training generative models. To address this issue, we propose StyleAR, an innovative approach that combines a specially designed data curation method with our proposed AR models to effectively utilize text-to-image binary data for style-aligned text-to-image generation. Our method synthesizes target stylized data using a reference style image and prompt, but only incorporates the target stylized image as the image modality to create high-quality binary data. To facilitate binary data training, we introduce a CLIP image encoder with a perceiver resampler that translates the image input into style tokens aligned with multimodal tokens in AR models and implement a style-enhanced token technique to prevent content leakage which is a common issue in previous work. Furthermore, we mix raw images drawn from large-scale text-image datasets with stylized images to enhance StyleAR's ability to extract richer stylistic features and ensure style consistency. Extensive qualitative and quantitative experiments demonstrate our superior performance.