SD-OVON: A Semantics-aware Dataset and Benchmark Generation Pipeline for Open-Vocabulary Object Navigation in Dynamic Scenes
作者: Dicong Qiu, Jiadi You, Zeying Gong, Ronghe Qiu, Hui Xiong, Junwei Liang
分类: cs.CV, cs.AI, cs.RO
发布日期: 2025-05-24
备注: Preprint. 21 pages
💡 一句话要点
SD-OVON:动态场景下开放词汇目标导航的语义感知数据集与基准生成方案
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 开放词汇目标导航 动态场景 数据集生成 机器人导航 多模态学习 Habitat模拟器 语义感知
📋 核心要点
- 现有目标导航数据集主要局限于静态环境,缺乏动态性和可操作性,限制了智能体在复杂真实场景中的应用。
- SD-OVON利用预训练多模态模型生成逼真且语义合理的动态场景,并提供可操作对象,增强了导航任务的真实性。
- 论文构建了SD-OVON-3k和SD-OVON-10k数据集,并提出了两个基线模型,实验证明了数据集和基准的有效性。
📝 摘要(中文)
本文提出了动态场景下开放词汇目标导航的语义感知数据集与基准生成流程(SD-OVON)。该流程利用预训练多模态基础模型生成无限的、独特的、照片级真实感的场景变体,这些变体符合真实世界的语义和日常常识,用于导航智能体的训练和评估。同时,提供了一个插件,用于生成与Habitat模拟器兼容的目标导航任务片段。此外,我们提供了两个预生成的目标导航任务数据集,SD-OVON-3k和SD-OVON-10k,分别包含约3k和10k个开放词汇目标导航任务片段,这些片段源自SD-OVON-Scenes数据集(包含2.5k个真实世界环境的照片级真实感扫描)和SD-OVON-Objects数据集(包含0.9k个手动检查的扫描和艺术家创建的可操作对象模型)。与之前仅限于静态环境的数据集不同,SD-OVON涵盖了动态场景和可操作对象,从而促进了从真实到模拟以及从模拟到真实的机器人应用。这种方法增强了导航任务的真实性,以及在复杂环境中训练和评估开放词汇目标导航智能体的能力。为了证明我们的流程和数据集的有效性,我们提出了两个基线,并与最先进的基线在SD-OVON-3k上进行了评估。数据集、基准和源代码均已公开。
🔬 方法详解
问题定义:现有开放词汇目标导航数据集主要集中在静态环境中,缺乏动态性和交互性,难以满足真实世界机器人应用的需求。现有方法难以在复杂、动态的环境中进行有效的训练和评估,泛化能力受限。
核心思路:利用预训练多模态基础模型生成具有真实世界语义和日常常识的动态场景,并引入可操作对象,从而构建更逼真、更具挑战性的目标导航任务。这种方法旨在弥合模拟环境与真实环境之间的差距,提高导航智能体的泛化能力。
技术框架:SD-OVON包含三个主要组成部分:SD-OVON-Scenes(包含真实世界环境的扫描)、SD-OVON-Objects(包含可操作对象模型)以及一个用于生成目标导航任务片段的插件。该插件与Habitat模拟器兼容,能够根据用户指定的开放词汇目标,在动态场景中生成导航任务。整体流程包括场景生成、对象放置、任务定义和数据生成等步骤。
关键创新:SD-OVON的关键创新在于其能够生成动态场景和可操作对象,这与以往的静态数据集形成了鲜明对比。此外,利用预训练多模态模型保证了生成场景的语义合理性和真实感,从而提高了数据集的质量。
关键设计:SD-OVON-Scenes数据集包含2.5k个真实世界环境的扫描,SD-OVON-Objects数据集包含0.9k个手动检查的扫描和艺术家创建的可操作对象模型。任务生成插件允许用户自定义目标对象和导航参数。论文还提出了两个基线模型,用于在SD-OVON数据集上进行实验评估。
🖼️ 关键图片


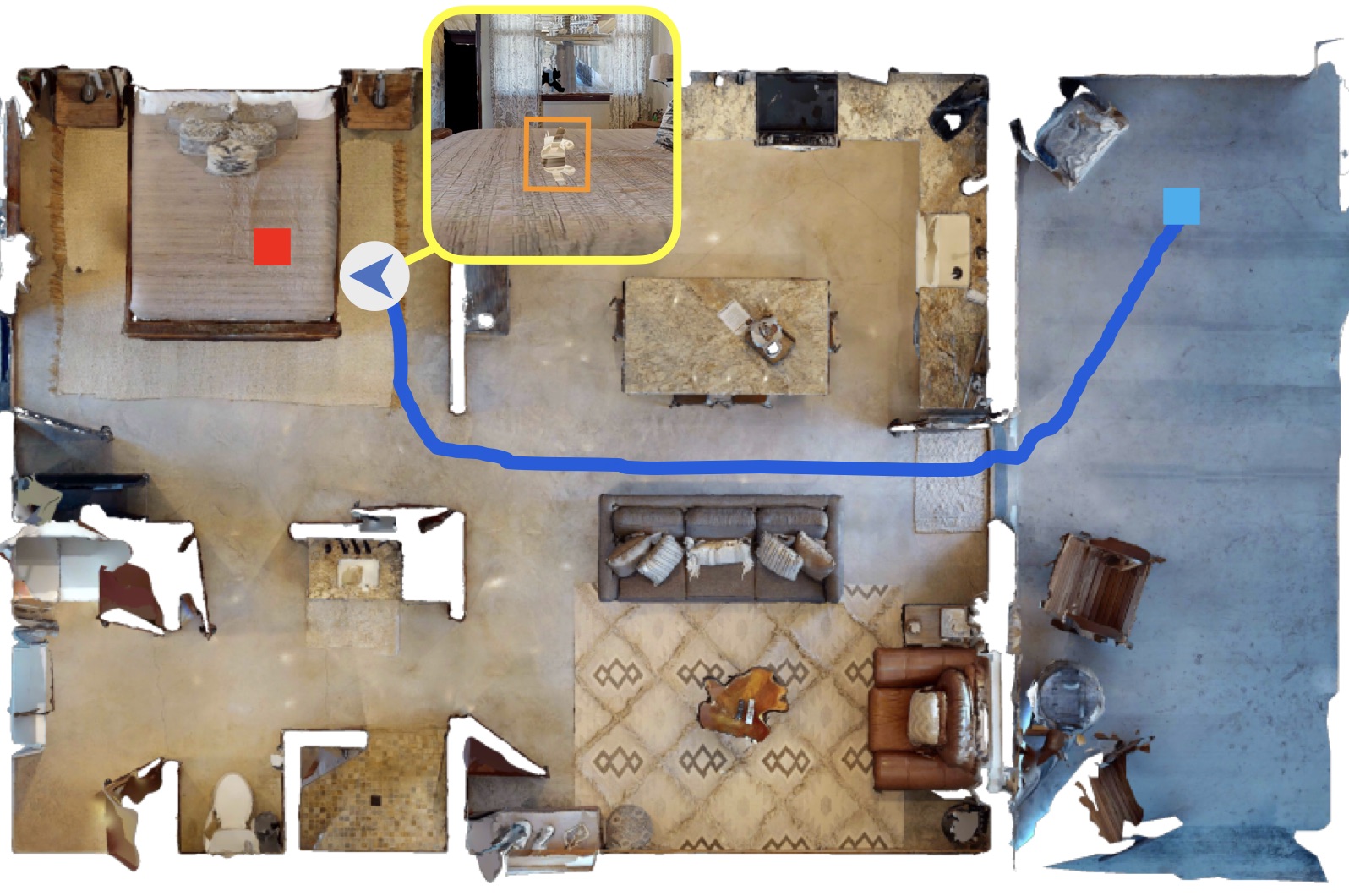
📊 实验亮点
论文在SD-OVON-3k数据集上评估了两个提出的基线模型以及最先进的基线模型。实验结果表明,SD-OVON数据集能够有效评估导航智能体在动态环境中的性能。虽然具体性能数据未在摘要中给出,但强调了该数据集能够区分不同算法的优劣,并为未来的研究提供了一个有价值的基准。
🎯 应用场景
SD-OVON数据集和基准生成流程可广泛应用于机器人导航、家庭服务机器人、自动驾驶等领域。通过在更真实、更复杂的动态环境中训练和评估导航智能体,可以提高其在实际应用中的性能和鲁棒性。该研究为开发更智能、更可靠的机器人系统奠定了基础,并有望推动机器人技术在日常生活中的普及。
📄 摘要(原文)
We present the Semantics-aware Dataset and Benchmark Generation Pipeline for Open-vocabulary Object Navigation in Dynamic Scenes (SD-OVON). It utilizes pretraining multimodal foundation models to generate infinite unique photo-realistic scene variants that adhere to real-world semantics and daily commonsense for the training and the evaluation of navigation agents, accompanied with a plugin for generating object navigation task episodes compatible to the Habitat simulator. In addition, we offer two pre-generated object navigation task datasets, SD-OVON-3k and SD-OVON-10k, comprising respectively about 3k and 10k episodes of the open-vocabulary object navigation task, derived from the SD-OVON-Scenes dataset with 2.5k photo-realistic scans of real-world environments and the SD-OVON-Objects dataset with 0.9k manually inspected scanned and artist-created manipulatable object models. Unlike prior datasets limited to static environments, SD-OVON covers dynamic scenes and manipulatable objects, facilitating both real-to-sim and sim-to-real robotic applications. This approach enhances the realism of navigation tasks, the training and the evaluation of open-vocabulary object navigation agents in complex settings. To demonstrate the effectiveness of our pipeline and datasets, we propose two baselines and evaluate them along with state-of-the-art baselines on SD-OVON-3k. The datasets, benchmark and source code are publicly available.