How Much Do Large Language Models Know about Human Motion? A Case Study in 3D Avatar Control
作者: Kunhang Li, Jason Naradowsky, Yansong Feng, Yusuke Miyao
分类: cs.CV, cs.AI, cs.CL, cs.RO
发布日期: 2025-05-23 (更新: 2025-09-20)
💡 一句话要点
利用大型语言模型进行3D虚拟人物控制:探索其在人体运动理解方面的能力
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 3D虚拟人物控制 人体运动理解 运动规划 动画生成
📋 核心要点
- 现有方法在利用LLM进行3D虚拟人物控制时,难以保证运动的精确性和连贯性。
- 论文提出一种两阶段规划方法,首先生成高级运动计划,再细化到低级的身体部位位置,从而控制3D虚拟人物。
- 实验表明,LLM擅长高级运动规划,但在精确控制身体部位位置方面仍有提升空间,尤其是在复杂运动中。
📝 摘要(中文)
本文通过3D虚拟人物控制,探索大型语言模型(LLM)在人体运动知识方面的能力。给定运动指令,我们提示LLM首先生成包含连续步骤的高级运动计划(高级规划),然后指定每个步骤中身体部位的位置(低级规划),我们将其线性插值到虚拟人物动画中。我们使用20个代表性的运动指令,涵盖基本运动和身体部位的平衡使用,进行了全面的评估,包括对高级运动计划和生成的动画进行人工和自动评分,以及与低级规划中的oracle位置进行自动比较。我们的研究结果表明,LLM擅长解释高级身体运动,但在精确的身体部位定位方面存在困难。虽然将运动查询分解为原子组件可以改善规划,但LLM在涉及高度自由度身体部位的多步运动中面临挑战。此外,LLM为一般空间描述提供了合理的近似,但在处理精确的空间规范方面有所欠缺。值得注意的是,LLM在概念化创造性运动和区分文化特定的运动模式方面表现出潜力。
🔬 方法详解
问题定义:现有方法在利用大型语言模型(LLM)进行3D虚拟人物控制时,面临着运动精度和连贯性的挑战。LLM虽然具备强大的语言理解能力,但直接生成精确的身体部位位置信息较为困难,尤其是在多步运动和涉及高自由度身体部位时。此外,现有方法难以有效处理精确的空间规范,导致生成的动画可能不符合预期。
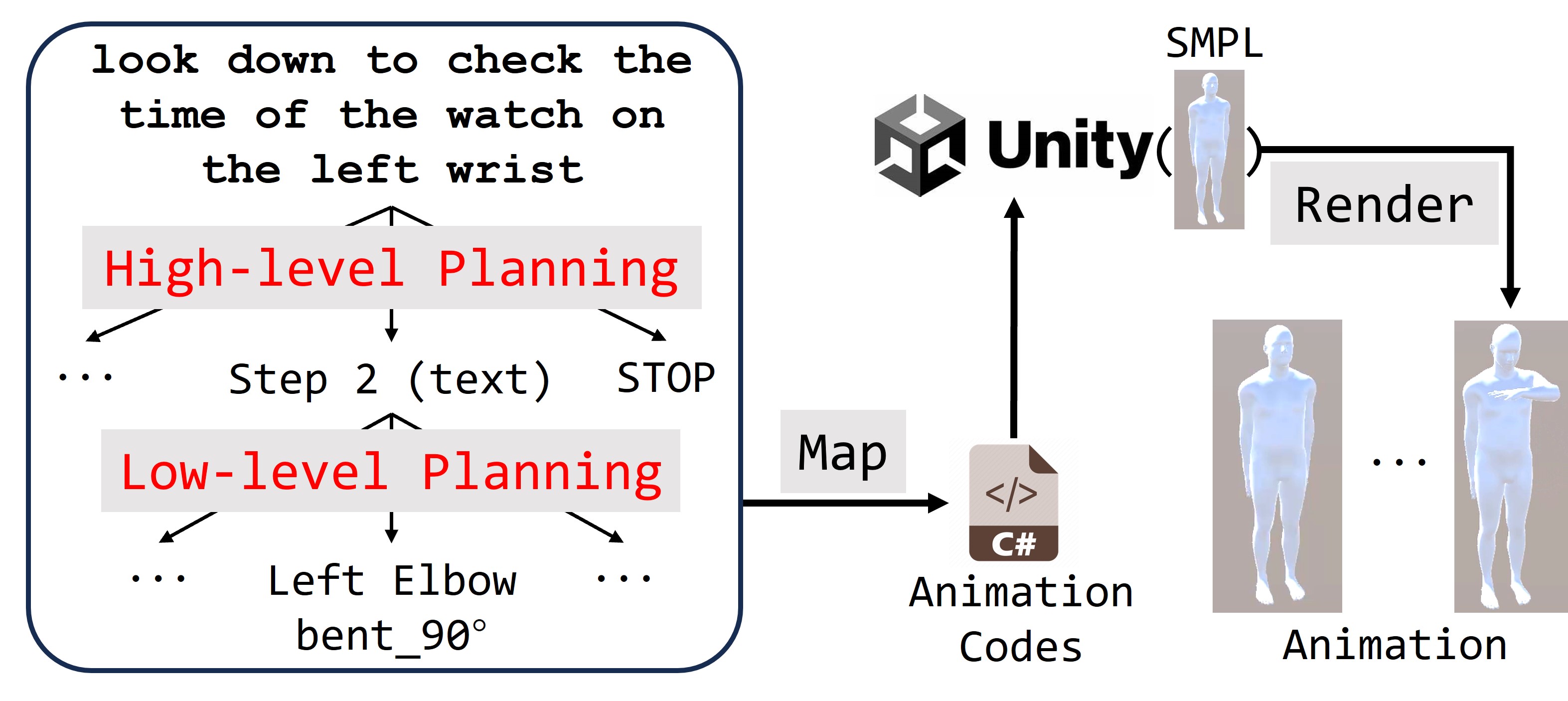
核心思路:论文的核心思路是将运动控制任务分解为两个阶段:高级规划和低级规划。高级规划负责生成包含连续步骤的运动计划,描述整体的运动意图;低级规划则负责在每个步骤中指定身体部位的具体位置。通过分而治之,降低了LLM直接生成复杂运动序列的难度,使其能够更好地利用自身的语言理解能力。
技术框架:整体框架包含以下几个主要模块:1) 运动指令输入:接收用户输入的自然语言运动指令。2) 高级规划:利用LLM生成包含连续步骤的运动计划,每个步骤描述一个相对独立的运动状态。3) 低级规划:针对高级规划中的每个步骤,利用LLM指定身体各个部位的具体位置。4) 动画生成:将低级规划生成的身体部位位置信息进行线性插值,生成最终的3D虚拟人物动画。5) 评估:通过人工和自动评分,评估高级运动计划和生成动画的质量。
关键创新:论文的关键创新在于将运动控制任务分解为高级和低级两个规划阶段,并利用LLM分别处理这两个阶段的任务。这种分解方式能够更好地利用LLM的语言理解能力,同时降低了生成精确运动序列的难度。此外,论文还提出了针对高级运动计划和生成动画的综合评估方法,为后续研究提供了参考。
关键设计:在高级规划阶段,论文采用提示工程(Prompt Engineering)的方式引导LLM生成运动计划。在低级规划阶段,论文使用线性插值方法将LLM生成的身体部位位置信息转换为连续的动画序列。此外,论文还设计了一系列评估指标,包括人工评分(评估运动的自然性和符合程度)和自动评分(评估与oracle位置的偏差)。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LLM在高级运动规划方面表现出色,能够理解并生成合理的运动计划。然而,在精确控制身体部位位置方面仍有提升空间,尤其是在涉及高自由度身体部位的多步运动中。与oracle位置相比,LLM生成的身体部位位置存在一定的偏差。尽管如此,LLM在概念化创造性运动和区分文化特定的运动模式方面展现出潜力。
🎯 应用场景
该研究成果可应用于虚拟现实、游戏开发、动画制作等领域。通过结合大型语言模型的语言理解能力和3D动画技术,可以实现更加自然、智能和个性化的虚拟人物控制,提升用户体验。未来,该技术有望应用于人机交互、远程协作、康复训练等更广泛的领域。
📄 摘要(原文)
We explore the human motion knowledge of Large Language Models (LLMs) through 3D avatar control. Given a motion instruction, we prompt LLMs to first generate a high-level movement plan with consecutive steps (High-level Planning), then specify body part positions in each step (Low-level Planning), which we linearly interpolate into avatar animations. Using 20 representative motion instructions that cover fundamental movements and balance body part usage, we conduct comprehensive evaluations, including human and automatic scoring of both high-level movement plans and generated animations, as well as automatic comparison with oracle positions in low-level planning. Our findings show that LLMs are strong at interpreting high-level body movements but struggle with precise body part positioning. While decomposing motion queries into atomic components improves planning, LLMs face challenges in multi-step movements involving high-degree-of-freedom body parts. Furthermore, LLMs provide reasonable approximations for general spatial descriptions, but fall short in handling precise spatial specifications. Notably, LLMs demonstrate promise in conceptualizing creative motions and distinguishing culturally specific motion patterns.