CoMo: Learning Continuous Latent Motion from Internet Videos for Scalable Robot Learning
作者: Jiange Yang, Yansong Shi, Haoyi Zhu, Mingyu Liu, Kaijing Ma, Yating Wang, Gangshan Wu, Tong He, Limin Wang
分类: cs.CV, cs.RO
发布日期: 2025-05-22
备注: 18 pages, 7 figures
💡 一句话要点
CoMo:从互联网视频学习连续潜在运动,用于可扩展的机器人学习
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting)
关键词: 机器人学习 连续潜在运动 互联网视频 信息瓶颈 零样本泛化
📋 核心要点
- 现有离散潜在动作方法存在信息丢失问题,难以处理复杂和精细的动态。
- CoMo通过早期时间特征差分和信息瓶颈约束,学习连续潜在运动表示,抑制噪声并保留动作信息。
- 实验表明,CoMo具有强大的零样本泛化能力,可生成伪动作,提升机器人策略学习性能。
📝 摘要(中文)
本文提出CoMo,旨在从多样化的互联网规模视频中学习更具信息量的连续运动表示,以构建通用机器人。CoMo采用早期时间特征差分机制,防止模型崩溃并抑制静态外观噪声,有效避免了捷径学习问题。此外,在信息瓶颈原则的指导下,CoMo约束潜在运动嵌入的维度,以在保留足够的动作相关信息和最小化动作无关的外观噪声之间取得更好的平衡。同时,引入两个新指标,用于更稳健和经济地评估运动并指导运动学习方法的发展:(i)动作预测的线性探测MSE,以及(ii)过去到当前和未来到当前运动嵌入之间的余弦相似度。CoMo表现出强大的零样本泛化能力,能够为先前未见过的视频领域生成连续的伪动作。这种能力促进了统一的策略联合学习,使用来自各种无动作视频数据集(例如,跨具身视频,特别是人类演示视频)的伪动作,并可能辅以有限的标记机器人数据。大量实验表明,在模拟和真实环境中,使用CoMo伪动作共同训练的策略在使用扩散和自回归架构时均能获得卓越的性能。
🔬 方法详解
问题定义:现有基于离散潜在动作的方法在从互联网视频中学习运动表示时,存在信息损失的问题,并且难以捕捉复杂和精细的动作动态。此外,模型容易受到静态外观噪声的干扰,导致捷径学习,即模型学习到与动作无关的特征。
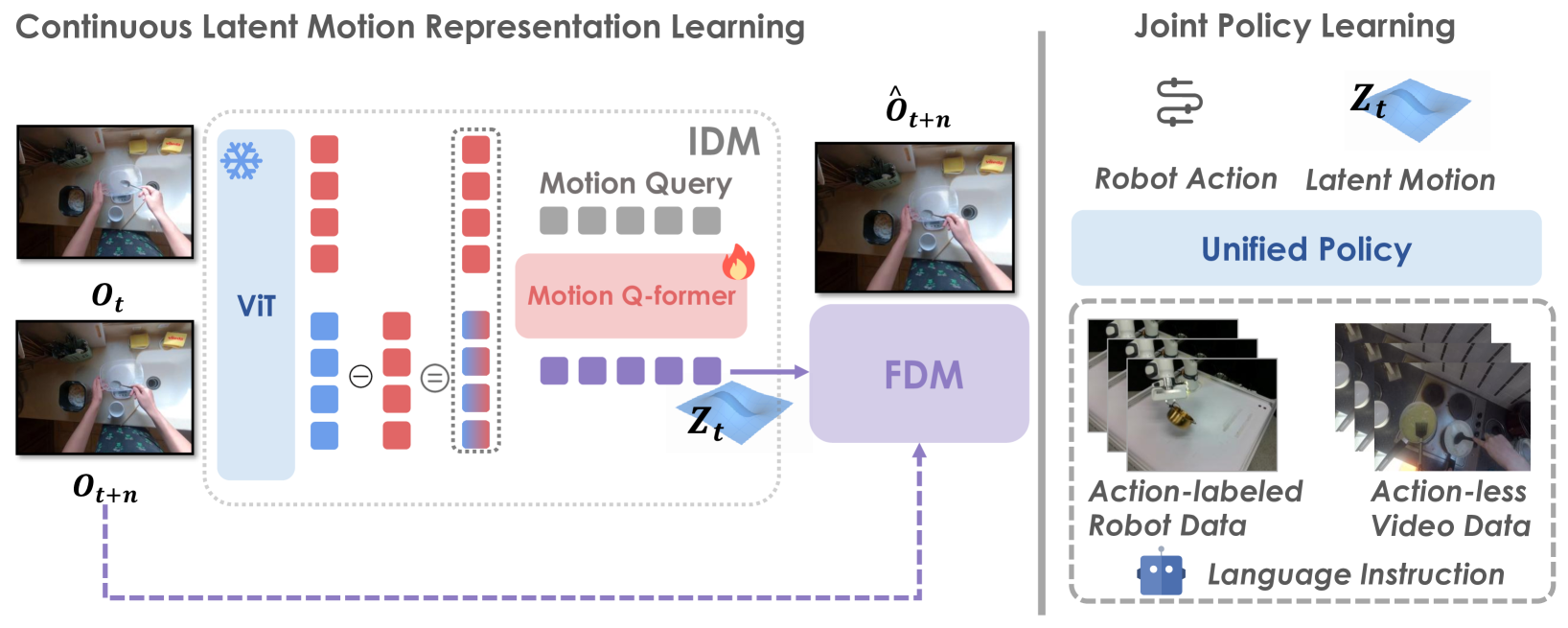
核心思路:CoMo的核心思路是从互联网视频中学习连续的潜在运动表示,并通过早期时间特征差分来抑制静态外观噪声,防止模型崩溃。同时,利用信息瓶颈原则来约束潜在运动嵌入的维度,从而在保留动作相关信息和去除动作无关噪声之间取得平衡。
技术框架:CoMo的整体框架包括以下几个主要模块:1) 视频编码器,用于提取视频帧的特征;2) 时间特征差分模块,用于计算相邻帧之间的特征差异,以突出运动信息;3) 潜在运动编码器,将时间特征差分编码为连续的潜在运动表示;4) 信息瓶颈约束,通过限制潜在运动嵌入的维度来减少噪声;5) 策略学习模块,利用学习到的潜在运动表示来训练机器人策略。
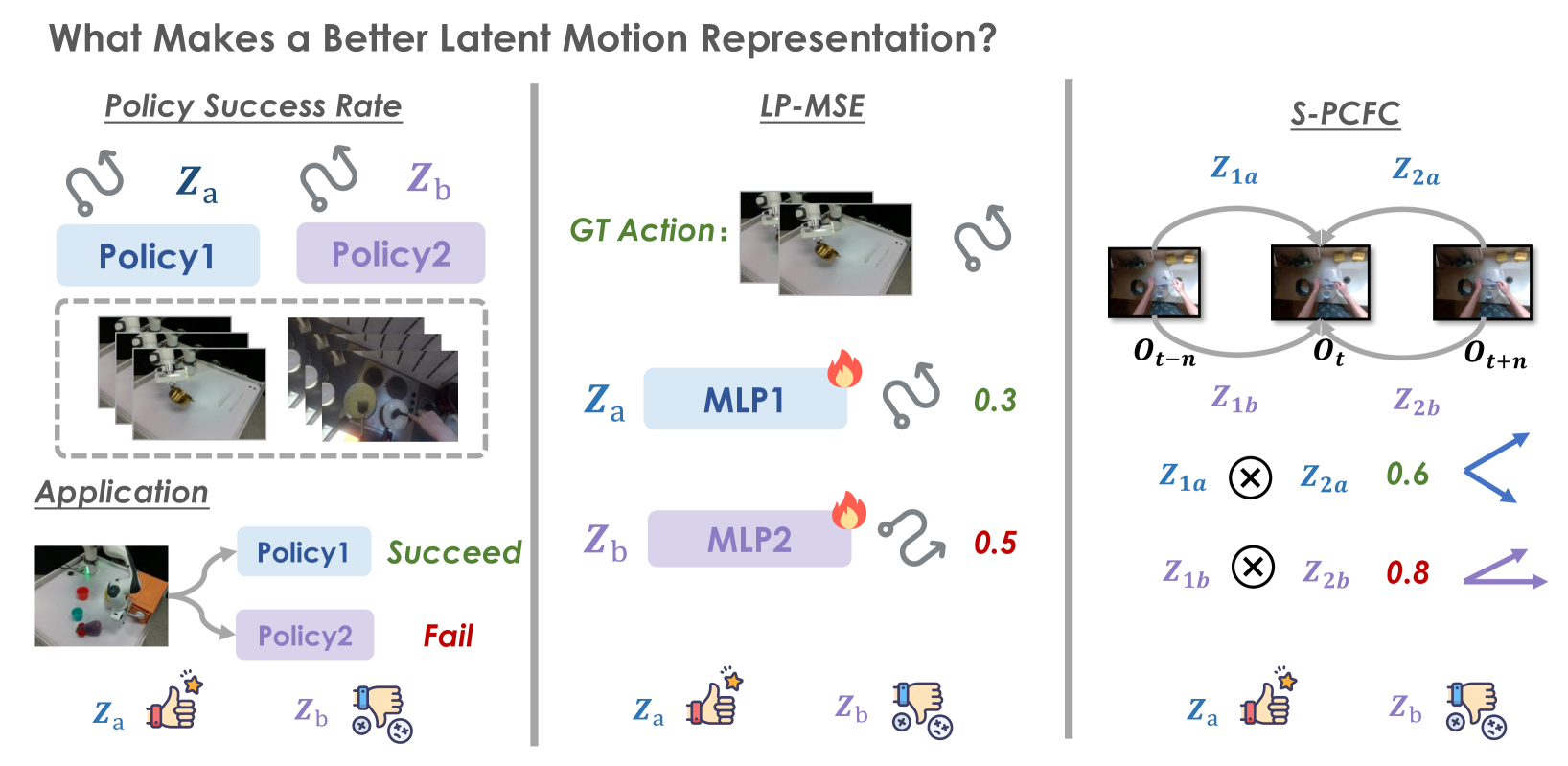
关键创新:CoMo的关键创新在于:1) 提出了早期时间特征差分机制,有效抑制了静态外观噪声,避免了捷径学习;2) 利用信息瓶颈原则来约束潜在运动嵌入的维度,从而在保留动作相关信息和去除动作无关噪声之间取得了更好的平衡;3) 提出了两个新的评估指标,用于更稳健和经济地评估运动学习方法。
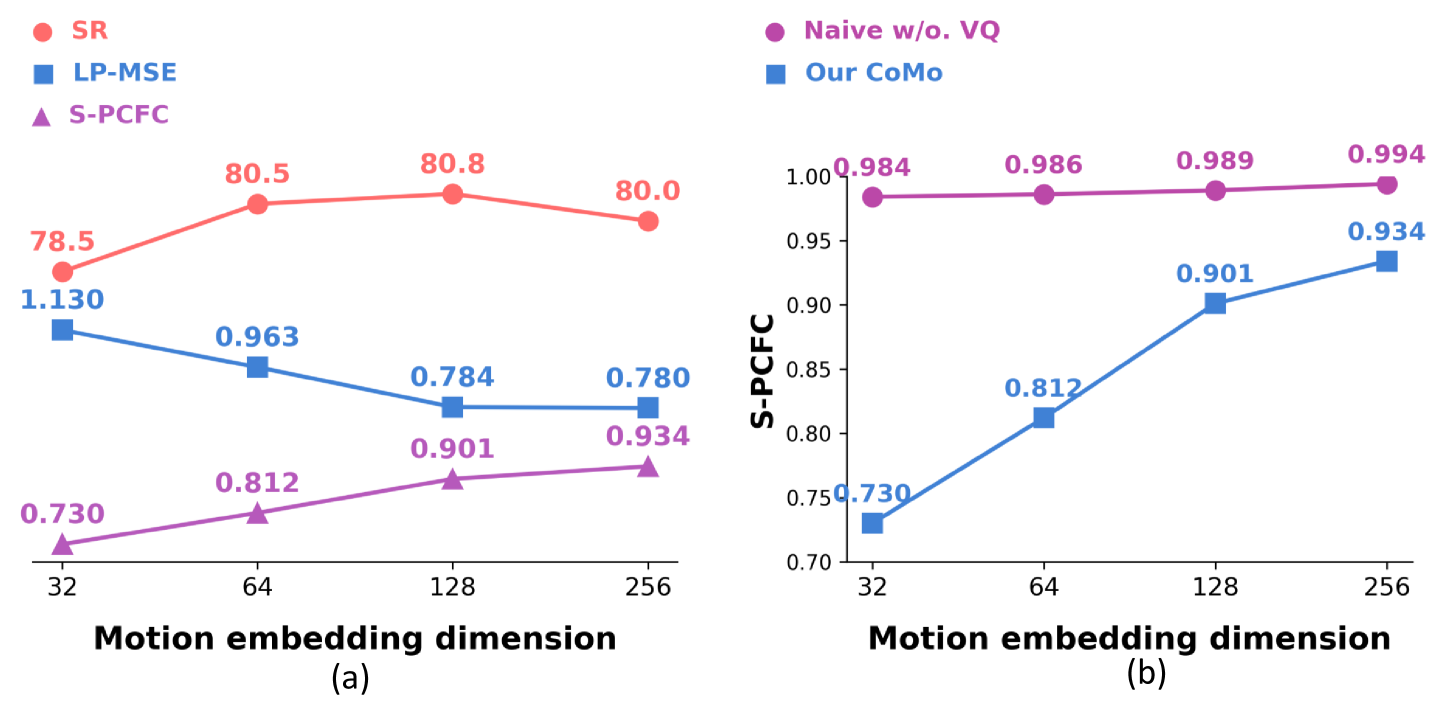
关键设计:CoMo的关键设计包括:1) 早期时间特征差分的实现方式,例如使用相邻帧特征的差值或比值;2) 信息瓶颈约束的具体实现,例如使用变分自编码器(VAE)或对抗训练;3) 潜在运动嵌入的维度选择,需要在保留足够动作信息和减少噪声之间进行权衡;4) 损失函数的设计,例如使用重构损失、KL散度损失等。
🖼️ 关键图片
📊 实验亮点
CoMo在模拟和真实环境中都取得了显著的性能提升。例如,在策略学习任务中,使用CoMo伪动作共同训练的策略在使用扩散和自回归架构时均优于基线方法。CoMo还表现出强大的零样本泛化能力,能够为先前未见过的视频领域生成连续的伪动作,这表明CoMo学习到的运动表示具有很强的泛化能力。
🎯 应用场景
CoMo具有广泛的应用前景,例如:1) 通过学习人类演示视频中的运动表示,可以帮助机器人模仿人类动作;2) 通过学习跨具身视频中的运动表示,可以实现不同机器人之间的知识迁移;3) 可以用于训练通用机器人策略,使其能够适应不同的任务和环境。CoMo的实际价值在于降低了机器人学习的成本,提高了机器人学习的效率,并促进了通用机器人的发展。
📄 摘要(原文)
Learning latent motion from Internet videos is crucial for building generalist robots. However, existing discrete latent action methods suffer from information loss and struggle with complex and fine-grained dynamics. We propose CoMo, which aims to learn more informative continuous motion representations from diverse, internet-scale videos. CoMo employs a early temporal feature difference mechanism to prevent model collapse and suppress static appearance noise, effectively discouraging shortcut learning problem. Furthermore, guided by the information bottleneck principle, we constrain the latent motion embedding dimensionality to achieve a better balance between retaining sufficient action-relevant information and minimizing the inclusion of action-irrelevant appearance noise. Additionally, we also introduce two new metrics for more robustly and affordably evaluating motion and guiding motion learning methods development: (i) the linear probing MSE of action prediction, and (ii) the cosine similarity between past-to-current and future-to-current motion embeddings. Critically, CoMo exhibits strong zero-shot generalization, enabling it to generate continuous pseudo actions for previously unseen video domains. This capability facilitates unified policy joint learning using pseudo actions derived from various action-less video datasets (such as cross-embodiment videos and, notably, human demonstration videos), potentially augmented with limited labeled robot data. Extensive experiments show that policies co-trained with CoMo pseudo actions achieve superior performance with both diffusion and autoregressive architectures in simulated and real-world settings.