Pixels Versus Priors: Controlling Knowledge Priors in Vision-Language Models through Visual Counterfacts
作者: Michal Golovanevsky, William Rudman, Michael Lepori, Amir Bar, Ritambhara Singh, Carsten Eickhoff
分类: cs.CV, cs.LG
发布日期: 2025-05-21 (更新: 2025-09-29)
💡 一句话要点
提出Pixels Versus Priors方法,通过视觉反事实控制视觉-语言模型中的知识先验。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 知识先验 视觉反事实 模型可控性 激活向量干预
📋 核心要点
- 现有的多模态大语言模型在视觉问答等任务中,推理过程对世界知识的依赖程度难以确定,存在过度依赖先验知识的风险。
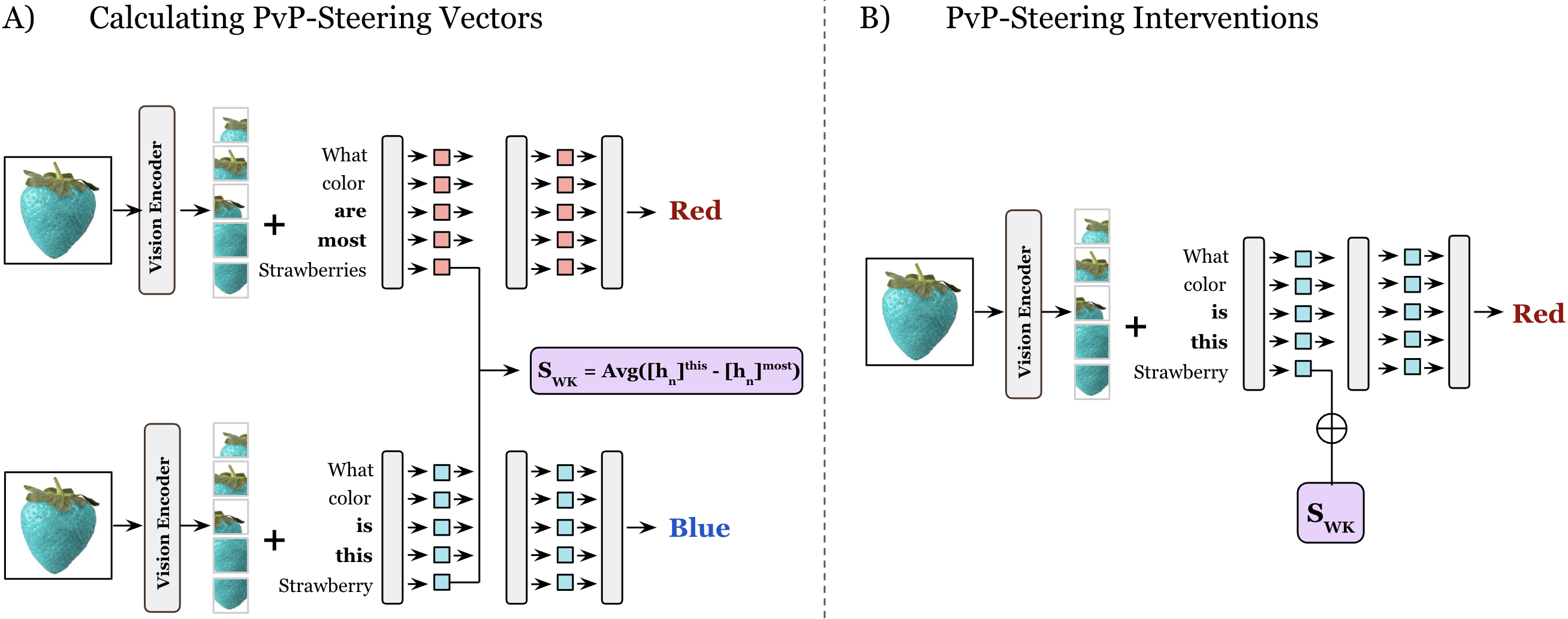
- 论文提出Pixels Versus Priors (PvP)方法,通过激活向量干预,控制模型输出偏向世界知识或视觉输入,实现对模型行为的精确控制。
- 实验表明,PvP方法能够有效地将颜色和大小的预测从先验知识转移到视觉反事实,颜色预测的转移成功率高达99.3%。
📝 摘要(中文)
多模态大型语言模型(MLLM)在视觉问答等任务中表现出色,但其推理更多地依赖于记忆的世界知识还是输入图像中的视觉信息尚不清楚。为了研究这一点,我们引入了Visual CounterFact,这是一个新的视觉上逼真的反事实数据集,它将世界知识先验(例如,红色草莓)与视觉输入(例如,蓝色草莓)直接冲突。使用Visual CounterFact,我们表明模型预测最初反映了记忆的先验,但在中后期层转向视觉证据。这种动态揭示了两种模态之间的竞争,视觉输入最终在评估期间覆盖先验。为了控制这种行为,我们提出了Pixels Versus Priors (PvP) steering vectors,这是一种通过激活级别干预将模型输出控制为世界知识或视觉输入的机制。平均而言,PvP成功地将99.3%的颜色和80.8%的大小预测从先验转移到反事实。总之,这些发现为解释和控制多模态模型中的事实行为提供了新的工具。
🔬 方法详解
问题定义:现有的多模态大语言模型在处理视觉信息时,难以区分模型预测是基于视觉输入还是记忆中的先验知识。模型可能过度依赖先验知识,导致在视觉信息与先验知识冲突时做出错误的判断。因此,如何控制模型对视觉信息和先验知识的依赖程度是一个关键问题。
核心思路:论文的核心思路是通过干预模型的中间层激活向量,来控制模型对视觉信息和先验知识的依赖程度。具体来说,通过学习steering vectors,可以引导模型的输出偏向视觉输入或先验知识,从而实现对模型行为的精确控制。这种方法允许在不重新训练模型的情况下,动态调整模型对不同模态信息的关注度。
技术框架:该方法主要包含以下几个阶段:1) 构建Visual CounterFact数据集,该数据集包含视觉上逼真的反事实图像,用于评估模型对视觉信息和先验知识的依赖程度。2) 分析模型在不同层对视觉信息和先验知识的响应,确定干预的最佳位置。3) 学习Pixels Versus Priors (PvP) steering vectors,这些向量用于干预模型的激活向量,引导模型输出偏向视觉输入或先验知识。4) 通过实验评估PvP方法在控制模型行为方面的有效性。
关键创新:该方法最重要的创新点在于提出了Pixels Versus Priors (PvP) steering vectors,这是一种通过激活级别干预来控制模型输出的新机制。与传统的微调方法不同,PvP方法不需要重新训练模型,而是通过对中间层激活向量进行微小的调整,即可实现对模型行为的精确控制。这种方法具有更高的效率和灵活性。
关键设计:PvP steering vectors 的学习过程涉及到优化一个目标函数,该目标函数旨在最大化模型输出与目标输出之间的相似度,同时最小化steering vectors的幅度。具体的参数设置包括学习率、优化器类型、损失函数权重等。此外,选择合适的干预层也是一个关键的设计决策,需要根据模型的结构和任务特点进行调整。论文中使用了Visual CounterFact数据集来评估PvP方法的有效性,该数据集包含颜色和大小两种类型的反事实图像。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Pixels Versus Priors (PvP)方法能够有效地控制模型对视觉信息和先验知识的依赖程度。在Visual CounterFact数据集上,PvP方法成功地将99.3%的颜色预测和80.8%的大小预测从先验知识转移到视觉反事实。这些结果表明,PvP方法是一种有效的控制多模态模型行为的工具。
🎯 应用场景
该研究成果可应用于提升多模态大语言模型的可解释性和可控性,例如在医疗诊断、自动驾驶等安全攸关领域,可以确保模型在复杂场景下做出可靠的决策。此外,该方法还可以用于个性化定制模型行为,使其更好地适应特定用户的需求。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) perform well on tasks such as visual question answering, but it remains unclear whether their reasoning relies more on memorized world knowledge or on the visual information present in the input image. To investigate this, we introduce Visual CounterFact, a new dataset of visually-realistic counterfactuals that put world knowledge priors (e.g, red strawberry) into direct conflict with visual input (e.g, blue strawberry). Using Visual CounterFact, we show that model predictions initially reflect memorized priors, but shift toward visual evidence in mid-to-late layers. This dynamic reveals a competition between the two modalities, with visual input ultimately overriding priors during evaluation. To control this behavior, we propose Pixels Versus Priors (PvP) steering vectors, a mechanism for controlling model outputs toward either world knowledge or visual input through activation-level interventions. On average, PvP successfully shifts 99.3% of color and 80.8% of size predictions from priors to counterfactuals. Together, these findings offer new tools for interpreting and controlling factual behavior in multimodal models.