Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
作者: Haozhe Wang, Alex Su, Weiming Ren, Fangzhen Lin, Wenhu Chen
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-05-21 (更新: 2025-10-24)
备注: Project Page: https://tiger-ai-lab.github.io/Pixel-Reasoner/, Hands-on Demo: https://huggingface.co/spaces/TIGER-Lab/Pixel-Reasoner
💡 一句话要点
提出Pixel Reasoner,通过好奇心驱动的强化学习,激励视觉语言模型进行像素空间推理。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 像素空间推理 视觉语言模型 强化学习 好奇心驱动 视觉推理
📋 核心要点
- 现有大型语言模型(LLM)的推理过程仅限于文本空间,限制了其在视觉密集型任务中的有效性。
- Pixel Reasoner通过引入像素空间推理,使VLM能够直接从视觉证据中进行检查、询问和推断,增强视觉任务的推理能力。
- 该方法通过指令调优和好奇心驱动的强化学习,解决了模型能力不平衡和不愿采用像素空间操作的问题,并在多个视觉推理基准上取得了显著提升。
📝 摘要(中文)
本文提出了一种在像素空间进行推理的新框架,旨在提升视觉语言模型(VLM)在视觉密集型任务中的性能。该框架赋予VLM一系列视觉推理操作,如放大和选择帧,使其能够直接检查、询问和推断视觉证据。为了解决模型初始能力不平衡以及不愿采用像素空间操作的问题,本文采用两阶段训练方法。第一阶段,通过在合成的推理轨迹上进行指令调优,使模型熟悉新的视觉操作。第二阶段,利用好奇心驱动的奖励机制的强化学习,平衡像素空间推理和文本推理之间的探索。实验结果表明,该方法显著提高了VLM在各种视觉推理基准上的性能。提出的7B模型在V* bench上达到84%,在TallyQA-Complex上达到74%,在InfographicsVQA上达到84%,是迄今为止任何开源模型所取得的最高精度。这些结果突出了像素空间推理的重要性以及本文框架的有效性。
🔬 方法详解
问题定义:现有视觉语言模型(VLM)在处理视觉密集型任务时,推理过程主要依赖于文本空间,无法充分利用图像或视频中的像素信息进行推理。这导致VLM在需要细粒度视觉理解的任务中表现受限,例如需要放大图像局部区域或分析视频帧序列的任务。现有方法缺乏有效的机制来引导VLM主动探索和利用像素空间进行推理。
核心思路:本文的核心思路是赋予VLM在像素空间进行推理的能力,使其能够像人类一样,通过视觉操作(如放大、选择帧等)来主动探索和理解视觉信息。通过引入这些操作,VLM可以更直接地从视觉证据中进行推断,从而提高视觉推理的准确性和可靠性。为了鼓励VLM使用这些新的视觉操作,本文设计了一种好奇心驱动的强化学习框架。
技术框架:Pixel Reasoner的整体框架包含两个主要阶段:指令调优阶段和强化学习阶段。在指令调优阶段,使用合成的推理轨迹来训练VLM,使其熟悉新的视觉操作。这些轨迹模拟了人类在解决视觉推理问题时的思考过程,包括文本推理和像素空间推理。在强化学习阶段,使用好奇心驱动的奖励机制来训练VLM,鼓励其探索不同的推理路径,并平衡像素空间推理和文本推理之间的探索。VLM作为智能体,通过执行动作(包括文本操作和视觉操作)与环境交互,并根据环境的反馈获得奖励。
关键创新:本文最重要的技术创新点在于引入了像素空间推理的概念,并设计了一种好奇心驱动的强化学习框架来训练VLM。与现有方法相比,Pixel Reasoner能够让VLM主动探索和利用像素信息进行推理,从而提高视觉推理的准确性和可靠性。此外,好奇心驱动的奖励机制能够有效地平衡像素空间推理和文本推理之间的探索,避免模型过度依赖文本信息。
关键设计:在指令调优阶段,使用了大量的合成数据,包括不同类型的视觉推理问题和对应的推理轨迹。在强化学习阶段,好奇心驱动的奖励函数的设计至关重要。该奖励函数鼓励VLM探索未知的状态和动作,并惩罚重复的探索行为。具体来说,可以使用基于信息增益或预测误差的奖励函数来衡量VLM的好奇心。此外,还需要仔细调整强化学习算法的参数,例如学习率、折扣因子和探索率,以获得最佳的训练效果。
🖼️ 关键图片
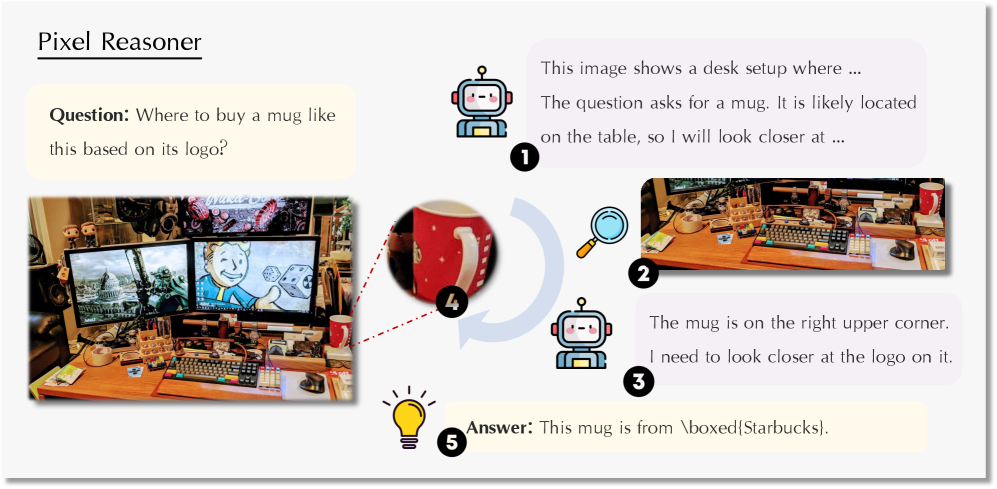


📊 实验亮点
Pixel Reasoner在多个视觉推理基准上取得了显著的性能提升。具体来说,在V* bench上达到了84%的准确率,在TallyQA-Complex上达到了74%的准确率,在InfographicsVQA上达到了84%的准确率。这些结果表明,Pixel Reasoner能够有效地提高VLM在视觉密集型任务中的性能,并且优于现有的开源模型。
🎯 应用场景
Pixel Reasoner具有广泛的应用前景,例如可以应用于智能监控、自动驾驶、医学图像分析、机器人导航等领域。通过赋予机器视觉系统更强的推理能力,可以提高其在复杂环境中的适应性和鲁棒性。此外,该研究还可以促进视觉语言模型的发展,使其能够更好地理解和利用视觉信息。
📄 摘要(原文)
Chain-of-thought reasoning has significantly improved the performance of Large Language Models (LLMs) across various domains. However, this reasoning process has been confined exclusively to textual space, limiting its effectiveness in visually intensive tasks. To address this limitation, we introduce the concept of reasoning in the pixel-space. Within this novel framework, Vision-Language Models (VLMs) are equipped with a suite of visual reasoning operations, such as zoom-in and select-frame. These operations enable VLMs to directly inspect, interrogate, and infer from visual evidences, thereby enhancing reasoning fidelity for visual tasks. Cultivating such pixel-space reasoning capabilities in VLMs presents notable challenges, including the model's initially imbalanced competence and its reluctance to adopt the newly introduced pixel-space operations. We address these challenges through a two-phase training approach. The first phase employs instruction tuning on synthesized reasoning traces to familiarize the model with the novel visual operations. Following this, a reinforcement learning (RL) phase leverages a curiosity-driven reward scheme to balance exploration between pixel-space reasoning and textual reasoning. With these visual operations, VLMs can interact with complex visual inputs, such as information-rich images or videos to proactively gather necessary information. We demonstrate that this approach significantly improves VLM performance across diverse visual reasoning benchmarks. Our 7B model, \model, achieves 84\% on V* bench, 74\% on TallyQA-Complex, and 84\% on InfographicsVQA, marking the highest accuracy achieved by any open-source model to date. These results highlight the importance of pixel-space reasoning and the effectiveness of our framework.