OViP: Online Vision-Language Preference Learning for VLM Hallucination
作者: Shujun Liu, Siyuan Wang, Zejun Li, Jianxiang Wang, Cheng Zeng, Zhongyu Wei
分类: cs.CV, cs.CL
发布日期: 2025-05-21 (更新: 2025-09-28)
🔗 代码/项目: GITHUB
💡 一句话要点
提出OViP在线视觉-语言偏好学习框架,解决VLM幻觉问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉语言模型 幻觉抑制 在线学习 对比学习 扩散模型
📋 核心要点
- 现有VLM幻觉抑制方法依赖预定义或随机负样本,无法有效反映模型真实错误,训练效率受限。
- OViP框架通过分析模型自身幻觉输出,动态构建对比训练数据,实时生成相关性更高的监督信号。
- 实验表明,OViP在抑制幻觉的同时,保留了VLM的多模态能力,并显著提升了训练效率。
📝 摘要(中文)
大型视觉-语言模型(LVLMs)容易产生幻觉,生成的内容经常与视觉输入不一致。虽然最近基于训练的方法旨在缓解幻觉,但它们通常依赖于预定义的或随机编辑的负样本,这些样本不能反映实际的模型错误,从而限制了训练效果。本文提出了一种在线视觉-语言偏好学习(OViP)框架,该框架基于模型自身的幻觉输出动态构建对比训练数据。通过识别采样响应对之间的语义差异,并使用扩散模型合成负样本图像,OViP实时生成更相关的监督信号。这种由失败驱动的训练能够自适应地对齐文本和视觉偏好。此外,我们改进了现有的评估协议,以更好地捕捉幻觉抑制和表达能力之间的权衡。在幻觉和通用基准上的实验表明,OViP不仅减少了幻觉,同时保留了核心多模态能力,而且还大大提高了训练效率。
🔬 方法详解
问题定义:大型视觉语言模型(VLM)在生成内容时容易产生幻觉,即生成与视觉输入不符的信息。现有的缓解幻觉的方法通常依赖于预定义的或随机编辑的负样本,这些样本并不能准确反映模型实际产生的错误,导致训练效率低下,难以有效抑制幻觉。
核心思路:OViP的核心思路是利用模型自身产生的幻觉作为负样本,进行在线对比学习。通过分析模型生成的不同响应之间的语义差异,并结合扩散模型生成相应的负样本图像,从而为模型提供更具针对性的监督信号。这种“失败驱动”的训练方式能够使模型自适应地学习视觉和语言之间的正确对齐关系。
技术框架:OViP框架主要包含以下几个阶段:1) 响应采样:给定一个视觉输入,模型生成多个不同的文本响应。2) 语义差异识别:分析这些响应之间的语义差异,找出可能存在幻觉的响应。3) 负样本合成:利用扩散模型,根据语义差异合成相应的负样本图像,这些图像与存在幻觉的响应不一致。4) 对比学习:使用原始图像、幻觉响应和负样本图像构建对比学习损失,训练模型抑制幻觉。
关键创新:OViP的关键创新在于其在线生成负样本的方式。与传统的预定义或随机负样本相比,OViP能够根据模型自身的错误动态生成更具针对性的负样本,从而提高训练效率和幻觉抑制效果。此外,OViP还改进了评估协议,更好地衡量幻觉抑制和表达能力之间的平衡。
关键设计:OViP使用对比学习损失来训练模型,损失函数的设计旨在拉近原始图像和正确响应之间的距离,同时推远原始图像和幻觉响应以及负样本图像之间的距离。扩散模型用于生成负样本图像,其生成过程受到语义差异的引导,确保生成的负样本与幻觉响应具有相关性。具体的参数设置和网络结构细节未在摘要中详细说明,需要参考论文全文。
🖼️ 关键图片


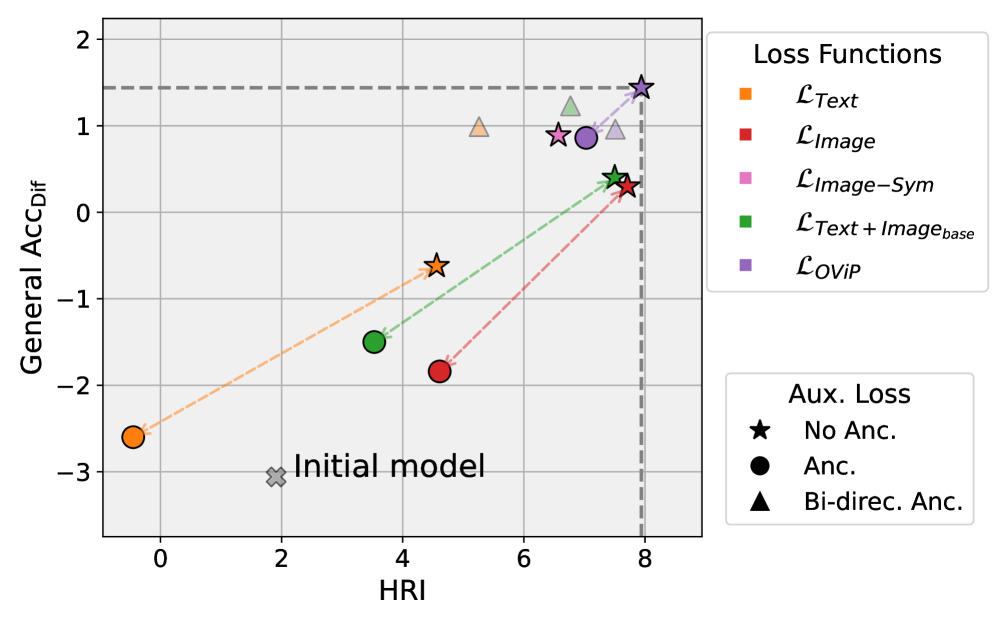
📊 实验亮点
实验结果表明,OViP在抑制VLM幻觉方面取得了显著效果,同时保留了模型的多模态能力。具体性能数据和对比基线未在摘要中给出,但强调了OViP在训练效率方面的提升。该方法在幻觉抑制和通用基准测试中均表现出色,表明其具有良好的泛化能力。
🎯 应用场景
OViP框架可应用于各种需要视觉-语言对齐的场景,例如图像描述生成、视觉问答、多模态对话等。通过有效抑制VLM的幻觉,可以提高这些应用的可信度和实用性,尤其是在医疗、金融等对准确性要求高的领域具有重要价值。未来,该方法可以进一步扩展到其他多模态任务,提升模型的整体性能。
📄 摘要(原文)
Large vision-language models (LVLMs) remain vulnerable to hallucination, often generating content misaligned with visual inputs. Although recent training-based approaches aim to mitigate hallucination, they typically rely on predefined or randomly edited negative samples that do not reflect actual model errors, thus limiting training efficacy. In this work, we propose an Online Vision-language Preference Learning (OViP) framework that dynamically constructs contrastive training data based on the model's own hallucinated outputs. By identifying semantic differences between sampled response pairs and synthesizing negative images using a diffusion model, OViP generates more relevant supervision signals in real time. This failure-driven training enables adaptive alignment of both textual and visual preferences. Moreover, we refine existing evaluation protocols to better capture the trade-off between hallucination suppression and expressiveness. Experiments on hallucination and general benchmarks demonstrate that OViP not only reduces hallucinations while preserving core multi-modal capabilities, but also substantially improves training efficiency. Code is available at https://github.com/lsjlsj35/Online-Vision-Language-Preference-Learning-for-VLM-Hallucination.