Highlighting What Matters: Promptable Embeddings for Attribute-Focused Image Retrieval
作者: Siting Li, Xiang Gao, Simon Shaolei Du
分类: cs.CV, cs.CL, cs.LG
发布日期: 2025-05-21 (更新: 2025-10-14)
备注: NeurIPS 2025; 27 pages, 6 figures
💡 一句话要点
提出可Prompt的图像嵌入方法,用于属性聚焦的图像检索。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像检索 多模态学习 属性聚焦 可Prompt嵌入 大语言模型
📋 核心要点
- 现有图像检索器在处理属性聚焦查询时表现不佳,因为其图像嵌入侧重于全局语义,忽略了关键属性细节。
- 论文提出利用多模态大语言模型生成可Prompt的图像嵌入,通过prompt突出查询相关的图像属性,提升检索性能。
- 实验表明,该方法在COCO-Facet基准上显著提升了属性聚焦图像检索的性能,并提出了两种加速策略以增强实际应用性。
📝 摘要(中文)
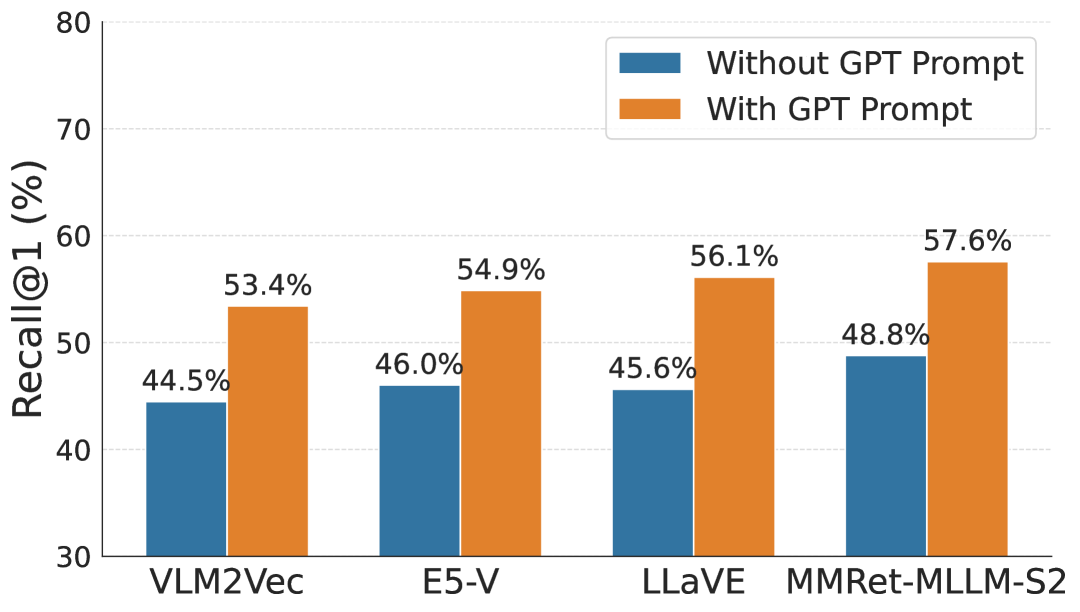
图像检索任务中,并非所有视觉信息都同等重要,特定任务往往关注某些关键属性。为了评估现有检索器处理属性聚焦查询的能力,我们构建了COCO-Facet基准,包含9112个关于COCO图像不同属性的查询。实验表明,广泛使用的CLIP类检索器性能较差且不平衡,可能是因为其图像嵌入侧重于全局语义和主体,忽略了其他细节。即使是基于多模态大语言模型(MLLM)的更强大的检索器,也存在此局限。因此,我们提出使用由这些多模态检索器支持的可Prompt图像嵌入,通过突出所需属性来提升性能。我们的pipeline可泛化到不同查询类型、图像池和基础检索器架构。为了增强实际应用性,我们提供了两种加速策略:预处理可Prompt嵌入和使用线性近似。前者在prompt预定义时,Recall@5提升15%,后者在推理时prompt可用时,提升8%。
🔬 方法详解
问题定义:现有图像检索方法,特别是基于CLIP的模型,在处理需要关注特定图像属性的检索任务时表现不佳。这些模型生成的图像嵌入往往侧重于全局语义信息,而忽略了局部或细粒度的属性特征,导致无法准确检索到包含目标属性的图像。即使是更强大的基于多模态大语言模型的检索器,也难以克服这一局限性。
核心思路:论文的核心思路是利用多模态大语言模型(MLLM)的强大能力,通过prompt引导图像嵌入的生成过程,使其更加关注与查询相关的图像属性。具体来说,通过向MLLM输入包含目标属性信息的prompt,生成针对该属性优化的图像嵌入,从而提高检索的准确性。
技术框架:该方法的核心流程如下:1) 使用多模态大语言模型作为基础检索器。2) 根据查询生成相应的prompt,prompt包含需要关注的图像属性信息。3) 将图像和prompt输入到MLLM中,生成可prompt的图像嵌入。4) 使用生成的图像嵌入进行图像检索,计算图像嵌入与文本查询嵌入之间的相似度,并根据相似度排序检索结果。
关键创新:该方法最重要的创新点在于提出了可prompt的图像嵌入,它能够根据不同的查询动态调整图像嵌入的关注点,使其更加关注与查询相关的属性信息。这与传统的图像嵌入方法不同,后者通常生成静态的、全局的图像表示,无法灵活适应不同的检索需求。
关键设计:为了提高实际应用性,论文提出了两种加速策略:1) 预处理可prompt嵌入:对于预定义的prompt,可以预先计算好对应的图像嵌入,从而减少推理时的计算量。2) 使用线性近似:利用线性模型近似MLLM的嵌入生成过程,从而降低计算复杂度,提高推理速度。具体参数设置和损失函数等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
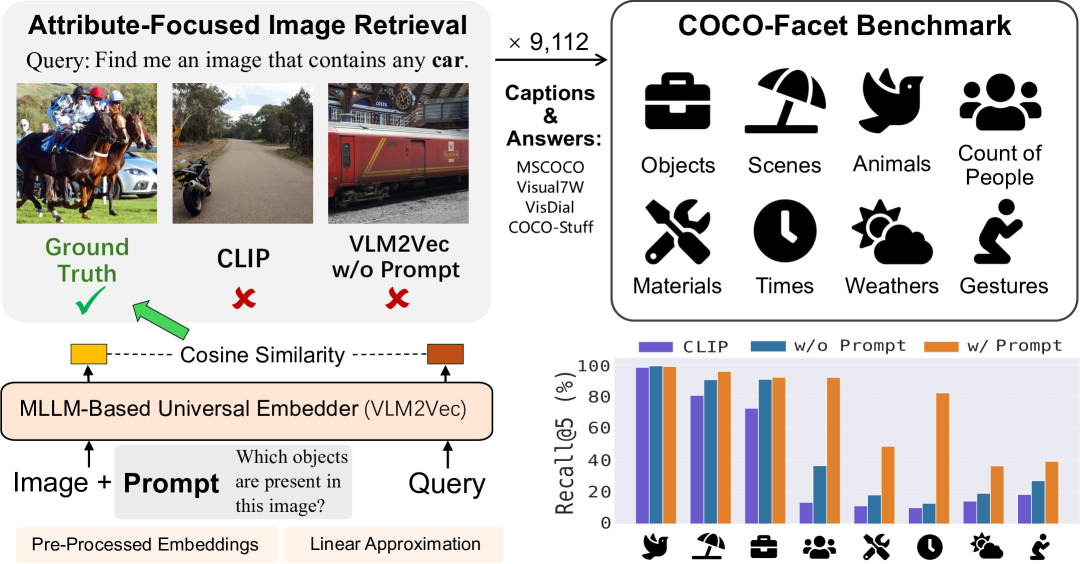

📊 实验亮点
实验结果表明,提出的可Prompt图像嵌入方法在COCO-Facet基准上显著提升了属性聚焦图像检索的性能。通过预处理promptable embeddings,Recall@5提升了15%。使用线性近似方法,在推理时prompt可用时,Recall@5提升了8%。这些结果验证了该方法的有效性和实用性。
🎯 应用场景
该研究成果可应用于电商、搜索引擎、智能安防等领域。例如,在电商领域,用户可以通过指定商品的特定属性(如颜色、材质)来搜索商品;在智能安防领域,可以通过指定嫌疑人的特定特征(如衣着、发型)来检索监控录像。该方法能够提高图像检索的准确性和效率,具有重要的实际应用价值。
📄 摘要(原文)
While an image is worth more than a thousand words, only a few provide crucial information for a given task and thus should be focused on. In light of this, ideal text-to-image (T2I) retrievers should prioritize specific visual attributes relevant to queries. To evaluate current retrievers on handling attribute-focused queries, we build COCO-Facet, a COCO-based benchmark with 9,112 queries about diverse attributes of interest. We find that CLIP-like retrievers, which are widely adopted due to their efficiency and zero-shot ability, have poor and imbalanced performance, possibly because their image embeddings focus on global semantics and subjects while leaving out other details. Notably, we reveal that even recent Multimodal Large Language Model (MLLM)-based, stronger retrievers with a larger output dimension struggle with this limitation. Hence, we hypothesize that retrieving with general image embeddings is suboptimal for performing such queries. As a solution, we propose to use promptable image embeddings enabled by these multimodal retrievers, which boost performance by highlighting required attributes. Our pipeline for deriving such embeddings generalizes across query types, image pools, and base retriever architectures. To enhance real-world applicability, we offer two acceleration strategies: Pre-processing promptable embeddings and using linear approximations. We show that the former yields a 15% improvement in Recall@5 when prompts are predefined, while the latter achieves an 8% improvement when prompts are only available during inference.