How Do Large Vision-Language Models See Text in Image? Unveiling the Distinctive Role of OCR Heads
作者: Ingeol Baek, Hwan Chang, Sunghyun Ryu, Hwanhee Lee
分类: cs.CV
发布日期: 2025-05-21 (更新: 2025-09-30)
备注: EMNLP 2025 Oral
💡 一句话要点
揭示LVLM中OCR Head的作用:分析其如何识别图像中的文本
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型视觉语言模型 光学字符识别 OCR Head 可解释性 图像文本理解
📋 核心要点
- 现有LVLM在可解释性方面存在不足,尤其是在理解图像中的文本信息方面。
- 该论文通过识别LVLM中负责识别图像文本的OCR Head来解决上述问题。
- 实验表明,OCR Head与传统检索Head性质不同,且重新分配sink-token值能提升性能。
📝 摘要(中文)
大型视觉语言模型(LVLM)取得了显著进展,但其可解释性以及如何定位和解释图像中的文本信息方面仍存在差距。本文旨在探索LVLM,以识别负责识别图像中文字的特定head,称之为光学字符识别Head(OCR Head)。研究发现:(1)激活数量更多:与之前的检索head不同,大量head被激活以提取图像中的文本信息。(2)性质独特:OCR head的性质与一般检索head显著不同,在特征上表现出较低的相似性。(3)静态激活:这些head的激活频率与其OCR得分密切相关。通过将思维链(CoT)应用于OCR和传统检索head以及屏蔽这些head,验证了研究结果。此外,重新分配OCR head内的sink-token值可以提高性能。这些见解加深了对LVLM在处理图像中嵌入文本信息时所采用的内部机制的理解。
🔬 方法详解
问题定义:现有的大型视觉语言模型(LVLM)在处理图像中的文本信息时,其内部机制尚不明确。具体而言,哪些网络层或head负责提取和理解图像中的文本,以及它们的工作方式,仍然是一个黑盒。现有方法缺乏对LVLM如何利用光学字符识别(OCR)能力的深入理解,阻碍了模型性能的进一步提升和可解释性的增强。
核心思路:该论文的核心思路是通过识别LVLM中专门负责处理图像文本的“OCR Head”,来揭示模型如何理解图像中的文本信息。作者假设,如果LVLM能够有效地识别图像中的文本,那么必然存在一些特定的网络层或head专门负责这项任务。通过分析这些head的激活模式、特征以及与其他head的差异,可以深入了解LVLM的OCR机制。
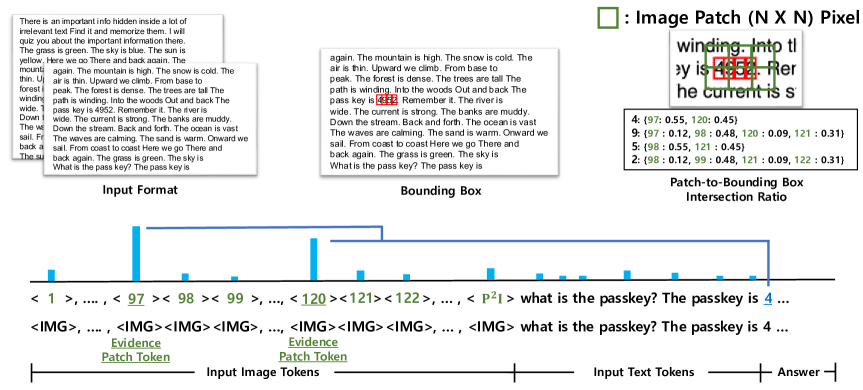
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择多个LVLM模型进行分析。2) 设计实验来识别潜在的OCR Head,例如通过分析head的激活模式和OCR得分之间的关系。3) 对识别出的OCR Head进行深入分析,包括与其他head的特征相似度比较、激活频率分析等。4) 通过下游任务验证OCR Head的重要性,例如通过CoT推理和head屏蔽实验。5) 探索优化OCR Head的方法,例如重新分配sink-token值。
关键创新:该论文的关键创新在于首次明确提出了“OCR Head”的概念,并提供了一种识别和分析LVLM中OCR Head的方法。与以往关注整个模型或特定任务的研究不同,该论文聚焦于LVLM中专门负责处理图像文本的特定head,从而能够更深入地理解模型的OCR机制。此外,通过重新分配sink-token值来优化OCR Head的性能,也为提升LVLM的OCR能力提供了一种新的思路。
关键设计:在识别OCR Head时,作者采用了多种指标,包括head的激活频率、OCR得分以及与其他head的特征相似度。通过综合这些指标,可以更准确地识别出负责处理图像文本的head。在下游任务验证中,作者使用了CoT推理和head屏蔽实验,来评估OCR Head对模型性能的影响。在优化OCR Head时,作者采用了重新分配sink-token值的策略,通过调整不同token的重要性来提升OCR Head的性能。具体的参数设置和网络结构细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片

📊 实验亮点
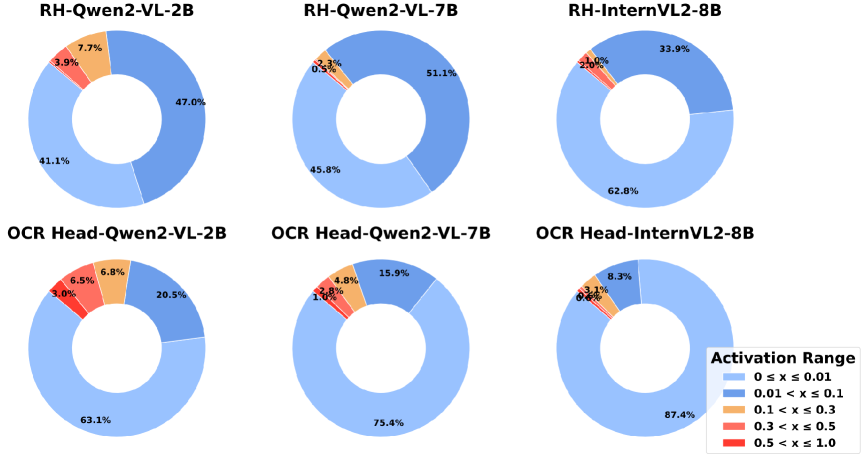
该研究发现,LVLM中存在专门负责处理图像文本的OCR Head,其激活数量更多,性质独特,且激活频率与OCR得分密切相关。通过重新分配OCR Head内的sink-token值,可以提高模型在下游任务中的性能。具体的性能提升幅度未知,需要在论文中查找。
🎯 应用场景
该研究的成果可应用于提升LVLM在各种视觉任务中的性能,例如图像描述、视觉问答和文档理解。通过更好地理解和利用LVLM的OCR能力,可以提高模型在处理包含文本信息的图像时的准确性和效率。此外,该研究还可以促进LVLM的可解释性研究,帮助人们更好地理解模型的内部工作机制,并为未来的模型设计提供指导。
📄 摘要(原文)
Despite significant advancements in Large Vision Language Models (LVLMs), a gap remains, particularly regarding their interpretability and how they locate and interpret textual information within images. In this paper, we explore various LVLMs to identify the specific heads responsible for recognizing text from images, which we term the Optical Character Recognition Head (OCR Head). Our findings regarding these heads are as follows: (1) Less Sparse: Unlike previous retrieval heads, a large number of heads are activated to extract textual information from images. (2) Qualitatively Distinct: OCR heads possess properties that differ significantly from general retrieval heads, exhibiting low similarity in their characteristics. (3) Statically Activated: The frequency of activation for these heads closely aligns with their OCR scores. We validate our findings in downstream tasks by applying Chain-of-Thought (CoT) to both OCR and conventional retrieval heads and by masking these heads. We also demonstrate that redistributing sink-token values within the OCR heads improves performance. These insights provide a deeper understanding of the internal mechanisms LVLMs employ in processing embedded textual information in images.