MMaDA: Multimodal Large Diffusion Language Models
作者: Ling Yang, Ye Tian, Bowen Li, Xinchen Zhang, Ke Shen, Yunhai Tong, Mengdi Wang
分类: cs.CV
发布日期: 2025-05-21 (更新: 2025-09-25)
备注: NeurIPS 2025. Project: https://github.com/Gen-Verse/MMaDA
🔗 代码/项目: GITHUB
💡 一句话要点
MMaDA:多模态大型扩散语言模型,统一架构实现跨领域卓越性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 扩散模型 链式思考 强化学习 统一架构 文本推理 图像生成
📋 核心要点
- 现有方法在处理多模态任务时,通常需要针对不同模态设计特定组件,导致模型复杂且难以泛化。
- MMaDA采用统一的扩散架构和模态无关设计,通过混合CoT微调和UniGRPO强化学习,实现跨模态的知识迁移和性能提升。
- 实验表明,MMaDA在文本推理、多模态理解和文本到图像生成等任务上均超越了现有先进模型,展现了强大的泛化能力。
📝 摘要(中文)
本文提出了一种新型的多模态扩散基础模型MMaDA,旨在文本推理、多模态理解和文本到图像生成等不同领域实现卓越性能。该方法有三个关键创新:(i) MMaDA采用统一的扩散架构,具有共享的概率公式和模态无关的设计,无需模态特定的组件,确保不同数据类型的无缝集成和处理。(ii) 实施混合长链式思考(CoT)微调策略,跨模态管理统一的CoT格式。通过对齐文本和视觉领域的推理过程,该策略促进了最终强化学习(RL)阶段的冷启动训练,从而从一开始就增强了模型处理复杂任务的能力。(iii) 提出了UniGRPO,一种专门为扩散基础模型量身定制的统一的基于策略梯度的RL算法。利用多样化的奖励建模,UniGRPO统一了推理和生成任务的后训练,确保了一致的性能改进。实验结果表明,MMaDA-8B作为统一的多模态基础模型表现出强大的泛化能力。它在文本推理方面超越了LLaMA-3-7B和Qwen2-7B等强大模型,在多模态理解方面优于Show-o和SEED-X,在文本到图像生成方面优于SDXL和Janus。这些成就突显了MMaDA在统一扩散架构中弥合预训练和后训练之间差距的有效性,为未来的研究和开发提供了一个全面的框架。
🔬 方法详解
问题定义:现有的大型多模态模型通常依赖于模态特定的组件,导致模型架构复杂,难以训练和泛化。此外,不同模态之间的推理过程缺乏有效对齐,限制了模型在复杂多模态任务中的表现。因此,如何设计一个统一的、模态无关的架构,并有效对齐不同模态的推理过程,是本文要解决的关键问题。
核心思路:MMaDA的核心思路是采用统一的扩散架构,并结合混合长链式思考(CoT)微调和统一的基于策略梯度的强化学习(UniGRPO),从而实现跨模态的知识迁移和性能提升。通过统一的架构,模型可以无缝处理不同模态的数据,而无需模态特定的组件。CoT微调则用于对齐不同模态的推理过程,UniGRPO则用于优化模型的整体性能。
技术框架:MMaDA的整体框架包括三个主要部分:(1) 统一的扩散架构,用于处理不同模态的数据;(2) 混合长链式思考(CoT)微调策略,用于对齐不同模态的推理过程;(3) 统一的基于策略梯度的强化学习(UniGRPO),用于优化模型的整体性能。模型首先通过预训练学习通用的语言和视觉知识,然后通过CoT微调对齐不同模态的推理过程,最后通过UniGRPO优化模型的整体性能。
关键创新:MMaDA的关键创新在于三个方面:(1) 统一的扩散架构,消除了对模态特定组件的需求;(2) 混合长链式思考(CoT)微调策略,有效对齐了不同模态的推理过程;(3) 统一的基于策略梯度的强化学习(UniGRPO),实现了推理和生成任务的统一后训练。与现有方法相比,MMaDA更加简洁、高效,并且具有更强的泛化能力。
关键设计:在统一的扩散架构中,模型采用共享的概率公式和模态无关的设计,确保不同数据类型的无缝集成和处理。混合CoT微调策略通过管理跨模态的统一CoT格式,对齐文本和视觉领域的推理过程。UniGRPO利用多样化的奖励建模,统一了推理和生成任务的后训练,确保了一致的性能改进。具体的参数设置和网络结构等技术细节在论文中有详细描述。
🖼️ 关键图片
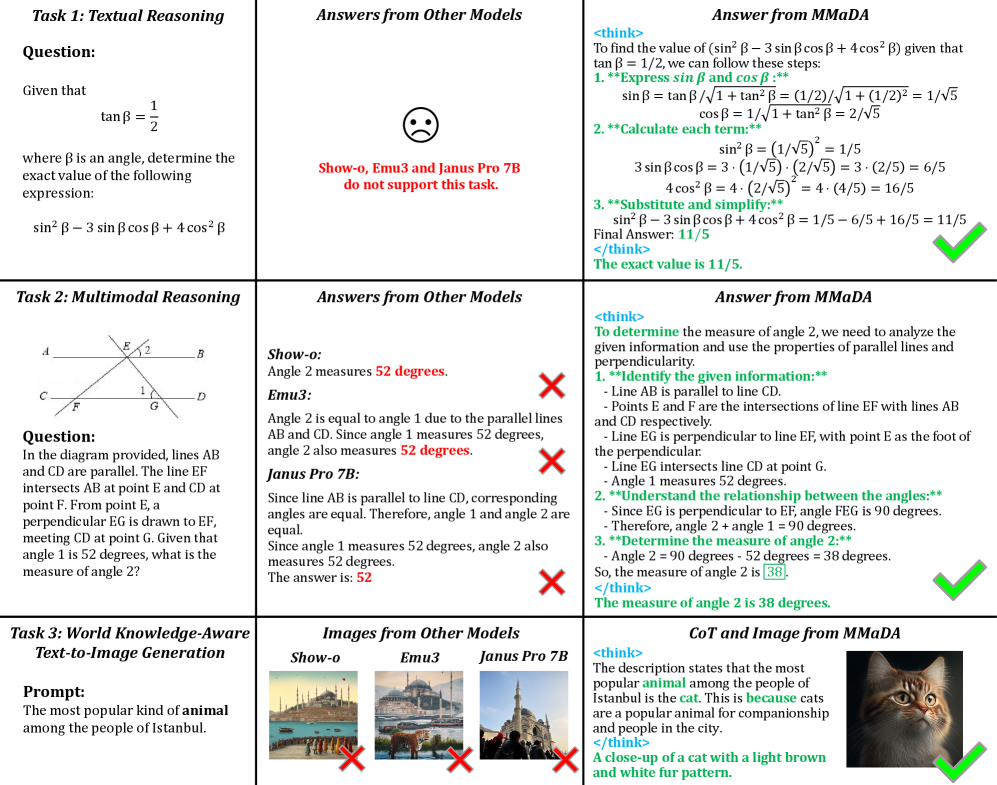
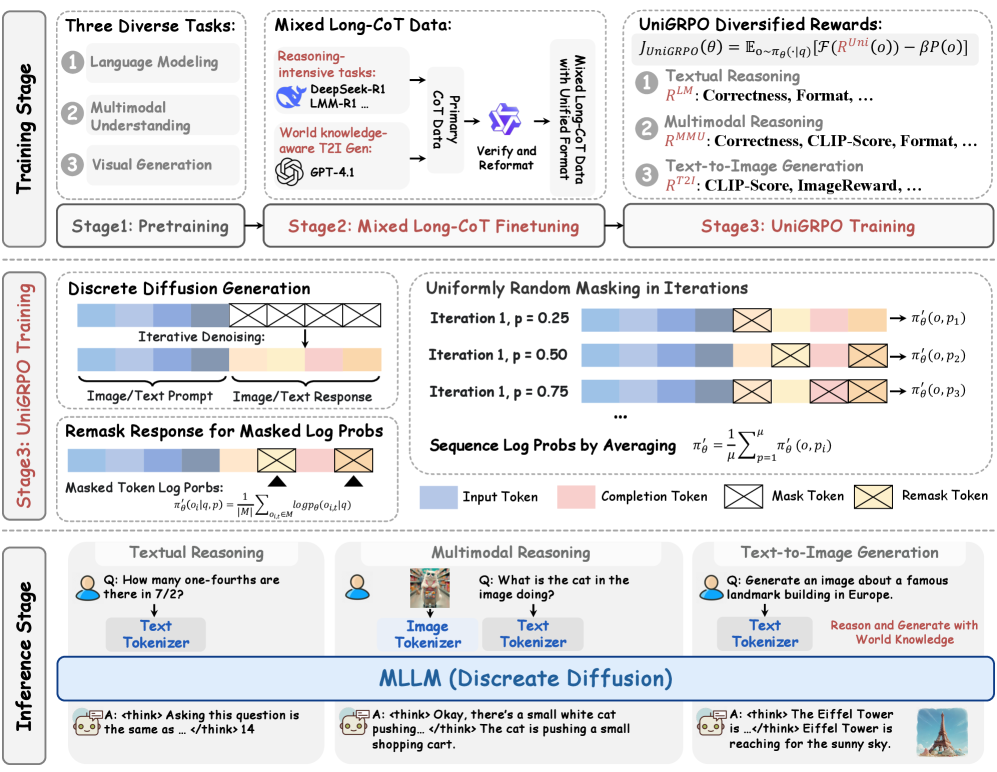

📊 实验亮点
MMaDA-8B在多个任务上取得了显著的性能提升。在文本推理方面,它超越了LLaMA-3-7B和Qwen2-7B等强大模型;在多模态理解方面,它优于Show-o和SEED-X;在文本到图像生成方面,它超越了SDXL和Janus。这些结果表明,MMaDA作为统一的多模态基础模型,具有强大的泛化能力。
🎯 应用场景
MMaDA具有广泛的应用前景,可应用于智能问答、图像描述、视觉推理、文本生成等领域。该模型能够理解和生成多种模态的数据,从而实现更智能、更自然的人机交互。此外,MMaDA还可以用于开发各种创新应用,例如智能教育、智能医疗和智能客服等。
📄 摘要(原文)
We introduce MMaDA, a novel class of multimodal diffusion foundation models designed to achieve superior performance across diverse domains such as textual reasoning, multimodal understanding, and text-to-image generation. The approach is distinguished by three key innovations: (i) MMaDA adopts a unified diffusion architecture with a shared probabilistic formulation and a modality-agnostic design, eliminating the need for modality-specific components. This architecture ensures seamless integration and processing across different data types. (ii) We implement a mixed long chain-of-thought (CoT) fine-tuning strategy that curates a unified CoT format across modalities. By aligning reasoning processes between textual and visual domains, this strategy facilitates cold-start training for the final reinforcement learning (RL) stage, thereby enhancing the model's ability to handle complex tasks from the outset. (iii) We propose UniGRPO, a unified policy-gradient-based RL algorithm specifically tailored for diffusion foundation models. Utilizing diversified reward modeling, UniGRPO unifies post-training across both reasoning and generation tasks, ensuring consistent performance improvements. Experimental results demonstrate that MMaDA-8B exhibits strong generalization capabilities as a unified multimodal foundation model. It surpasses powerful models like LLaMA-3-7B and Qwen2-7B in textual reasoning, outperforms Show-o and SEED-X in multimodal understanding, and excels over SDXL and Janus in text-to-image generation. These achievements highlight MMaDA's effectiveness in bridging the gap between pretraining and post-training within unified diffusion architectures, providing a comprehensive framework for future research and development. We open-source our code and trained models at: https://github.com/Gen-Verse/MMaDA