Seeing Through Deception: Uncovering Misleading Creator Intent in Multimodal News with Vision-Language Models
作者: Jiaying Wu, Fanxiao Li, Zihang Fu, Min-Yen Kan, Bryan Hooi
分类: cs.CV, cs.CL, cs.MM
发布日期: 2025-05-21 (更新: 2025-09-30)
💡 一句话要点
提出DeceptionDecoded基准,揭示视觉-语言模型在多模态新闻中理解创作者欺骗意图的局限性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态不实信息检测 视觉-语言模型 欺骗意图识别 基准数据集 意图推理
📋 核心要点
- 现有方法在多模态不实信息检测中,难以有效识别创作者的欺骗意图,导致模型依赖表面线索。
- 论文提出意图引导的模拟框架,构建大规模基准数据集DeceptionDecoded,包含误导性和非误导性案例。
- 实验表明,现有视觉-语言模型在DeceptionDecoded上表现不佳,无法有效进行意图推理,依赖浅层线索。
📝 摘要(中文)
不实信息的影响不仅源于事实错误,还来自创作者刻意嵌入的误导性叙述。理解这种创作者意图对于多模态不实信息检测(MMD)和有效的信息治理至关重要。为此,我们引入了DeceptionDecoded,一个大规模基准,包含12000个基于可信参考文章的图像-标题对,它使用意图引导的模拟框架创建,该框架模拟了新闻创作者的期望影响和执行计划。该数据集捕获了误导性和非误导性案例,涵盖了跨视觉和文本模态的操纵,并支持三个以意图为中心的任务:(1)误导意图检测,(2)误导来源归属,和(3)创作者意愿推断。我们评估了14个最先进的视觉-语言模型(VLMs),发现它们难以进行意图推理,通常依赖于表面对齐、文体润色或启发式真实性信号等浅层线索。这些结果突出了当前VLMs的局限性,并将DeceptionDecoded定位为开发意图感知模型的基础,这些模型超越了MMD中的浅层线索。
🔬 方法详解
问题定义:现有方法在多模态不实信息检测中,难以准确识别创作者的欺骗意图。模型容易受到表面对齐、文体润色等浅层线索的干扰,无法真正理解新闻背后的动机和目的。这导致模型在识别复杂、隐蔽的误导信息时表现不佳。
核心思路:论文的核心思路是通过构建一个大规模、高质量的基准数据集,来挑战和提升视觉-语言模型在理解创作者意图方面的能力。该数据集的设计模拟了新闻创作者的意图,包括他们希望产生的影响和具体的执行计划,从而使模型能够学习区分误导性和非误导性的案例。
技术框架:DeceptionDecoded数据集的构建流程包含以下几个主要阶段:首先,收集可信的参考文章作为基础事实;然后,使用意图引导的模拟框架,生成相应的图像-标题对,其中一部分图像-标题对被设计为具有误导性意图;最后,对生成的数据进行标注,包括误导意图的类型、来源以及创作者的意愿。该数据集支持三个任务:误导意图检测、误导来源归属和创作者意愿推断。
关键创新:该论文的关键创新在于提出了一个意图引导的模拟框架,用于生成具有欺骗意图的多模态数据。与以往侧重于事实准确性的数据集不同,DeceptionDecoded关注创作者的意图,这使得它能够更真实地反映现实世界中不实信息的复杂性。此外,该数据集还提供了一系列以意图为中心的任务,为研究人员提供了一个评估和改进模型意图理解能力的平台。
关键设计:在数据集构建过程中,作者精心设计了模拟框架,以确保生成的数据具有多样性和挑战性。例如,他们考虑了不同类型的误导意图,包括夸大、歪曲和隐瞒等。此外,他们还使用了不同的图像和标题生成技术,以增加数据的多样性。在评估模型性能时,作者使用了多种指标,包括准确率、精确率和召回率等,以全面评估模型在不同任务上的表现。
🖼️ 关键图片


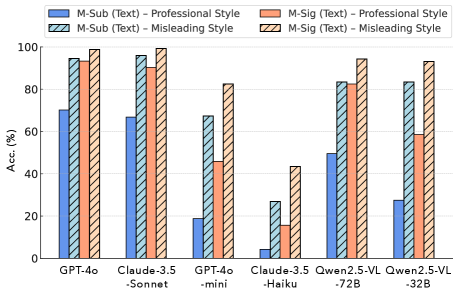
📊 实验亮点
实验结果表明,14个最先进的视觉-语言模型在DeceptionDecoded数据集上表现不佳,表明现有模型在理解创作者意图方面存在显著局限性。例如,模型在误导意图检测任务上的准确率远低于人类水平,并且容易受到表面线索的干扰。这些结果突出了开发意图感知模型的重要性。
🎯 应用场景
该研究成果可应用于多模态不实信息检测、社交媒体内容审核、新闻可信度评估等领域。通过提升模型对创作者意图的理解能力,可以更有效地识别和过滤误导性信息,维护健康的在线信息生态,减少不实信息对社会造成的负面影响。
📄 摘要(原文)
The impact of misinformation arises not only from factual inaccuracies but also from the misleading narratives that creators deliberately embed. Interpreting such creator intent is therefore essential for multimodal misinformation detection (MMD) and effective information governance. To this end, we introduce DeceptionDecoded, a large-scale benchmark of 12,000 image-caption pairs grounded in trustworthy reference articles, created using an intent-guided simulation framework that models both the desired influence and the execution plan of news creators. The dataset captures both misleading and non-misleading cases, spanning manipulations across visual and textual modalities, and supports three intent-centric tasks: (1) misleading intent detection, (2) misleading source attribution, and (3) creator desire inference. We evaluate 14 state-of-the-art vision-language models (VLMs) and find that they struggle with intent reasoning, often relying on shallow cues such as surface-level alignment, stylistic polish, or heuristic authenticity signals. These results highlight the limitations of current VLMs and position DeceptionDecoded as a foundation for developing intent-aware models that go beyond shallow cues in MMD.