Adaptive Chain-of-Focus Reasoning via Dynamic Visual Search and Zooming for Efficient VLMs
作者: Xintong Zhang, Zhi Gao, Bofei Zhang, Pengxiang Li, Xiaowen Zhang, Yang Liu, Tao Yuan, Yuwei Wu, Yunde Jia, Song-Chun Zhu, Qing Li
分类: cs.CV
发布日期: 2025-05-21 (更新: 2025-12-05)
备注: https://github.com/xtong-zhang/Chain-of-Focus
💡 一句话要点
提出自适应聚焦链推理(CoF),通过动态视觉搜索和缩放提升视觉语言模型效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 多模态推理 聚焦链推理 自适应聚焦 强化学习
📋 核心要点
- 现有视觉语言模型在多模态推理能力上存在不足,无法有效聚焦关键图像区域。
- 提出聚焦链(CoF)方法,通过动态视觉搜索和缩放,使模型自适应地关注关键区域。
- 在V*基准测试中,CoF方法在多种分辨率下超越现有VLM 5%,验证了其有效性。
📝 摘要(中文)
视觉语言模型(VLMs)在各种计算机视觉任务中取得了显著的性能。然而,现有模型中多模态推理能力尚未得到充分探索。本文提出了一种聚焦链(CoF)方法,该方法允许VLM基于获得的视觉线索和给定的问题,对关键图像区域进行自适应聚焦和缩放,从而实现高效的多模态推理。为了实现这种CoF能力,我们提出了一个两阶段训练流程,包括监督微调(SFT)和强化学习(RL)。在SFT阶段,我们构建了MM-CoF数据集,该数据集包含3K个样本,这些样本源自一个视觉代理,该代理旨在自适应地识别关键区域,以解决具有不同图像分辨率和问题的视觉任务。我们使用MM-CoF来微调Qwen2.5-VL模型以进行冷启动。在RL阶段,我们利用结果准确性和格式作为奖励来更新Qwen2.5-VL模型,从而进一步完善模型的搜索和推理策略,而无需人工先验。我们的模型在多个基准测试中取得了显著的改进。在需要强大视觉推理能力的V*基准测试中,我们的模型在224到4K的8种图像分辨率下,比现有VLM高出5%,证明了所提出的CoF方法的有效性,并有助于VLM在实际应用中更高效的部署。
🔬 方法详解
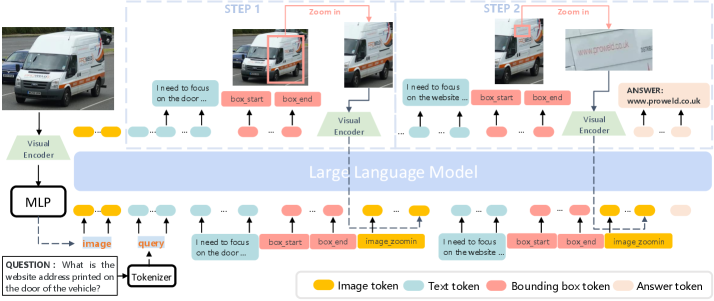
问题定义:现有视觉语言模型在处理复杂视觉推理任务时,无法有效地聚焦于图像中的关键区域,导致推理效率低下和性能瓶颈。模型通常需要处理整个图像,而忽略了图像中与问题相关的局部信息。
核心思路:本文的核心思路是让模型具备自适应地聚焦和缩放图像关键区域的能力,类似于人类在解决视觉问题时的视觉搜索过程。通过逐步聚焦关键区域,模型可以更有效地提取相关信息,从而提高推理效率和准确性。
技术框架:该方法采用两阶段训练流程:首先是监督微调(SFT),然后是强化学习(RL)。在SFT阶段,使用MM-CoF数据集对Qwen2.5-VL模型进行冷启动,该数据集包含视觉代理生成的聚焦区域数据。在RL阶段,使用结果准确性和格式作为奖励,进一步优化模型的搜索和推理策略。整体框架包括视觉搜索模块、区域缩放模块和推理模块,这些模块协同工作,实现自适应聚焦推理。
关键创新:该方法最重要的创新点在于提出了自适应聚焦链推理(CoF)的概念,并将其应用于视觉语言模型。与传统的全局图像处理方法不同,CoF方法允许模型动态地选择和处理图像中的关键区域,从而提高了推理效率和准确性。此外,使用强化学习进一步优化搜索策略,避免了人工先验的限制。
关键设计:MM-CoF数据集的设计至关重要,它包含了不同分辨率图像和问题的聚焦区域标注,用于监督微调。强化学习阶段的奖励函数设计也十分关键,它需要能够有效地引导模型学习到最佳的搜索策略。具体参数设置和网络结构细节在论文中可能有所描述,但摘要中未明确提及。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该模型在V*基准测试中,在224到4K的8种图像分辨率下,比现有VLM高出5%。这一显著提升证明了CoF方法的有效性,尤其是在需要强大视觉推理能力的场景下。该结果表明,通过自适应聚焦关键区域,可以显著提高视觉语言模型的性能。
🎯 应用场景
该研究成果可广泛应用于需要高效视觉推理的场景,例如智能客服、自动驾驶、医疗影像分析等。通过自适应聚焦关键区域,模型可以更快速、准确地理解图像内容,从而提高相关应用的性能和用户体验。未来,该方法有望进一步推广到其他多模态任务中,例如视频理解、机器人导航等。
📄 摘要(原文)
Vision language models (VLMs) have achieved impressive performance across a variety of computer vision tasks. However, the multimodal reasoning capability has not been fully explored in existing models. In this paper, we propose a Chain-of-Focus (CoF) method that allows VLMs to perform adaptive focusing and zooming in on key image regions based on obtained visual cues and the given questions, achieving efficient multimodal reasoning. To enable this CoF capability, we present a two-stage training pipeline, including supervised fine-tuning (SFT) and reinforcement learning (RL). In the SFT stage, we construct the MM-CoF dataset, comprising 3K samples derived from a visual agent designed to adaptively identify key regions to solve visual tasks with different image resolutions and questions. We use MM-CoF to fine-tune the Qwen2.5-VL model for cold start. In the RL stage, we leverage the outcome accuracies and formats as rewards to update the Qwen2.5-VL model, enabling further refining the search and reasoning strategy of models without human priors. Our model achieves significant improvements on multiple benchmarks. On the V* benchmark that requires strong visual reasoning capability, our model outperforms existing VLMs by 5% among 8 image resolutions ranging from 224 to 4K, demonstrating the effectiveness of the proposed CoF method and facilitating the more efficient deployment of VLMs in practical applications.