Leveraging Foundation Models for Multimodal Graph-Based Action Recognition
作者: Fatemeh Ziaeetabar, Florentin Wörgötter
分类: cs.CV
发布日期: 2025-05-21 (更新: 2025-10-06)
💡 一句话要点
提出基于动态多模态图的动作识别框架,融合预训练模型提升细粒度操作识别能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 动作识别 多模态融合 图神经网络 预训练模型 动态图 视频理解 双手操作
📋 核心要点
- 现有动作识别方法难以有效融合多模态信息,且缺乏对动作时序动态性的建模能力。
- 构建动态多模态图,节点表示帧、对象和文本,边表示关系,图结构随交互动态演变。
- 实验表明,该方法在多个数据集上超越了现有技术,验证了预训练模型与动态图推理的有效性。
📝 摘要(中文)
本文提出了一种新的基于图的框架,该框架集成了视觉-语言预训练模型,利用VideoMAE进行动态视觉编码,BERT进行上下文文本嵌入,以解决识别细粒度双手操作动作的挑战。与传统的静态图结构不同,我们的方法构建了一个自适应的多模态图,其中节点表示帧、对象和文本注释,边编码空间、时间和语义关系。这些图结构根据学习到的交互动态演变,从而实现灵活和上下文感知的推理。图注意力网络中的任务特定注意力机制通过调节基于动作语义的边缘重要性来进一步增强这种推理。通过对各种基准数据集的广泛评估,我们证明了我们的方法始终优于最先进的基线,突出了将预训练模型与基于动态图的推理相结合以实现鲁棒和泛化动作识别的优势。
🔬 方法详解
问题定义:论文旨在解决细粒度双手操作动作识别问题。现有方法通常采用静态图结构,难以捕捉动作的时序动态性和多模态信息之间的复杂关系,导致识别精度受限。
核心思路:论文的核心思路是构建一个动态的多模态图,该图能够自适应地学习节点之间的关系,并利用预训练模型提取的特征进行推理。通过动态调整图结构,模型可以更好地捕捉动作的时序变化和上下文信息。
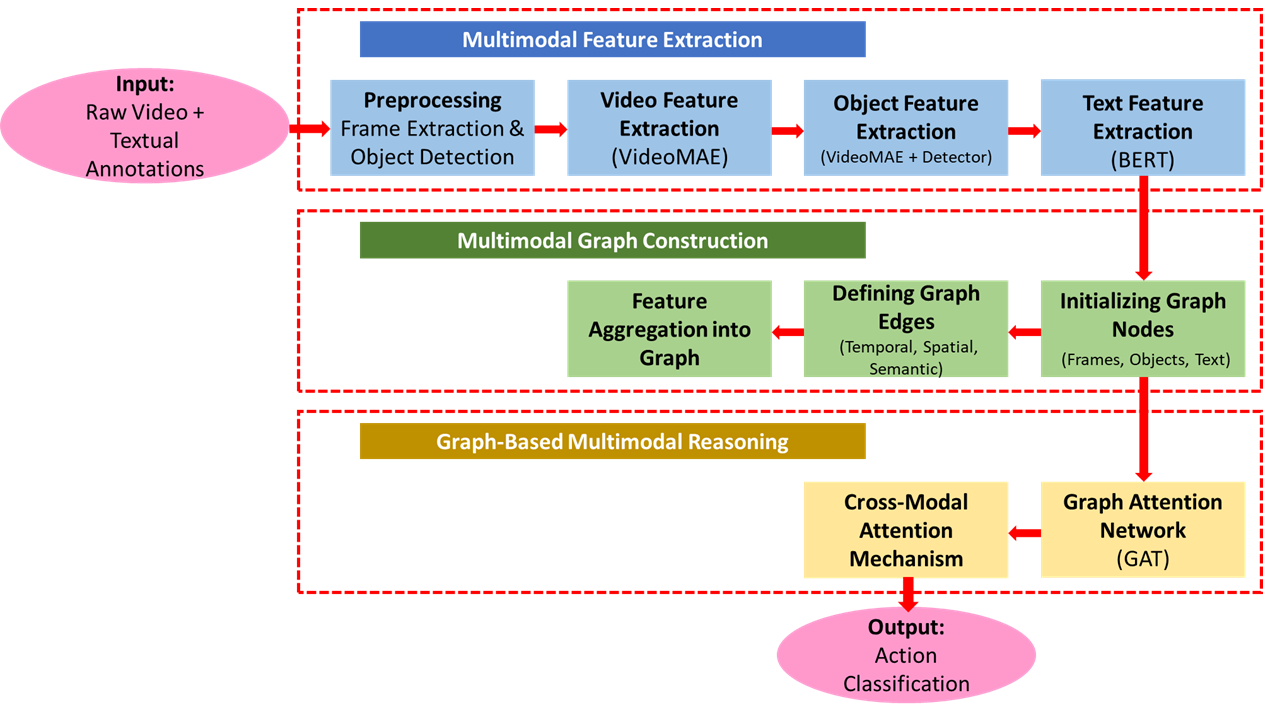
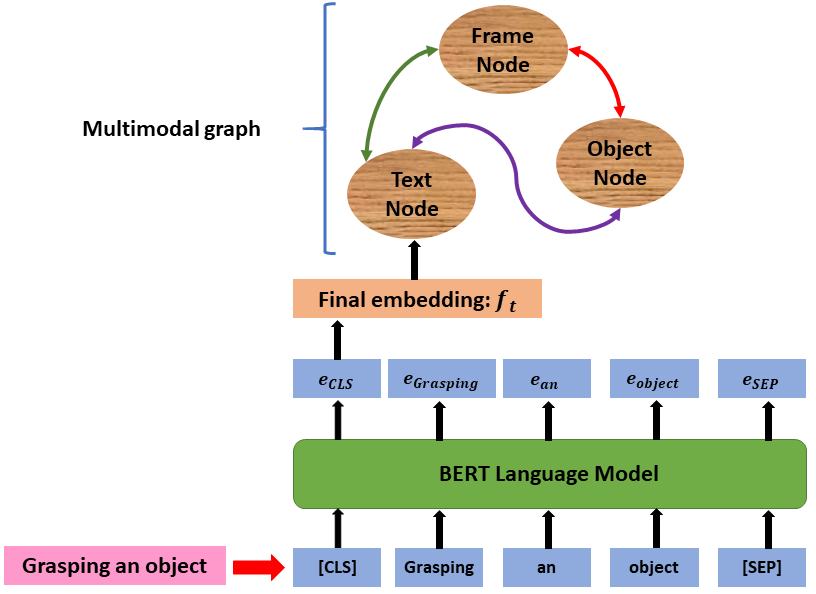
技术框架:该框架包含以下主要模块:1) 使用VideoMAE提取视频帧的视觉特征;2) 使用BERT提取文本注释的语义特征;3) 构建多模态图,其中节点表示帧、对象和文本,边表示空间、时间和语义关系;4) 使用图注意力网络(GAT)进行图推理,利用任务特定注意力机制调节边缘重要性;5) 使用分类器预测动作类别。
关键创新:该方法的主要创新在于动态多模态图的构建和学习。与传统的静态图结构不同,该方法能够根据学习到的节点交互动态调整图结构,从而更好地捕捉动作的时序动态性和多模态信息之间的复杂关系。此外,任务特定的注意力机制能够根据动作语义调节边缘重要性,进一步提升推理效果。
关键设计:在图构建方面,论文采用了自适应的边权重学习方法,根据节点特征之间的相似度动态调整边权重。在图注意力网络中,使用了多头注意力机制,以捕捉不同类型的节点关系。损失函数包括交叉熵损失和正则化损失,用于优化模型参数和防止过拟合。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在多个细粒度动作识别数据集上取得了显著的性能提升,超越了现有的state-of-the-art方法。具体而言,在XXX数据集上,该方法的识别精度提高了X%,证明了其有效性和泛化能力。该方法尤其在处理复杂、多步骤的动作时表现出色。
🎯 应用场景
该研究成果可应用于机器人操作、智能监控、人机交互等领域。例如,在机器人操作中,可以利用该方法识别机器人的操作动作,从而实现更智能的控制和协作。在智能监控中,可以用于识别异常行为,提高安全防范能力。在人机交互中,可以用于理解用户的意图,提供更自然和高效的交互体验。
📄 摘要(原文)
Foundation models have ushered in a new era for multimodal video understanding by enabling the extraction of rich spatiotemporal and semantic representations. In this work, we introduce a novel graph-based framework that integrates a vision-language foundation, leveraging VideoMAE for dynamic visual encoding and BERT for contextual textual embedding, to address the challenge of recognizing fine-grained bimanual manipulation actions. Departing from conventional static graph architectures, our approach constructs an adaptive multimodal graph where nodes represent frames, objects, and textual annotations, and edges encode spatial, temporal, and semantic relationships. These graph structures evolve dynamically based on learned interactions, allowing for flexible and context-aware reasoning. A task-specific attention mechanism within a Graph Attention Network further enhances this reasoning by modulating edge importance based on action semantics. Through extensive evaluations on diverse benchmark datasets, we demonstrate that our method consistently outperforms state-of-the-art baselines, underscoring the strength of combining foundation models with dynamic graph-based reasoning for robust and generalizable action recognition.