AvatarShield: Visual Reinforcement Learning for Human-Centric Synthetic Video Detection
作者: Zhipei Xu, Xuanyu Zhang, Qing Huang, Xing Zhou, Jian Zhang
分类: cs.CV, cs.AI
发布日期: 2025-05-21 (更新: 2025-09-23)
💡 一句话要点
AvatarShield:提出基于视觉强化学习的人体合成视频检测框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 合成视频检测 强化学习 视觉推理 LLM 多模态融合
📋 核心要点
- 现有DeepFake检测方法主要关注面部篡改,忽略了全身合成视频带来的信息安全风险,后者能实现更复杂的交互。
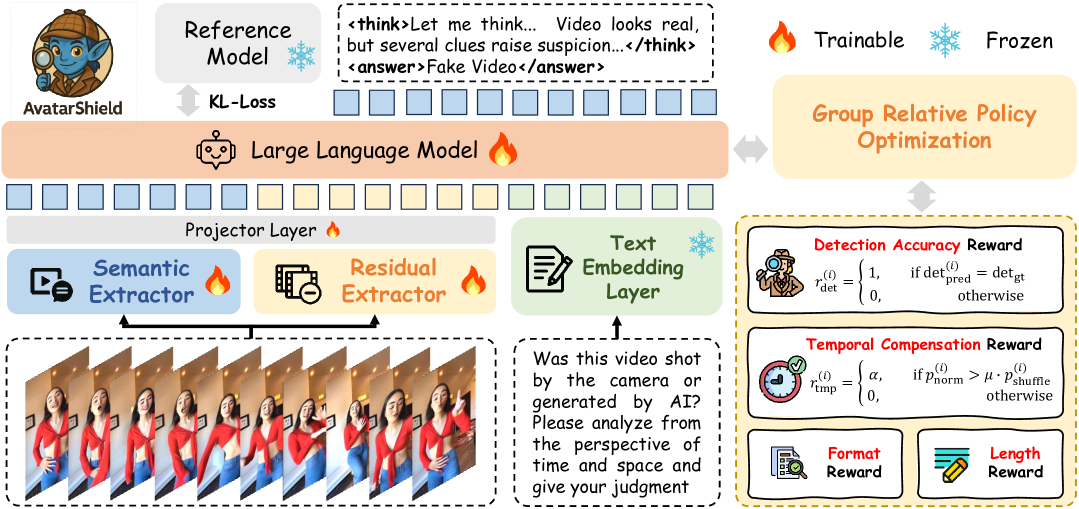
- AvatarShield采用群体相对策略优化,无需密集文本监督,即可训练LLM进行推理,从而检测人体合成视频。
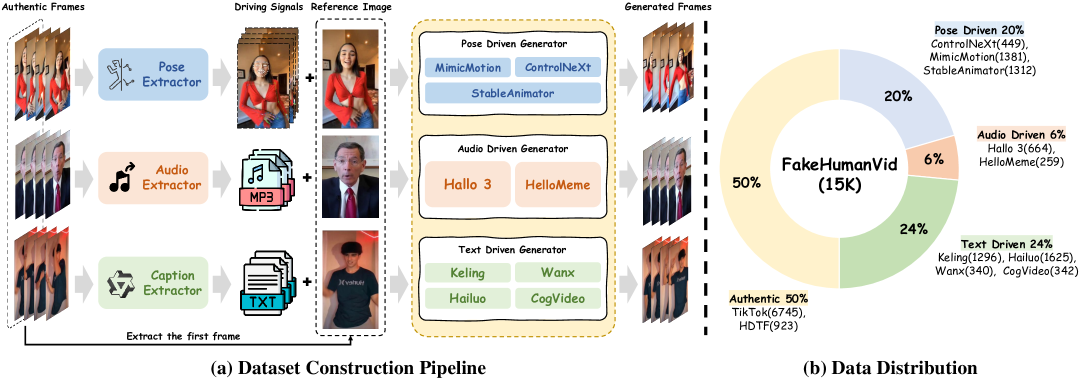
- FakeHumanVid包含15K视频,涵盖多种人体生成方法。实验表明AvatarShield在领域内和跨领域均优于现有方法。
📝 摘要(中文)
人工智能生成内容(AIGC)的最新进展催生了高度逼真的合成视频,尤其是在涉及语音、手势和全身运动的人体场景中,对信息真实性和公众信任构成了严重威胁。与侧重于局部面部操作的DeepFake技术不同,以人为中心的视频生成方法可以合成具有可控运动的整个人体,从而实现与环境、物体甚至其他人的复杂交互。然而,现有的检测方法在很大程度上忽略了这种全身合成内容日益增长的风险。同时,越来越多的研究探索利用LLM进行可解释的伪造检测,旨在用自然语言解释决策。然而,这些方法严重依赖于监督微调,这引入了注释偏差、幻觉监督和泛化能力减弱等限制。为了应对这些挑战,我们提出了AvatarShield,一种新颖的多模态以人为中心的合成视频检测框架,通过采用群体相对策略优化,消除了对密集文本监督的需求,使LLM能够从简单的二元标签中发展推理能力。我们的架构结合了一个用于高级语义不一致性的离散视觉塔和一个用于细粒度伪影分析的残差提取器。我们进一步推出了FakeHumanVid,一个大规模基准,包含来自九种最先进的文本、姿势或音频驱动的人体生成方法的15K真实和合成视频。大量的实验表明,AvatarShield在领域内和跨领域设置中都优于现有方法。
🔬 方法详解
问题定义:当前DeepFake检测技术主要集中在面部操作,而忽略了全身合成视频带来的威胁。这些全身合成视频能够模拟复杂的动作和交互,使得检测更加困难。现有方法依赖于大量标注数据进行监督学习,存在标注偏差和泛化能力不足的问题。
核心思路:AvatarShield的核心思路是利用强化学习,特别是群体相对策略优化(Group Relative Policy Optimization),来训练LLM,使其能够从简单的二元标签(真/假)中学习推理能力,从而避免对密集文本标注的依赖。通过视觉信息和LLM的结合,AvatarShield能够检测视频中的不一致性和伪影,从而判断视频的真伪。
技术框架:AvatarShield框架包含以下主要模块:1) 离散视觉塔(Discrete Vision Tower):用于提取视频中的高级语义信息,例如人物的动作和交互。2) 残差提取器(Residual Extractor):用于分析视频中的细粒度伪影,例如不自然的运动或渲染错误。3) LLM推理模块:利用LLM对提取的视觉信息进行推理,判断视频的真伪。强化学习算法用于训练LLM,使其能够根据视觉信息做出准确的判断。
关键创新:AvatarShield的关键创新在于:1) 采用强化学习训练LLM,无需密集文本监督。2) 结合离散视觉塔和残差提取器,提取视频中的高级语义信息和细粒度伪影。3) 提出了FakeHumanVid数据集,用于评估人体合成视频检测方法的性能。与现有方法相比,AvatarShield能够更好地检测全身合成视频,并且具有更强的泛化能力。
关键设计:AvatarShield的关键设计包括:1) 离散视觉塔采用Transformer结构,用于提取视频中的高级语义信息。2) 残差提取器采用卷积神经网络,用于分析视频中的细粒度伪影。3) 强化学习算法采用群体相对策略优化,用于训练LLM。4) 损失函数包括分类损失和强化学习奖励函数,用于优化模型的性能。
🖼️ 关键图片

📊 实验亮点
AvatarShield在FakeHumanVid数据集上进行了广泛的实验,结果表明其在领域内和跨领域设置中均优于现有方法。具体而言,AvatarShield在跨领域检测任务中取得了显著的性能提升,表明其具有更强的泛化能力。此外,消融实验验证了离散视觉塔和残差提取器对模型性能的贡献。
🎯 应用场景
AvatarShield可应用于社交媒体平台、新闻媒体机构和安全监控系统,用于检测和过滤虚假视频内容,维护信息真实性和公众信任。该技术还有助于打击恶意信息传播和网络欺诈,保护个人和组织的合法权益。未来,AvatarShield可以扩展到其他类型的合成内容检测,例如图像和音频,为构建更安全可靠的网络环境做出贡献。
📄 摘要(原文)
Recent advances in Artificial Intelligence Generated Content have led to highly realistic synthetic videos, particularly in human-centric scenarios involving speech, gestures, and full-body motion, posing serious threats to information authenticity and public trust. Unlike DeepFake techniques that focus on localized facial manipulation, human-centric video generation methods can synthesize entire human bodies with controllable movements, enabling complex interactions with environments, objects, and even other people. However, existing detection methods largely overlook the growing risks posed by such full-body synthetic content. Meanwhile, a growing body of research has explored leveraging LLMs for interpretable fake detection, aiming to explain decisions in natural language. Yet these approaches heavily depend on supervised fine-tuning, which introduces limitations such as annotation bias, hallucinated supervision, and weakened generalization. To address these challenges, we propose AvatarShield, a novel multimodal human-centric synthetic video detection framework that eliminates the need for dense textual supervision by adopting Group Relative Policy Optimization, enabling LLMs to develop reasoning capabilities from simple binary labels. Our architecture combines a discrete vision tower for high-level semantic inconsistencies and a residual extractor for fine-grained artifact analysis. We further introduce FakeHumanVid, a large-scale benchmark containing 15K real and synthetic videos across nine state-of-the-art human generation methods driven by text, pose, or audio. Extensive experiments demonstrate that AvatarShield outperforms existing methods in both in-domain and cross-domain settings.